 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentence transition matrix: An efficient approach that preserves sentence semantics
Paper and Code
Jan 16, 2019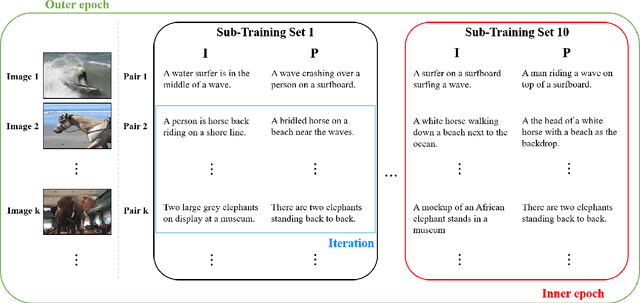
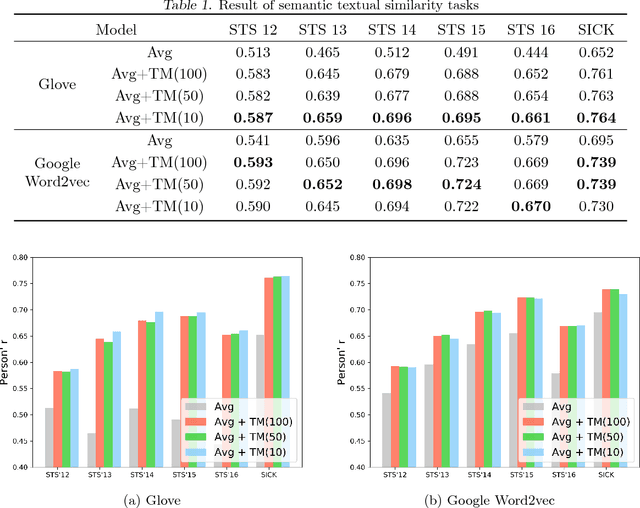
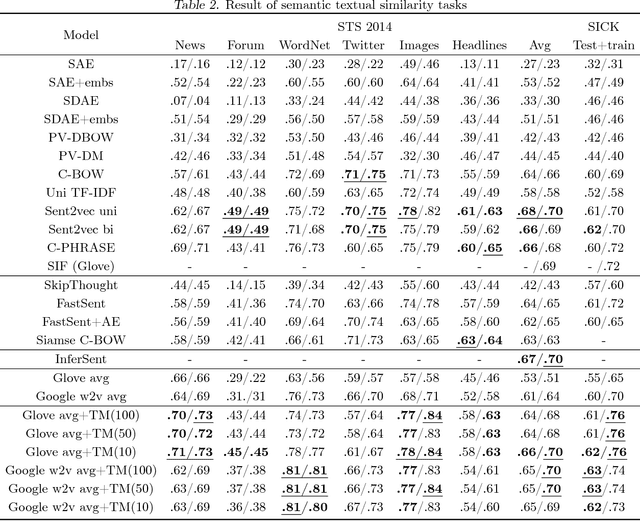
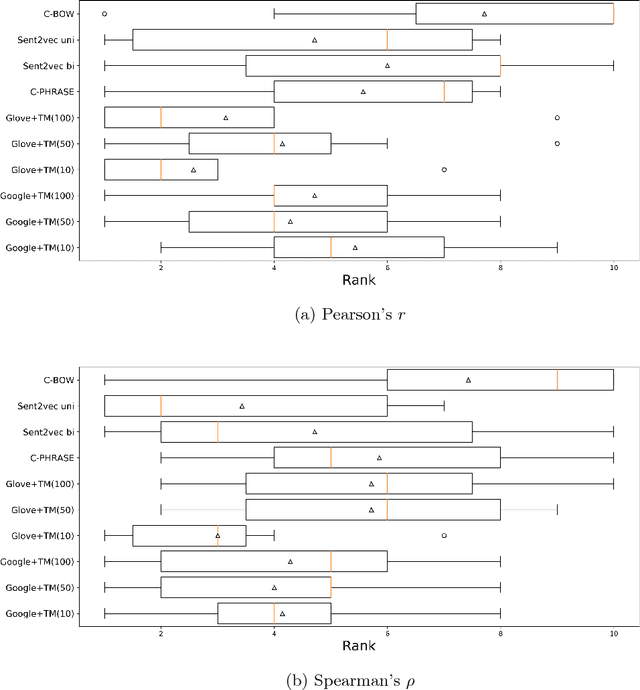
Sentence embedding is a significant research topic in the field of natural language processing (NLP). Generating sentence embedding vectors reflecting the intrinsic meaning of a sentence is a key factor to achieve an enhanced performance in various NLP tasks such as sentence classification and document summarization. Therefore, various sentence embedding models based on supervised and unsupervised learning have been proposed after the advent of researches regarding the distributed representation of words. They were evaluated through semantic textual similarity (STS) tasks, which measure the degree of semantic preservation of a sentence and neural network-based supervised embedding models generally yielded state-of-the-art performance. However, these models have a limitation in that they have multiple parameters to update, thereby requiring a tremendous amount of labeled training data. In this study, we propose an efficient approach that learns a transition matrix that refines a sentence embedding vector to reflect the latent semantic meaning of a sentence. The proposed method has two practical advantages; (1) it can be applied to any sentence embedding method, and (2) it can achieve robust performance in STS tasks irrespective of the number of training examples.