 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Disentanglement enough? On Latent Representations for Controllable Music Generation
Aug 01, 2021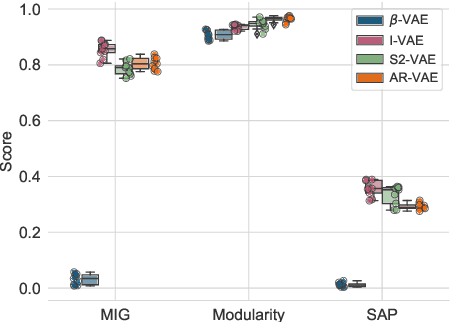

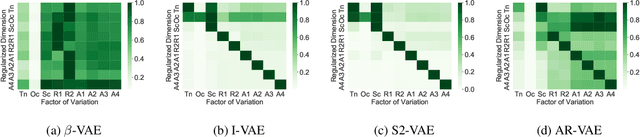
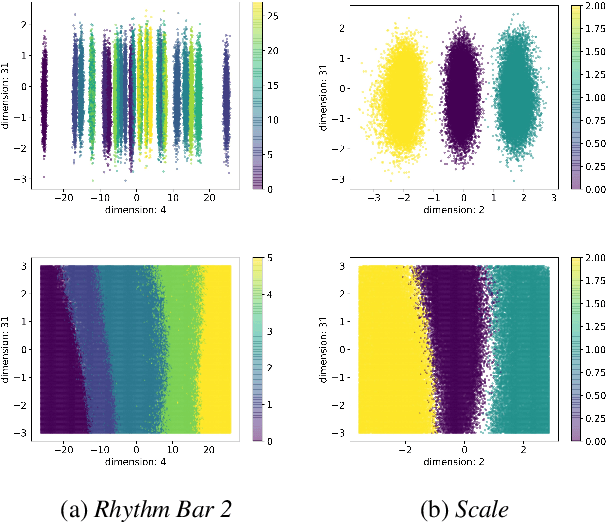
Improving controllability or the ability to manipulate one or more attributes of the generated data has become a topic of interest in the context of deep generative models of music. Recent attempts in this direction have relied on learning disentangled representations from data such that the underlying factors of variation are well separated. In this paper, we focus on the relationship between disentanglement and controllability by conducting a systematic study using different supervised disentanglement learning algorithms based on the Variational Auto-Encoder (VAE) architecture. Our experiments show that a high degree of disentanglement can be achieved by using different forms of supervision to train a strong discriminative encoder. However, in the absence of a strong generative decoder, disentanglement does not necessarily imply controllability. The structure of the latent space with respect to the VAE-decoder plays an important role in boosting the ability of a generative model to manipulate different attributes. To this end, we also propose methods and metrics to help evaluate the quality of a latent space with respect to the afforded degree of controllability.
An Interdisciplinary Review of Music Performance Analysis
Apr 19, 2021
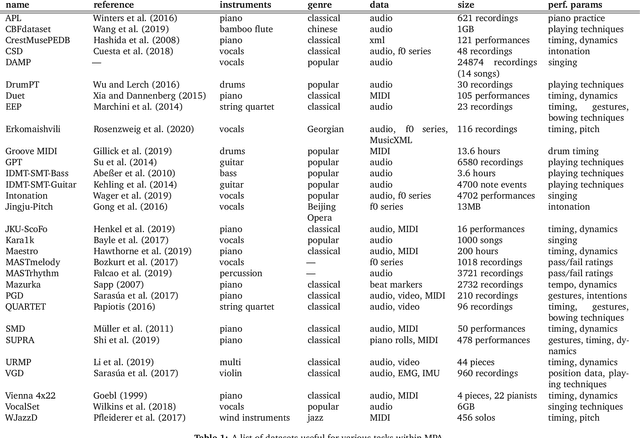
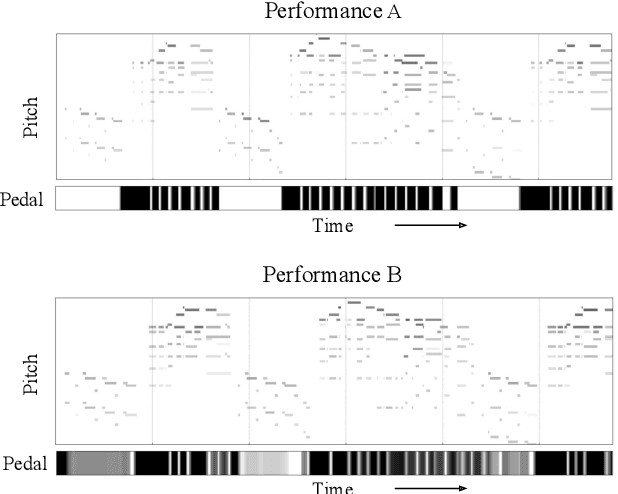
A musical performance renders an acoustic realization of a musical score or other representation of a composition. Different performances of the same composition may vary in terms of performance parameters such as timing or dynamics, and these variations may have a major impact on how a listener perceives the music. The analysis of music performance has traditionally been a peripheral topic for the MIR research community, where often a single audio recording is used as representative of a musical work. This paper surveys the field of Music Performance Analysis (MPA) from several perspectives including the measurement of performance parameters, the relation of those parameters to the actions and intentions of a performer or perceptual effects on a listener, and finally the assessment of musical performance. This paper also discusses MPA as it relates to MIR, pointing out opportunities for collaboration and future research in both areas.
