 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstablishing baselines and introducing TernaryMixOE for fine-grained out-of-distribution detection
Mar 30, 2023



Machine learning models deployed in the open world may encounter observations that they were not trained to recognize, and they risk misclassifying such observations with high confidence. Therefore, it is essential that these models are able to ascertain what is in-distribution (ID) and out-of-distribution (OOD), to avoid this misclassification. In recent years, huge strides have been made in creating models that are robust to this distinction. As a result, the current state-of-the-art has reached near perfect performance on relatively coarse-grained OOD detection tasks, such as distinguishing horses from trucks, while struggling with finer-grained classification, like differentiating models of commercial aircraft. In this paper, we describe a new theoretical framework for understanding fine- and coarse-grained OOD detection, we re-conceptualize fine grained classification into a three part problem, and we propose a new baseline task for OOD models on two fine-grained hierarchical data sets, two new evaluation methods to differentiate fine- and coarse-grained OOD performance, along with a new loss function for models in this task.
Generalized Adversarial Distances to Efficiently Discover Classifier Errors
Feb 25, 2021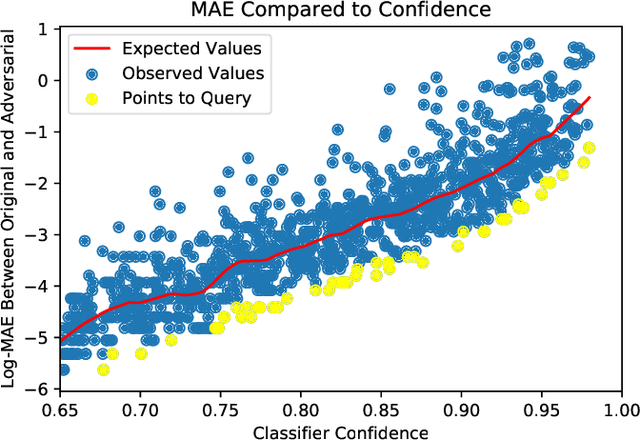
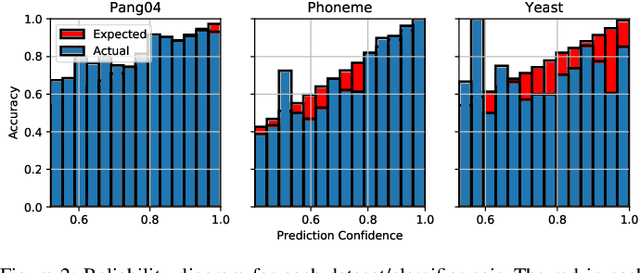
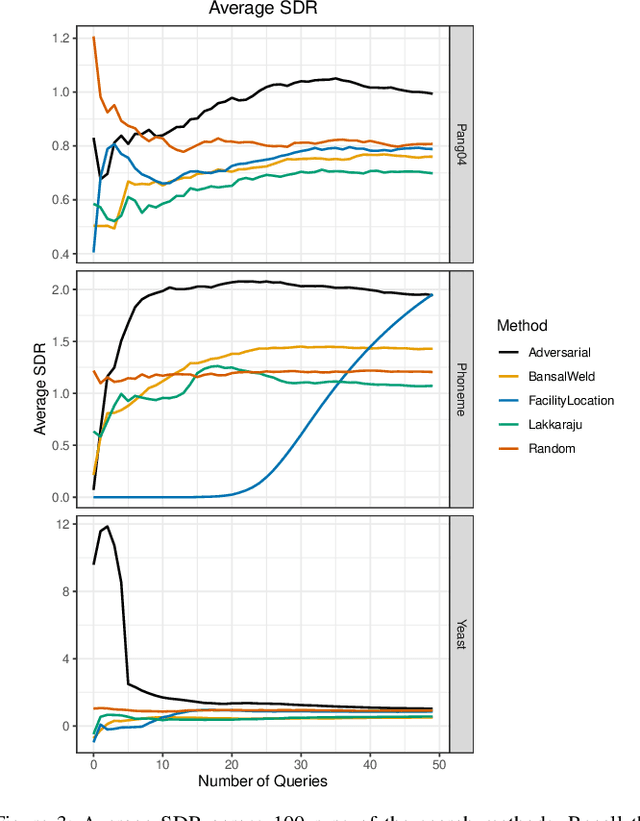
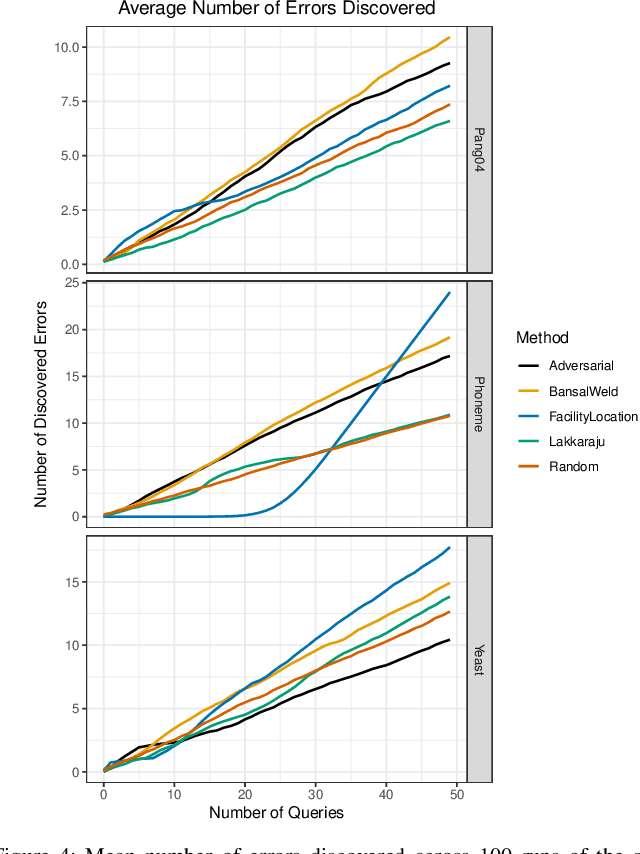
Given a black-box classification model and an unlabeled evaluation dataset from some application domain, efficient strategies need to be developed to evaluate the model. Random sampling allows a user to estimate metrics like accuracy, precision, and recall, but may not provide insight to high-confidence errors. High-confidence errors are rare events for which the model is highly confident in its prediction, but is wrong. Such errors can represent costly mistakes and should be explicitly searched for. In this paper we propose a generalization to the Adversarial Distance search that leverages concepts from adversarial machine learning to identify predictions for which a classifier may be overly confident. These predictions are useful instances to sample when looking for high-confidence errors because they are prone to a higher rate of error than expected. Our generalization allows Adversarial Distance to be applied to any classifier or data domain. Experimental results show that the generalized method finds errors at rates greater than expected given the confidence of the sampled predictions, and outperforms competing methods.
Harnessing Adversarial Distances to Discover High-Confidence Errors
Jun 29, 2020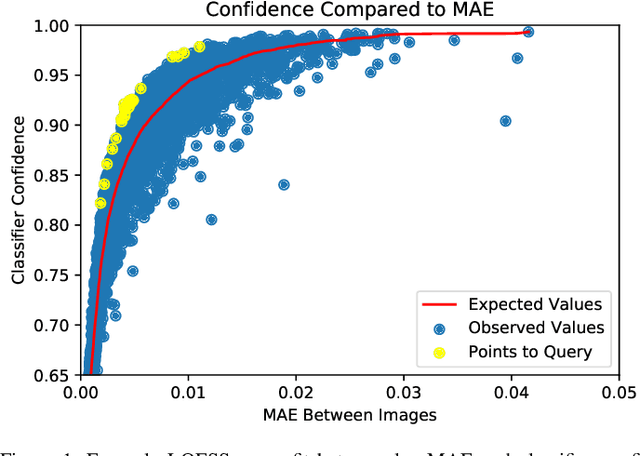
