 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Adversarial Distances to Efficiently Discover Classifier Errors
Feb 25, 2021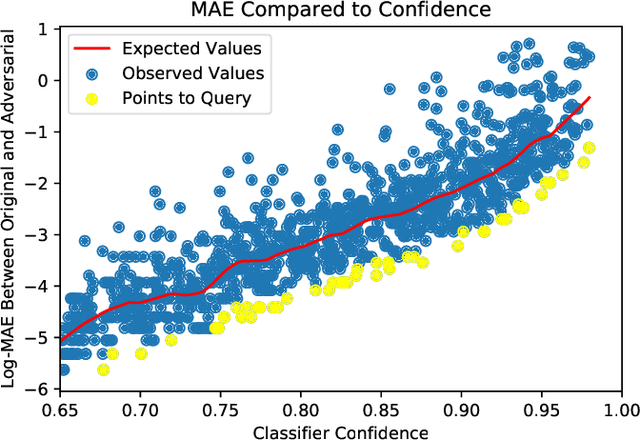
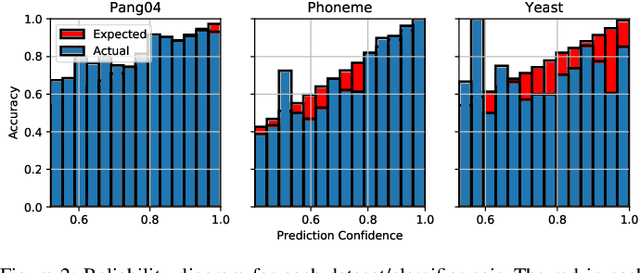
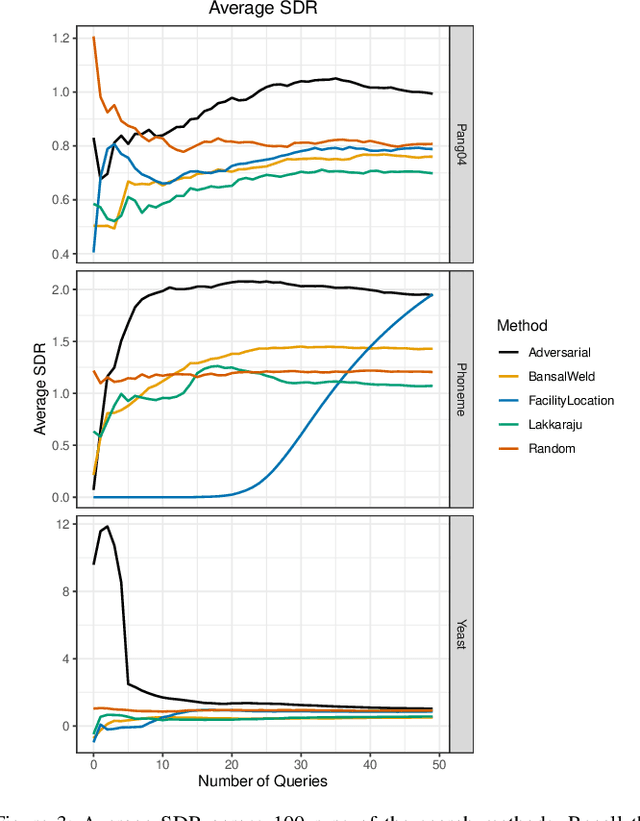
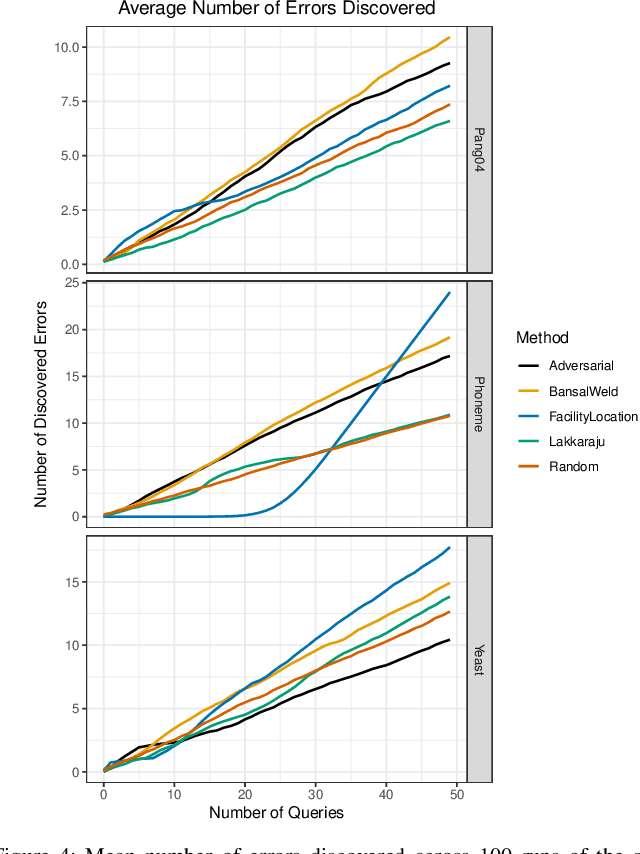
Given a black-box classification model and an unlabeled evaluation dataset from some application domain, efficient strategies need to be developed to evaluate the model. Random sampling allows a user to estimate metrics like accuracy, precision, and recall, but may not provide insight to high-confidence errors. High-confidence errors are rare events for which the model is highly confident in its prediction, but is wrong. Such errors can represent costly mistakes and should be explicitly searched for. In this paper we propose a generalization to the Adversarial Distance search that leverages concepts from adversarial machine learning to identify predictions for which a classifier may be overly confident. These predictions are useful instances to sample when looking for high-confidence errors because they are prone to a higher rate of error than expected. Our generalization allows Adversarial Distance to be applied to any classifier or data domain. Experimental results show that the generalized method finds errors at rates greater than expected given the confidence of the sampled predictions, and outperforms competing methods.