 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIComposer: Any Style and Content Image Composition via Feature Integration
Jul 28, 2025Image composition has advanced significantly with large-scale pre-trained T2I diffusion models. Despite progress in same-domain composition, cross-domain composition remains under-explored. The main challenges are the stochastic nature of diffusion models and the style gap between input images, leading to failures and artifacts. Additionally, heavy reliance on text prompts limits practical applications. This paper presents the first cross-domain image composition method that does not require text prompts, allowing natural stylization and seamless compositions. Our method is efficient and robust, preserving the diffusion prior, as it involves minor steps for backward inversion and forward denoising without training the diffuser. Our method also uses a simple multilayer perceptron network to integrate CLIP features from foreground and background, manipulating diffusion with a local cross-attention strategy. It effectively preserves foreground content while enabling stable stylization without a pre-stylization network. Finally, we create a benchmark dataset with diverse contents and styles for fair evaluation, addressing the lack of testing datasets for cross-domain image composition. Our method outperforms state-of-the-art techniques in both qualitative and quantitative evaluations, significantly improving the LPIPS score by 30.5% and the CSD metric by 18.1%. We believe our method will advance future research and applications. Code and benchmark at https://github.com/sherlhw/AIComposer.
LoVR: A Benchmark for Long Video Retrieval in Multimodal Contexts
May 20, 2025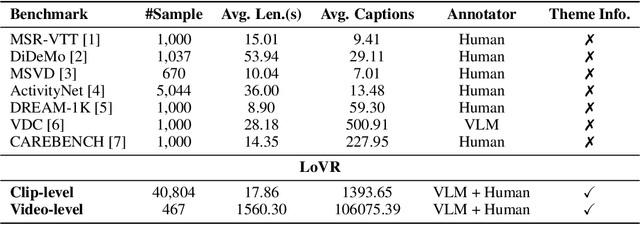

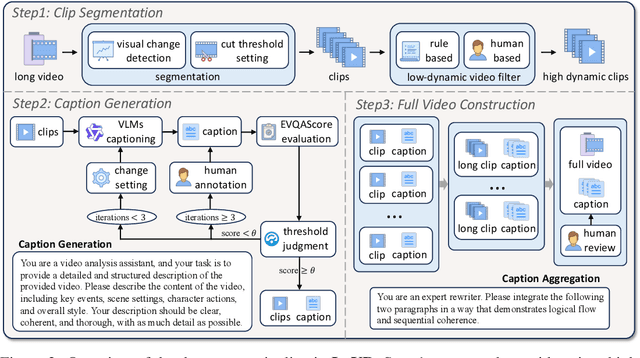
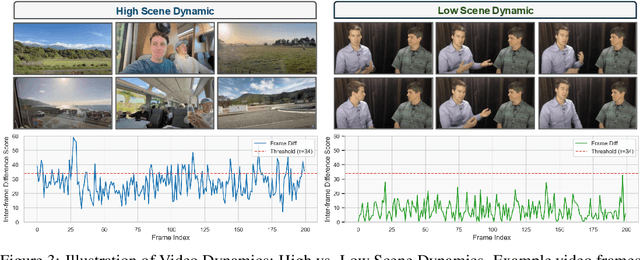
Long videos contain a vast amount of information, making video-text retrieval an essential and challenging task in multimodal learning. However, existing benchmarks suffer from limited video duration, low-quality captions, and coarse annotation granularity, which hinder the evaluation of advanced video-text retrieval methods. To address these limitations, we introduce LoVR, a benchmark specifically designed for long video-text retrieval. LoVR contains 467 long videos and over 40,804 fine-grained clips with high-quality captions. To overcome the issue of poor machine-generated annotations, we propose an efficient caption generation framework that integrates VLM automatic generation, caption quality scoring, and dynamic refinement. This pipeline improves annotation accuracy while maintaining scalability. Furthermore, we introduce a semantic fusion method to generate coherent full-video captions without losing important contextual information. Our benchmark introduces longer videos, more detailed captions, and a larger-scale dataset, presenting new challenges for video understanding and retrieval. Extensive experiments on various advanced embedding models demonstrate that LoVR is a challenging benchmark, revealing the limitations of current approaches and providing valuable insights for future research. We release the code and dataset link at https://github.com/TechNomad-ds/LoVR-benchmark
Let's Verify Math Questions Step by Step
May 20, 2025Large Language Models (LLMs) have recently achieved remarkable progress in mathematical reasoning. To enable such capabilities, many existing works distill strong reasoning models into long chains of thought or design algorithms to construct high-quality math QA data for training. However, these efforts primarily focus on generating correct reasoning paths and answers, while largely overlooking the validity of the questions themselves. In this work, we propose Math Question Verification (MathQ-Verify), a novel five-stage pipeline designed to rigorously filter ill-posed or under-specified math problems. MathQ-Verify first performs format-level validation to remove redundant instructions and ensure that each question is syntactically well-formed. It then formalizes each question, decomposes it into atomic