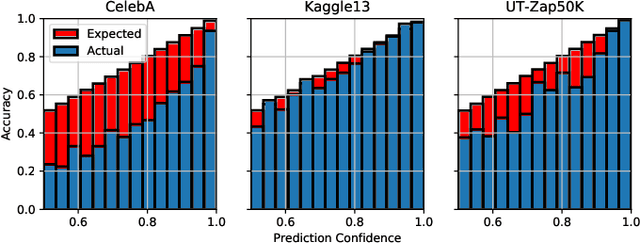
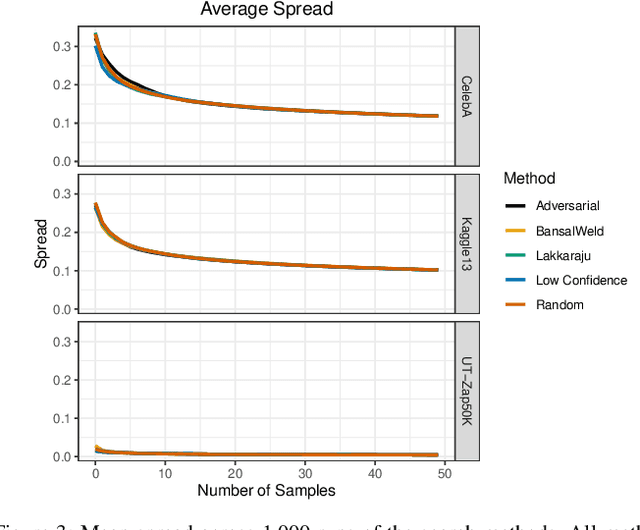
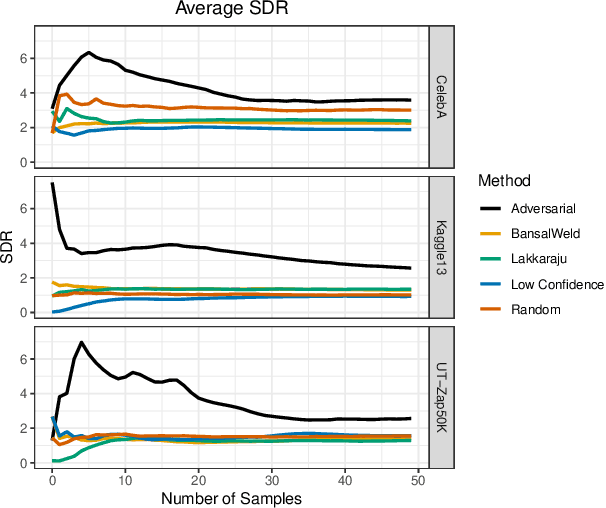
Given a deep neural network image classification model that we treat as a black box, and an unlabeled evaluation dataset, we develop an efficient strategy by which the classifier can be evaluated. Randomly sampling and labeling instances from an unlabeled evaluation dataset allows traditional performance measures like accuracy, precision, and recall to be estimated. However, random sampling may miss rare errors for which the model is highly confident in its prediction, but wrong. These high-confidence errors can represent costly mistakes, and therefore should be explicitly searched for. Past works have developed search techniques to find classification errors above a specified confidence threshold, but ignore the fact that errors should be expected at confidence levels anywhere below 100\%. In this work, we investigate the problem of finding errors at rates greater than expected given model confidence. Additionally, we propose a query-efficient and novel search technique that is guided by adversarial perturbations to find these mistakes in black box models. Through rigorous empirical experimentation, we demonstrate that our Adversarial Distance search discovers high-confidence errors at a rate greater than expected given model confidence.
