 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmartMem: Layout Transformation Elimination and Adaptation for Efficient DNN Execution on Mobile
Apr 21, 2024



This work is motivated by recent developments in Deep Neural Networks, particularly the Transformer architectures underlying applications such as ChatGPT, and the need for performing inference on mobile devices. Focusing on emerging transformers (specifically the ones with computationally efficient Swin-like architectures) and large models (e.g., Stable Diffusion and LLMs) based on transformers, we observe that layout transformations between the computational operators cause a significant slowdown in these applications. This paper presents SmartMem, a comprehensive framework for eliminating most layout transformations, with the idea that multiple operators can use the same tensor layout through careful choice of layout and implementation of operations. Our approach is based on classifying the operators into four groups, and considering combinations of producer-consumer edges between the operators. We develop a set of methods for searching such layouts. Another component of our work is developing efficient memory layouts for 2.5 dimensional memory commonly seen in mobile devices. Our experimental results show that SmartMem outperforms 5 state-of-the-art DNN execution frameworks on mobile devices across 18 varied neural networks, including CNNs, Transformers with both local and global attention, as well as LLMs. In particular, compared to DNNFusion, SmartMem achieves an average speedup of 2.8$\times$, and outperforms TVM and MNN with speedups of 6.9$\times$ and 7.9$\times$, respectively, on average.
Real-Time Portrait Stylization on the Edge
Jun 02, 2022
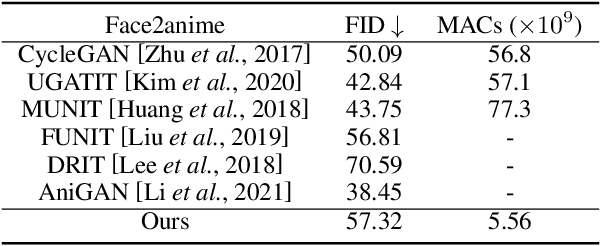


In this work we demonstrate real-time portrait stylization, specifically, translating self-portrait into cartoon or anime style on mobile devices. We propose a latency-driven differentiable architecture search method, maintaining realistic generative quality. With our framework, we obtain $10\times$ computation reduction on the generative model and achieve real-time video stylization on off-the-shelf smartphone using mobile GPUs.
Enabling Level-4 Autonomous Driving on a Single $1k Off-the-Shelf Card
Oct 12, 2021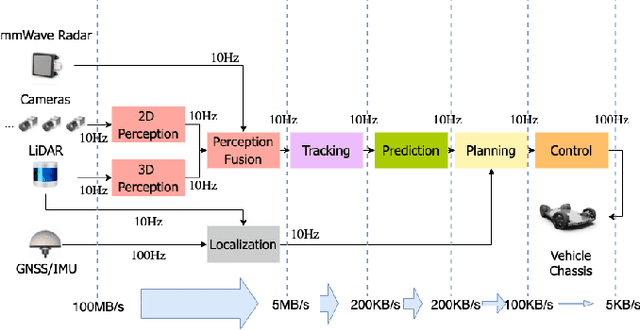
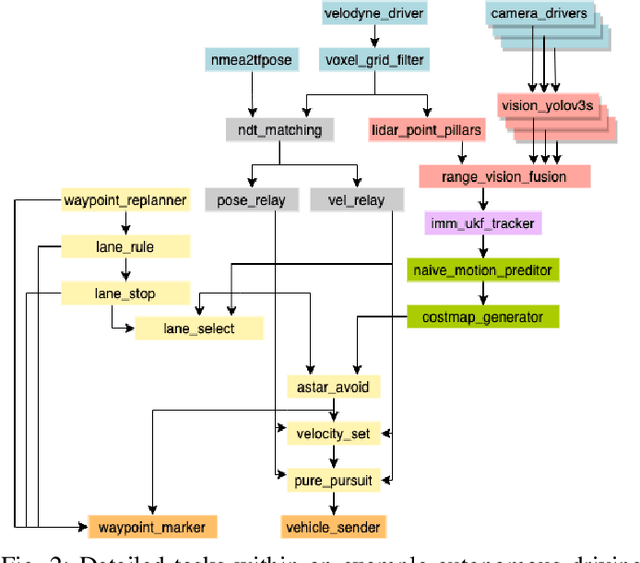
Autonomous driving is of great interest in both research and industry. The high cost has been one of the major roadblocks that slow down the development and adoption of autonomous driving in practice. This paper, for the first-time, shows that it is possible to run level-4 (i.e., fully autonomous driving) software on a single off-the-shelf card (Jetson AGX Xavier) for less than $1k, an order of magnitude less than the state-of-the-art systems, while meeting all the requirements of latency. The success comes from the resolution of some important issues shared by existing practices through a series of measures and innovations. The study overturns the common perceptions of the computing resources required by level-4 autonomous driving, points out a promising path for the industry to lower the cost, and suggests a number of research opportunities for rethinking the architecture, software design, and optimizations of autonomous driving.