* arXiv admin note: substantial text overlap with arXiv:1907.00178
Score-informed Networks for Music Performance Assessment
Aug 01, 2020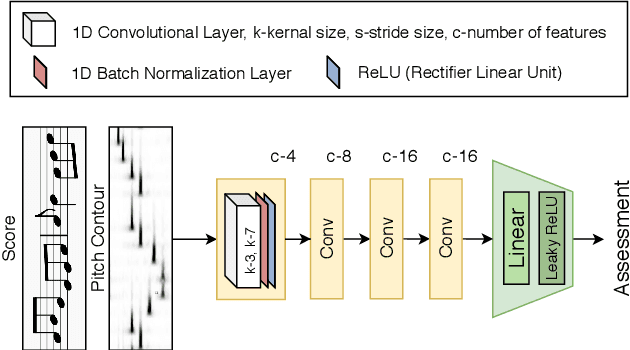
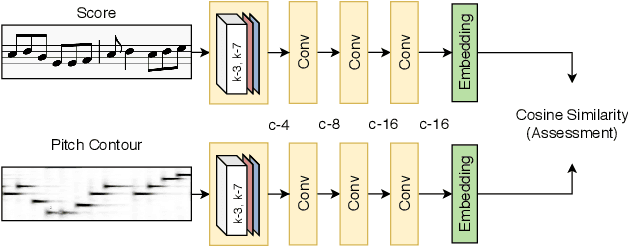
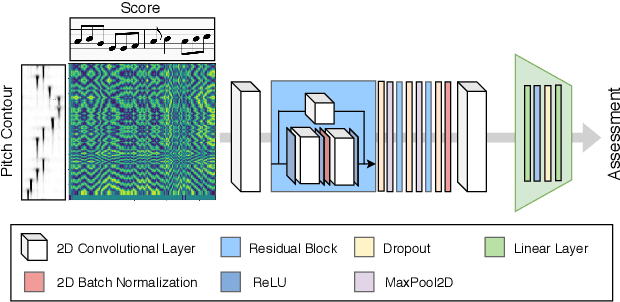
The assessment of music performances in most cases takes into account the underlying musical score being performed. While there have been several automatic approaches for objective music performance assessment (MPA) based on extracted features from both the performance audio and the score, deep neural network-based methods incorporating score information into MPA models have not yet been investigated. In this paper, we introduce three different models capable of score-informed performance assessment. These are (i) a convolutional neural network that utilizes a simple time-series input comprising of aligned pitch contours and score, (ii) a joint embedding model which learns a joint latent space for pitch contours and scores, and (iii) a distance matrix-based convolutional neural network which utilizes patterns in the distance matrix between pitch contours and musical score to predict assessment ratings. Our results provide insights into the suitability of different architectures and input representations and demonstrate the benefits of score-informed models as compared to score-independent models.
