 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgesi4onnx: A Python package for Selective Inference in Deep Learning Models
Jan 29, 2025In this paper, we introduce si4onnx, a package for performing selective inference on deep learning models. Techniques such as CAM in XAI and reconstruction-based anomaly detection using VAE can be interpreted as methods for identifying significant regions within input images. However, the identified regions may not always carry meaningful significance. Therefore, evaluating the statistical significance of these regions represents a crucial challenge in establishing the reliability of AI systems. si4onnx is a Python package that enables straightforward implementation of hypothesis testing with controlled type I error rates through selective inference. It is compatible with deep learning models constructed using common frameworks such as PyTorch and TensorFlow.
Statistical Test for Generated Hypotheses by Diffusion Models
Feb 19, 2024The enhanced performance of AI has accelerated its integration into scientific research. In particular, the use of generative AI to create scientific hypotheses is promising and is increasingly being applied across various fields. However, when employing AI-generated hypotheses for critical decisions, such as medical diagnoses, verifying their reliability is crucial. In this study, we consider a medical diagnostic task using generated images by diffusion models, and propose a statistical test to quantify its reliability. The basic idea behind the proposed statistical test is to employ a selective inference framework, where we consider a statistical test conditional on the fact that the generated images are produced by a trained diffusion model. Using the proposed method, the statistical reliability of medical image diagnostic results can be quantified in the form of a p-value, allowing for decision-making with a controlled error rate. We show the theoretical validity of the proposed statistical test and its effectiveness through numerical experiments on synthetic and brain image datasets.
Statistical Test for Anomaly Detections by Variational Auto-Encoders
Feb 06, 2024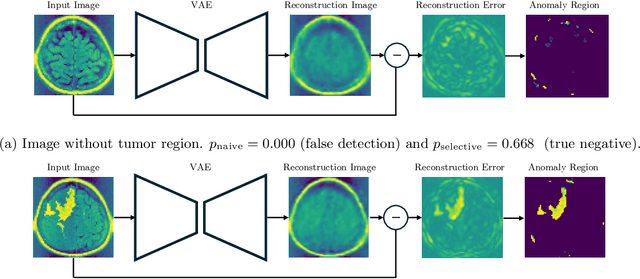
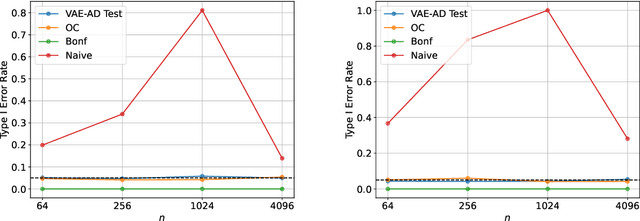
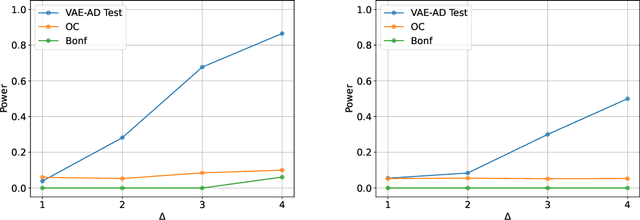
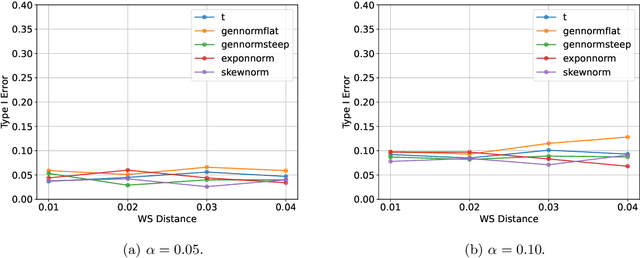
In this study, we consider the reliability assessment of anomaly detection (AD) using Variational Autoencoder (VAE). Over the last decade, VAE-based AD has been actively studied in various perspective, from method development to applied research. However, when the results of ADs are used in high-stakes decision-making, such as in medical diagnosis, it is necessary to ensure the reliability of the detected anomalies. In this study, we propose the VAE-AD Test as a method for quantifying the statistical reliability of VAE-based AD within the framework of statistical testing. Using the VAE-AD Test, the reliability of the anomaly regions detected by a VAE can be quantified in the form of p-values. This means that if an anomaly is declared when the p-value is below a certain threshold, it is possible to control the probability of false detection to a desired level. Since the VAE-AD Test is constructed based on a new statistical inference framework called selective inference, its validity is theoretically guaranteed in finite samples. To demonstrate the validity and effectiveness of the proposed VAE-AD Test, numerical experiments on artificial data and applications to brain image analysis are conducted.
Statistical Test for Attention Map in Vision Transformer
Jan 19, 2024The Vision Transformer (ViT) demonstrates exceptional performance in various computer vision tasks. Attention is crucial for ViT to capture complex wide-ranging relationships among image patches, allowing the model to weigh the importance of image patches and aiding our understanding of the decision-making process. However, when utilizing the attention of ViT as evidence in high-stakes decision-making tasks such as medical diagnostics, a challenge arises due to the potential of attention mechanisms erroneously focusing on irrelevant regions. In this study, we propose a statistical test for ViT's attentions, enabling us to use the attentions as reliable quantitative evidence indicators for ViT's decision-making with a rigorously controlled error rate. Using the framework called selective inference, we quantify the statistical significance of attentions in the form of p-values, which enables the theoretically grounded quantification of the false positive detection probability of attentions. We demonstrate the validity and the effectiveness of the proposed method through numerical experiments and applications to brain image diagnoses.