Facility Locations Utility for Uncovering Classifier Overconfidence
Oct 12, 2018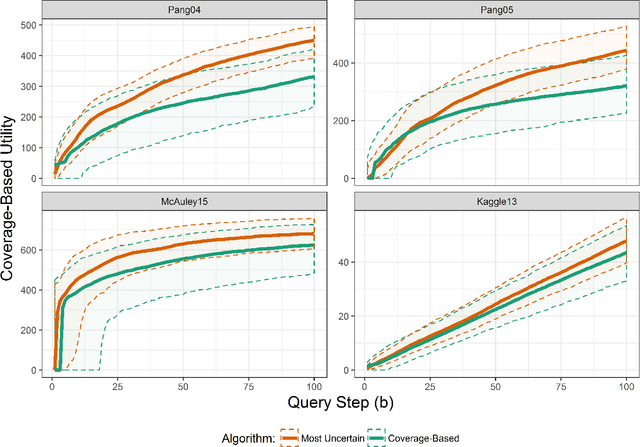
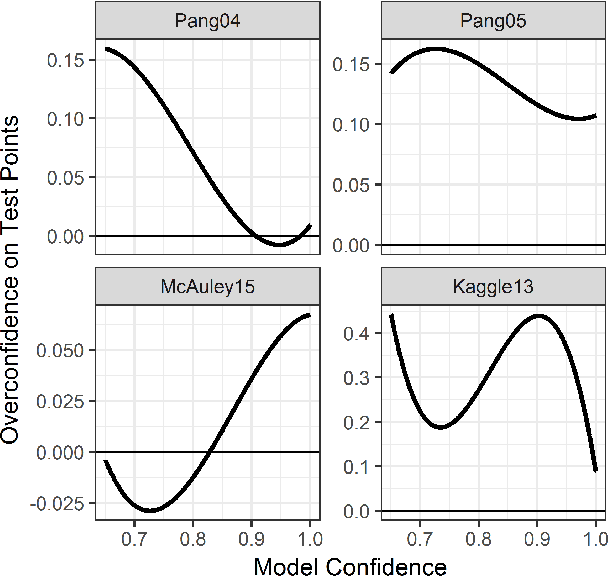
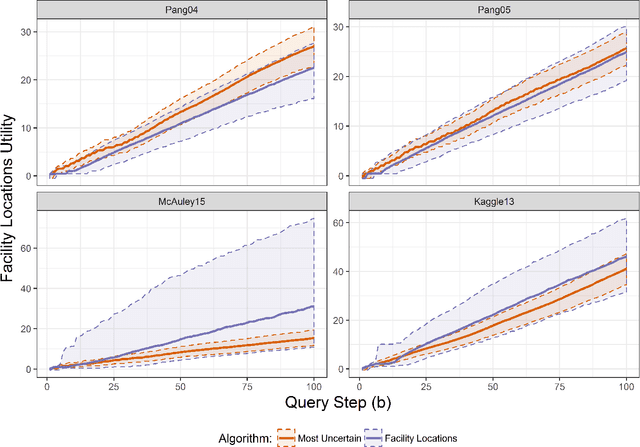
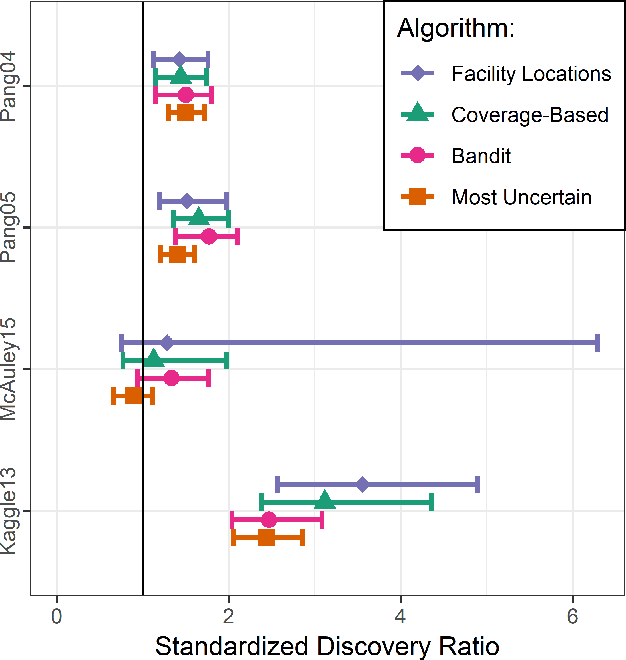
Assessing the predictive accuracy of black box classifiers is challenging in the absence of labeled test datasets. In these scenarios we may need to rely on a human oracle to evaluate individual predictions; presenting the challenge to create query algorithms to guide the search for points that provide the most information about the classifier's predictive characteristics. Previous works have focused on developing utility models and query algorithms for discovering unknown unknowns --- misclassifications with a predictive confidence above some arbitrary threshold. However, if misclassifications occur at the rate reflected by the confidence values, then these search methods reveal nothing more than a proper assessment of predictive certainty. We are unable to properly mitigate the risks associated with model deficiency when the model's confidence in prediction exceeds the actual model accuracy. We propose a facility locations utility model and corresponding greedy query algorithm that instead searches for overconfident unknown unknowns. Through robust empirical experiments we demonstrate that the greedy query algorithm with the facility locations utility model consistently results in oracle queries with superior performance in discovering overconfident unknown unknowns than previous methods.