dMelodies: A Music Dataset for Disentanglement Learning
Jul 29, 2020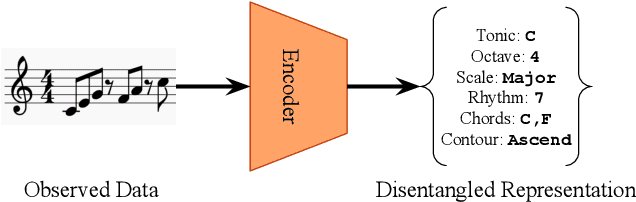
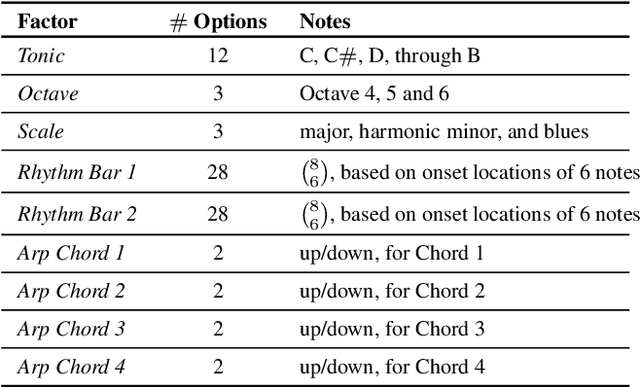
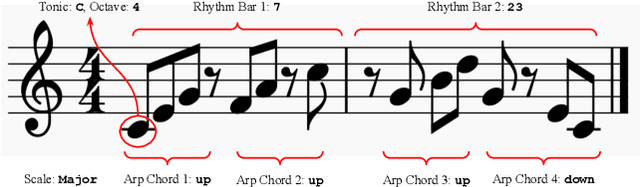
Representation learning focused on disentangling the underlying factors of variation in given data has become an important area of research in machine learning. However, most of the studies in this area have relied on datasets from the computer vision domain and thus, have not been readily extended to music. In this paper, we present a new symbolic music dataset that will help researchers working on disentanglement problems demonstrate the efficacy of their algorithms on diverse domains. This will also provide a means for evaluating algorithms specifically designed for music. To this end, we create a dataset comprising of 2-bar monophonic melodies where each melody is the result of a unique combination of nine latent factors that span ordinal, categorical, and binary types. The dataset is large enough (approx. 1.3 million data points) to train and test deep networks for disentanglement learning. In addition, we present benchmarking experiments using popular unsupervised disentanglement algorithms on this dataset and compare the results with those obtained on an image-based dataset.
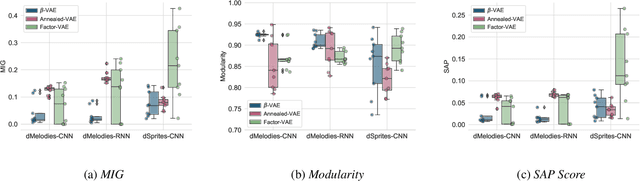
Attribute-based Regularization of VAE Latent Spaces
Apr 11, 2020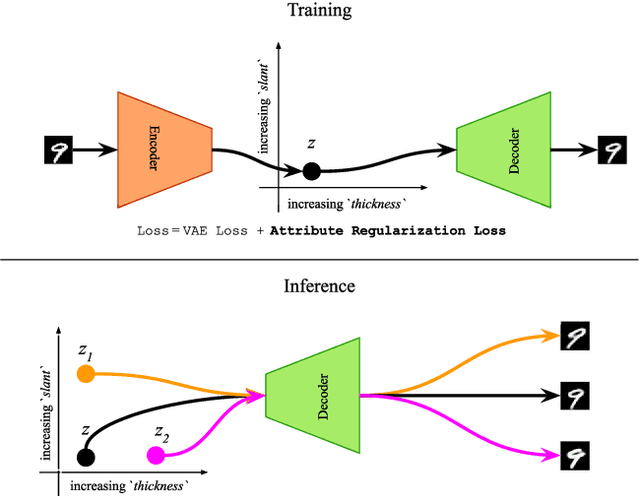
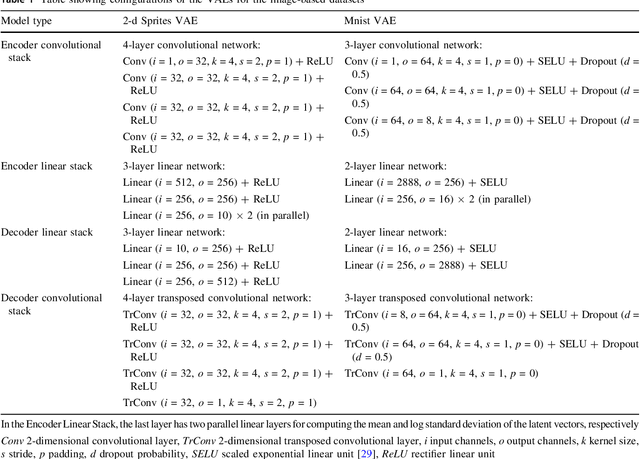


Selective manipulation of data attributes using deep generative models is an active area of research. In this paper, we present a novel method to structure the latent space of a Variational Auto-Encoder (VAE) to encode different continuous-valued attributes explicitly. This is accomplished by using an attribute regularization loss which enforces a monotonic relationship between the attribute values and the latent code of the dimension along which the attribute is to be encoded. Consequently, post-training, the model can be used to manipulate the attribute by simply changing the latent code of the corresponding regularized dimension. The results obtained from several quantitative and qualitative experiments show that the proposed method leads to disentangled and interpretable latent spaces that can be used to effectively manipulate a wide range of data attributes spanning image and symbolic music domains.
