 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Out-of-Memory NMF of Dense and Sparse Data on CPU/GPU Architectures with Automatic Model Selection for Exascale Data
Paper and Code
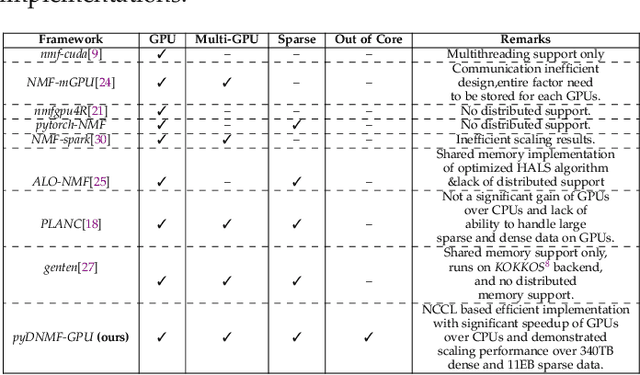
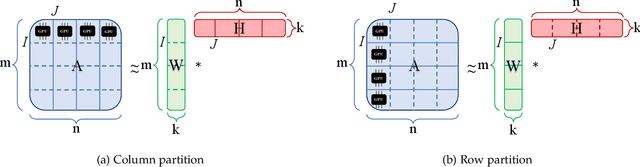
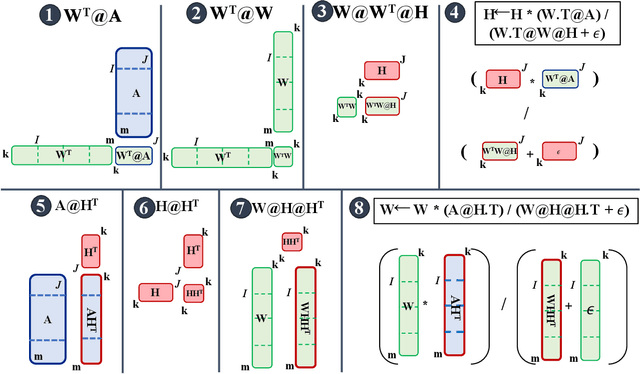
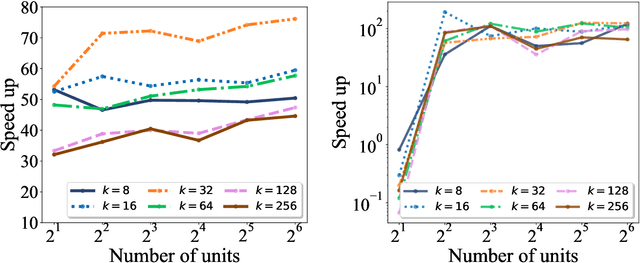
The need for efficient and scalable big-data analytics methods is more essential than ever due to the exploding size and complexity of globally emerging datasets. Nonnegative Matrix Factorization (NMF) is a well-known explainable unsupervised learning method for dimensionality reduction, latent feature extraction, blind source separation, data mining, and machine learning. In this paper, we introduce a new distributed out-of-memory NMF method, named pyDNMF-GPU, designed for modern heterogeneous CPU/GPU architectures that is capable of factoring exascale-sized dense and sparse matrices. Our method reduces the latency associated with local data transfer between the GPU and host using CUDA streams, and reduces the latency associated with collective communications (both intra-node and inter-node) via NCCL primitives. In addition, sparse and dense matrix multiplications are significantly accelerated with GPU cores, resulting in good scalability. We set new benchmarks for the size of the data being analyzed: in experiments, we measure up to 76x improvement on a single GPU over running on a single 18 core CPU and we show good weak scaling on up to 4096 multi-GPU cluster nodes with approximately 25,000 GPUs, when decomposing a dense 340 Terabyte-size matrix and a 11 Exabyte-size sparse matrix of density 10e-6. Finally, we integrate our method with an automatic model selection method. With this integration, we introduce a new tool that is capable of analyzing, compressing, and discovering explainable latent structures in extremely large sparse and dense data.