DNNFusion: Accelerating Deep Neural Networks Execution with Advanced Operator Fusion
Aug 30, 2021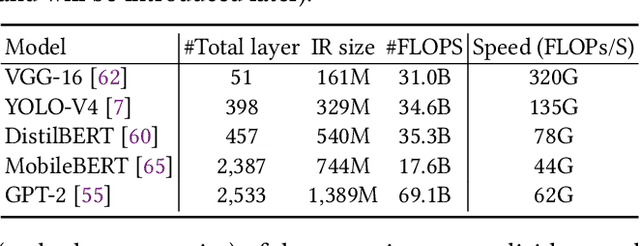
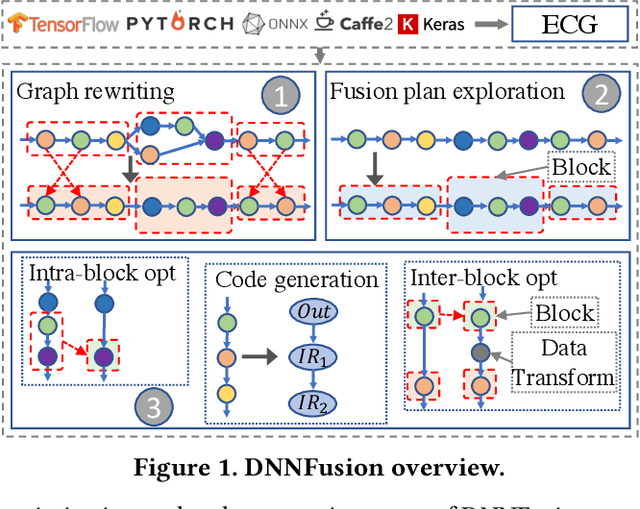

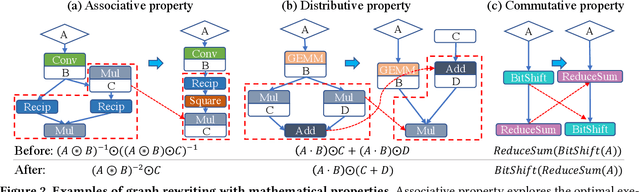
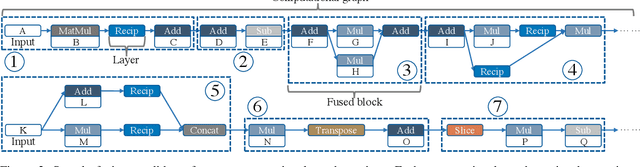
Deep Neural Networks (DNNs) have emerged as the core enabler of many major applications on mobile devices. To achieve high accuracy, DNN models have become increasingly deep with hundreds or even thousands of operator layers, leading to high memory and computational requirements for inference. Operator fusion (or kernel/layer fusion) is key optimization in many state-of-the-art DNN execution frameworks, such as TensorFlow, TVM, and MNN. However, these frameworks usually adopt fusion approaches based on certain patterns that are too restrictive to cover the diversity of operators and layer connections. Polyhedral-based loop fusion techniques, on the other hand, work on a low-level view of the computation without operator-level information, and can also miss potential fusion opportunities. To address this challenge, this paper proposes a novel and extensive loop fusion framework called DNNFusion. The basic idea of this work is to work at an operator view of DNNs, but expand fusion opportunities by developing a classification of both individual operators and their combinations. In addition, DNNFusion includes 1) a novel mathematical-property-based graph rewriting framework to reduce evaluation costs and facilitate subsequent operator fusion, 2) an integrated fusion plan generation that leverages the high-level analysis and accurate light-weight profiling, and 3) additional optimizations during fusion code generation. DNNFusion is extensively evaluated on 15 DNN models with varied types of tasks, model sizes, and layer counts. The evaluation results demonstrate that DNNFusion finds up to 8.8x higher fusion opportunities, outperforms four state-of-the-art DNN execution frameworks with 9.3x speedup. The memory requirement reduction and speedups can enable the execution of many of the target models on mobile devices and even make them part of a real-time application.