Explicitly Conditioned Melody Generation: A Case Study with Interdependent RNNs
Jul 10, 2019
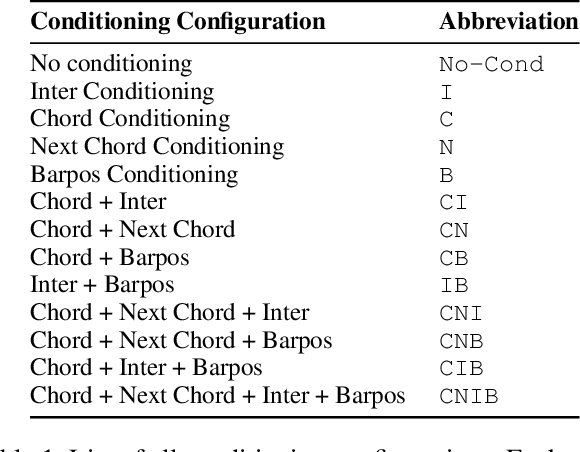
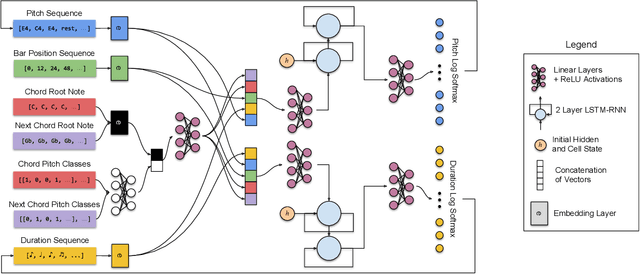
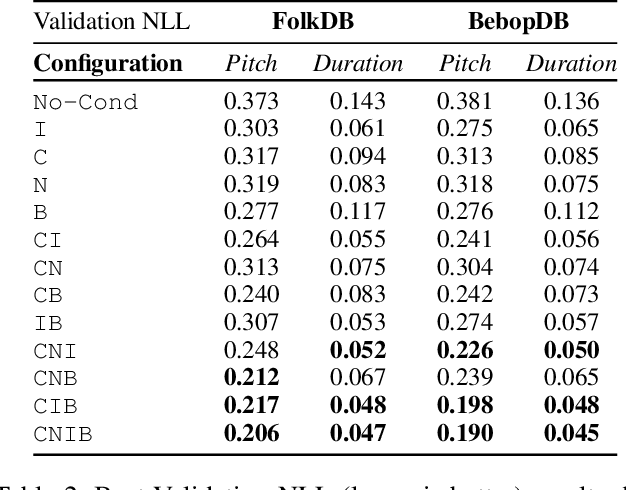
Deep generative models for symbolic music are typically designed to model temporal dependencies in music so as to predict the next musical event given previous events. In many cases, such models are expected to learn abstract concepts such as harmony, meter, and rhythm from raw musical data without any additional information. In this study, we investigate the effects of explicitly conditioning deep generative models with musically relevant information. Specifically, we study the effects of four different conditioning inputs on the performance of a recurrent monophonic melody generation model. Several combinations of these conditioning inputs are used to train different model variants which are then evaluated using three objective evaluation paradigms across two genres of music. The results indicate musically relevant conditioning significantly improves learning and performance, and reveal how this information affects learning of musical features related to pitch and rhythm. An informal subjective evaluation suggests a corresponding improvement in the aesthetic quality of generations.
