 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBounded P-values in Parametric Programming-based Selective Inference
Paper and Code
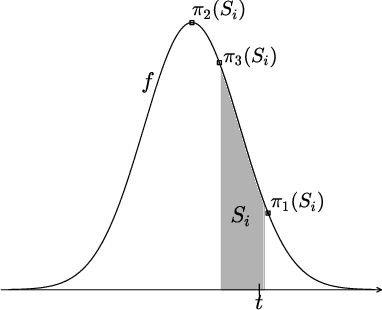
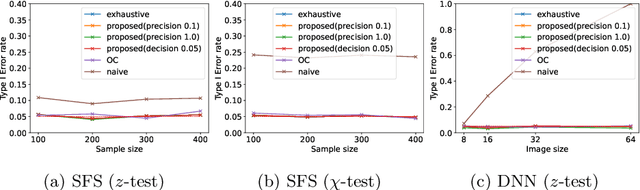
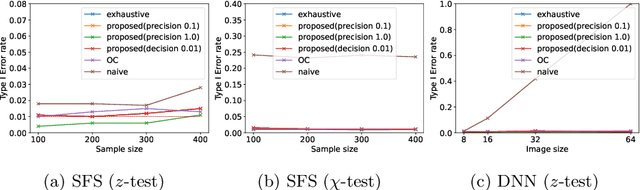
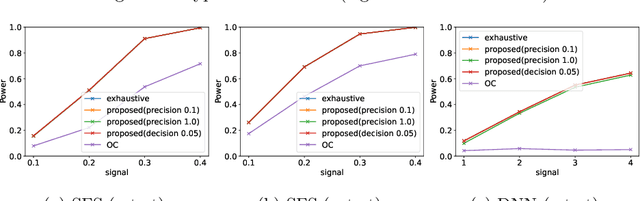
Selective inference (SI) has been actively studied as a promising framework for statistical hypothesis testing for data-driven hypotheses. The basic idea of SI is to make inferences conditional on an event that a hypothesis is selected. In order to perform SI, this event must be characterized in a traceable form. When selection event is too difficult to characterize, additional conditions are introduced for tractability. This additional conditions often causes the loss of power, and this issue is referred to as over-conditioning. Parametric programming-based SI (PP-based SI) has been proposed as one way to address the over-conditioning issue. The main problem of PP-based SI is its high computational cost due to the need to exhaustively explore the data space. In this study, we introduce a procedure to reduce the computational cost while guaranteeing the desired precision, by proposing a method to compute the upper and lower bounds of p-values. We also proposed three types of search strategies that efficiently improve these bounds. We demonstrate the effectiveness of the proposed method in hypothesis testing problems for feature selection in linear models and attention region identification in deep neural networks.