Towards Fast and Accurate Multi-Person Pose Estimation on Mobile Devices
Jun 06, 2021



The rapid development of autonomous driving, abnormal behavior detection, and behavior recognition makes an increasing demand for multi-person pose estimation-based applications, especially on mobile platforms. However, to achieve high accuracy, state-of-the-art methods tend to have a large model size and complex post-processing algorithm, which costs intense computation and long end-to-end latency. To solve this problem, we propose an architecture optimization and weight pruning framework to accelerate inference of multi-person pose estimation on mobile devices. With our optimization framework, we achieve up to 2.51x faster model inference speed with higher accuracy compared to representative lightweight multi-person pose estimator.
A Compression-Compilation Framework for On-mobile Real-time BERT Applications
Jun 06, 2021


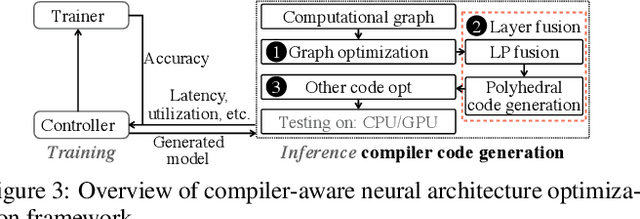
Transformer-based deep learning models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. In this paper, we propose a compression-compilation co-design framework that can guarantee the identified model to meet both resource and real-time specifications of mobile devices. Our framework applies a compiler-aware neural architecture optimization method (CANAO), which can generate the optimal compressed model that balances both accuracy and latency. We are able to achieve up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss. We present two types of BERT applications on mobile devices: Question Answering (QA) and Text Generation. Both can be executed in real-time with latency as low as 45ms. Videos for demonstrating the framework can be found on https://www.youtube.com/watch?v=_WIRvK_2PZI
Achieving Real-Time Execution of Transformer-based Large-scale Models on Mobile with Compiler-aware Neural Architecture Optimization
Sep 15, 2020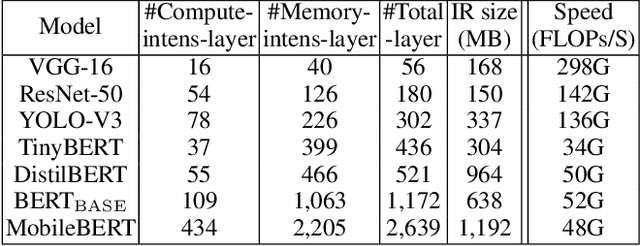
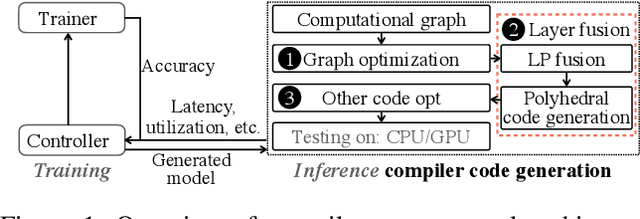
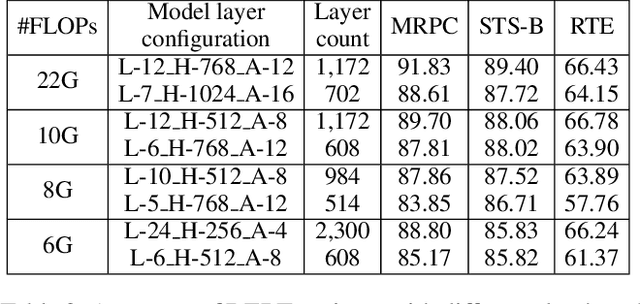
Pre-trained large-scale language models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. However, the limited weight storage and computational speed on hardware platforms have impeded the popularity of pre-trained models, especially in the era of edge computing. In this paper, we seek to find the best model structure of BERT for a given computation size to match specific devices. We propose the first compiler-aware neural architecture optimization framework (called CANAO). CANAO can guarantee the identified model to meet both resource and real-time specifications of mobile devices, thus achieving real-time execution of large transformer-based models like BERT variants. We evaluate our model on several NLP tasks, achieving competitive results on well-known benchmarks with lower latency on mobile devices. Specifically, our model is 5.2x faster on CPU and 4.1x faster on GPU with 0.5-2% accuracy loss compared with BERT-base. Our overall framework achieves up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss.