Learning to Traverse Latent Spaces for Musical Score Inpainting
Jul 02, 2019
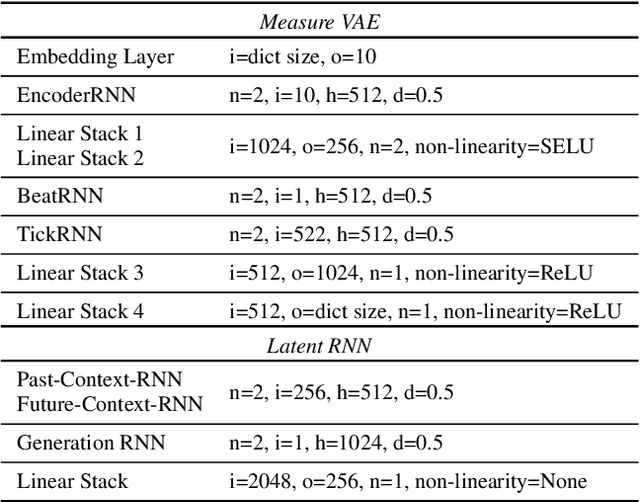

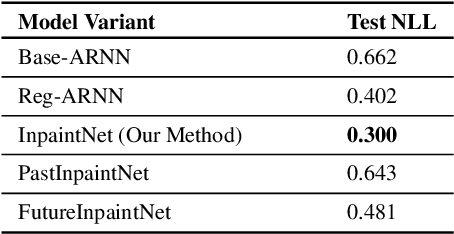
Music Inpainting is the task of filling in missing or lost information in a piece of music. We investigate this task from an interactive music creation perspective. To this end, a novel deep learning-based approach for musical score inpainting is proposed. The designed model takes both past and future musical context into account and is capable of suggesting ways to connect them in a musically meaningful manner. To achieve this, we leverage the representational power of the latent space of a Variational Auto-Encoder and train a Recurrent Neural Network which learns to traverse this latent space conditioned on the past and future musical contexts. Consequently, the designed model is capable of generating several measures of music to connect two musical excerpts. The capabilities and performance of the model are showcased by comparison with competitive baselines using several objective and subjective evaluation methods. The results show that the model generates meaningful inpaintings and can be used in interactive music creation applications. Overall, the method demonstrates the merit of learning complex trajectories in the latent spaces of deep generative models.
A Rule-Based Computational Model of Cognitive Arithmetic
May 03, 2017

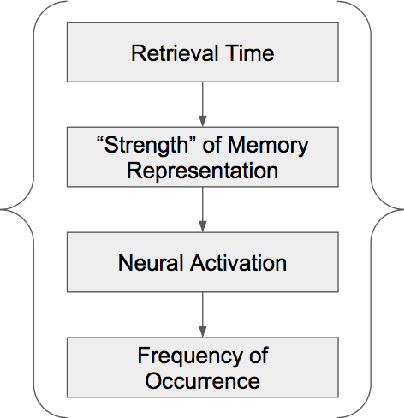
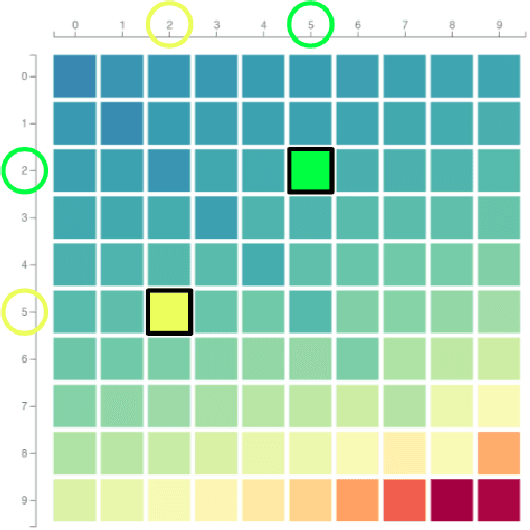
Cognitive arithmetic studies the mental processes used in solving math problems. This area of research explores the retrieval mechanisms and strategies used by people during a common cognitive task. Past research has shown that human performance in arithmetic operations is correlated to the numerical size of the problem. Past research on cognitive arithmetic has pinpointed this trend to either retrieval strength, error checking, or strategy-based approaches when solving equations. This paper describes a rule-based computational model that performs the four major arithmetic operations (addition, subtraction, multiplication and division) on two operands. We then evaluated our model to probe its validity in representing the prevailing concepts observed in psychology experiments from the related works. The experiments specifically explore the problem size effect, an activation-based model for fact retrieval, backup strategies when retrieval fails, and finally optimization strategies when faced with large operands. From our experimental results, we concluded that our model's response times were comparable to results observed when people performed similar tasks during psychology experiments. The fit of our model in reproducing these results and incorporating accuracy into our model are discussed.