Selective Inference for Changepoint detection by Recurrent Neural Network
Nov 25, 2023In this study, we investigate the quantification of the statistical reliability of detected change points (CPs) in time series using a Recurrent Neural Network (RNN). Thanks to its flexibility, RNN holds the potential to effectively identify CPs in time series characterized by complex dynamics. However, there is an increased risk of erroneously detecting random noise fluctuations as CPs. The primary goal of this study is to rigorously control the risk of false detections by providing theoretically valid p-values to the CPs detected by RNN. To achieve this, we introduce a novel method based on the framework of Selective Inference (SI). SI enables valid inferences by conditioning on the event of hypothesis selection, thus mitigating selection bias. In this study, we apply SI framework to RNN-based CP detection, where characterizing the complex process of RNN selecting CPs is our main technical challenge. We demonstrate the validity and effectiveness of the proposed method through artificial and real data experiments.
Bounded P-values in Parametric Programming-based Selective Inference
Jul 21, 2023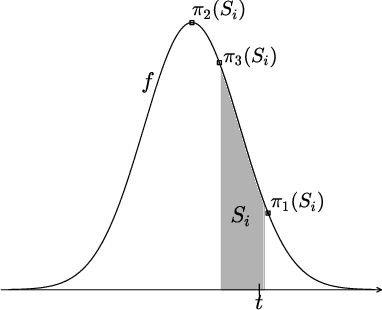
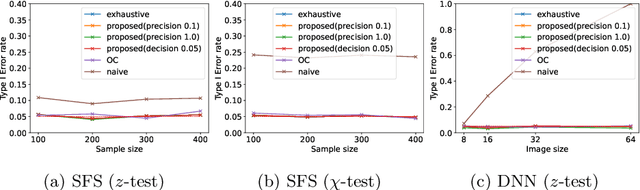
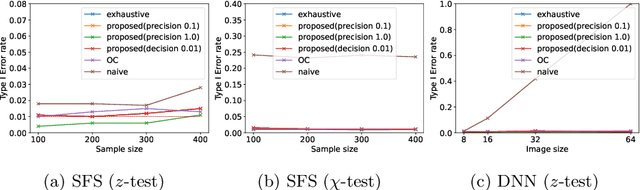
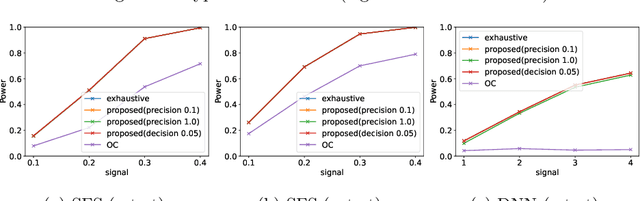
Selective inference (SI) has been actively studied as a promising framework for statistical hypothesis testing for data-driven hypotheses. The basic idea of SI is to make inferences conditional on an event that a hypothesis is selected. In order to perform SI, this event must be characterized in a traceable form. When selection event is too difficult to characterize, additional conditions are introduced for tractability. This additional conditions often causes the loss of power, and this issue is referred to as over-conditioning. Parametric programming-based SI (PP-based SI) has been proposed as one way to address the over-conditioning issue. The main problem of PP-based SI is its high computational cost due to the need to exhaustively explore the data space. In this study, we introduce a procedure to reduce the computational cost while guaranteeing the desired precision, by proposing a method to compute the upper and lower bounds of p-values. We also proposed three types of search strategies that efficiently improve these bounds. We demonstrate the effectiveness of the proposed method in hypothesis testing problems for feature selection in linear models and attention region identification in deep neural networks.
Valid P-Value for Deep Learning-Driven Salient Region
Jan 06, 2023

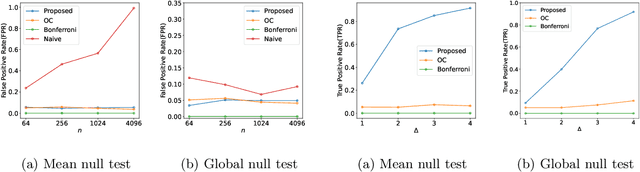

Various saliency map methods have been proposed to interpret and explain predictions of deep learning models. Saliency maps allow us to interpret which parts of the input signals have a strong influence on the prediction results. However, since a saliency map is obtained by complex computations in deep learning models, it is often difficult to know how reliable the saliency map itself is. In this study, we propose a method to quantify the reliability of a salient region in the form of p-values. Our idea is to consider a salient region as a selected hypothesis by the trained deep learning model and employ the selective inference framework. The proposed method can provably control the probability of false positive detections of salient regions. We demonstrate the validity of the proposed method through numerical examples in synthetic and real datasets. Furthermore, we develop a Keras-based framework for conducting the proposed selective inference for a wide class of CNNs without additional implementation cost.