conditions, and verifies them against mathematical definitions. Next, it detects logical contradictions among these conditions, followed by a goal-oriented completeness check to ensure the question provides sufficient information for solving. To evaluate this task, we use existing benchmarks along with an additional dataset we construct, containing 2,147 math questions with diverse error types, each manually double-validated. Experiments show that MathQ-Verify achieves state-of-the-art performance across multiple benchmarks, improving the F1 score by up to 25 percentage points over the direct verification baseline. It further attains approximately 90% precision and 63% recall through a lightweight model voting scheme. MathQ-Verify offers a scalable and accurate solution for curating reliable mathematical datasets, reducing label noise and avoiding unnecessary computation on invalid questions. Our code and data are available at https://github.com/scuuy/MathQ-Verify.
MathClean: A Benchmark for Synthetic Mathematical Data Cleaning
Feb 26, 2025



With the rapid development of large language models (LLMs), the quality of training data has become crucial. Among the various types of training data, mathematical data plays a key role in enabling LLMs to acquire strong reasoning abilities. While high-quality open-source data is important, it is often insufficient for pre-training, necessitating the addition of synthetic math problems. However, synthetic math questions and answers can introduce inaccuracies, which may degrade both the training data and web data. Therefore, an effective method for cleaning synthetic math data is essential. In this paper, we propose the MathClean benchmark to evaluate the effectiveness of math data cleaning models. The MathClean benchmark consists of 2,000 correct questions and 2,000 erroneous questions with additional 2,000 correct and erroneous answers sourced from augmented data based on GSM8K and MATH. Moreover, we also annotate error types for each question or answer, since it can assess whether models can correctly identify the error categories for future improvements. Finally, we present comprehensive evaluations using state-of-the-art (SOTA) models. Our results demonstrate that even strong models like GPT-o1 and DeepSeek-R1 perform poorly on this benchmark, highlighting the utility of MathClean. Our code and data is available at https://github.com/YuYingLi0/MathClean.
A Pairwise Probe for Understanding BERT Fine-Tuning on Machine Reading Comprehension
Jun 02, 2020
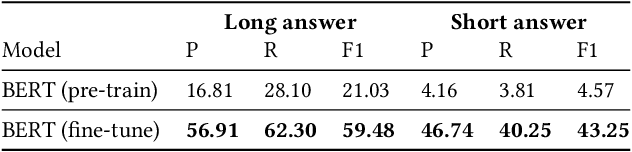
Pre-trained models have brought significant improvements to many NLP tasks and have been extensively analyzed. But little is known about the effect of fine-tuning on specific tasks. Intuitively, people may agree that a pre-trained model already learns semantic representations of words (e.g. synonyms are closer to each other) and fine-tuning further improves its capabilities which require more complicated reasoning (e.g. coreference resolution, entity boundary detection, etc). However, how to verify these arguments analytically and quantitatively is a challenging task and there are few works focus on this topic. In this paper, inspired by the observation that most probing tasks involve identifying matched pairs of phrases (e.g. coreference requires matching an entity and a pronoun), we propose a pairwise probe to understand BERT fine-tuning on the machine reading comprehension (MRC) task. Specifically, we identify five phenomena in MRC. According to pairwise probing tasks, we compare the performance of each layer's hidden representation of pre-trained and fine-tuned BERT. The proposed pairwise probe alleviates the problem of distraction from inaccurate model training and makes a robust and quantitative comparison. Our experimental analysis leads to highly confident conclusions: (1) Fine-tuning has little effect on the fundamental and low-level information and general semantic tasks. (2) For specific abilities required for downstream tasks, fine-tuned BERT is better than pre-trained BERT and such gaps are obvious after the fifth layer.