Achieving Real-Time Execution of 3D Convolutional Neural Networks on Mobile Devices
Jul 20, 2020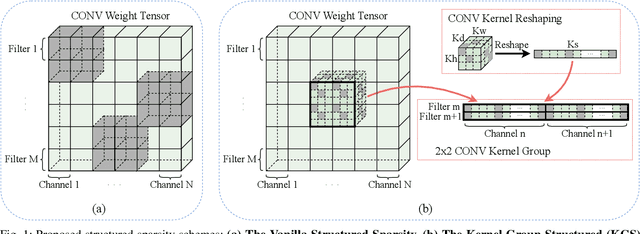
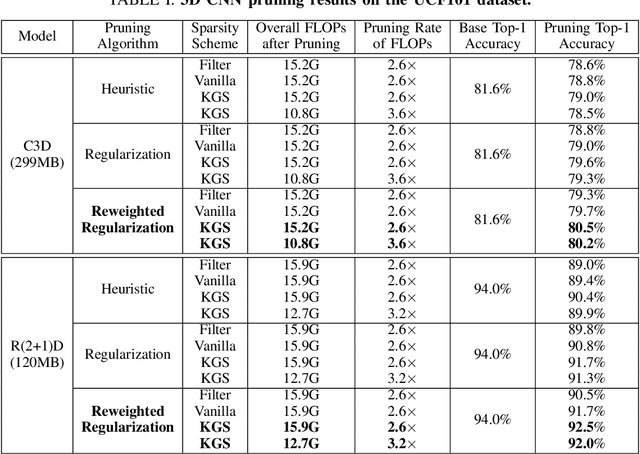
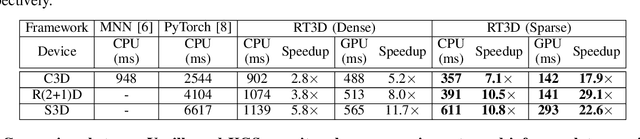

Mobile devices are becoming an important carrier for deep learning tasks, as they are being equipped with powerful, high-end mobile CPUs and GPUs. However, it is still a challenging task to execute 3D Convolutional Neural Networks (CNNs) targeting for real-time performance, besides high inference accuracy. The reason is more complex model structure and higher model dimensionality overwhelm the available computation/storage resources on mobile devices. A natural way may be turning to deep learning weight pruning techniques. However, the direct generalization of existing 2D CNN weight pruning methods to 3D CNNs is not ideal for fully exploiting mobile parallelism while achieving high inference accuracy. This paper proposes RT3D, a model compression and mobile acceleration framework for 3D CNNs, seamlessly integrating neural network weight pruning and compiler code generation techniques. We propose and investigate two structured sparsity schemes i.e., the vanilla structured sparsity and kernel group structured (KGS) sparsity that are mobile acceleration friendly. The vanilla sparsity removes whole kernel groups, while KGS sparsity is a more fine-grained structured sparsity that enjoys higher flexibility while exploiting full on-device parallelism. We propose a reweighted regularization pruning algorithm to achieve the proposed sparsity schemes. The inference time speedup due to sparsity is approaching the pruning rate of the whole model FLOPs (floating point operations). RT3D demonstrates up to 29.1$\times$ speedup in end-to-end inference time comparing with current mobile frameworks supporting 3D CNNs, with moderate 1%-1.5% accuracy loss. The end-to-end inference time for 16 video frames could be within 150 ms, when executing representative C3D and R(2+1)D models on a cellphone. For the first time, real-time execution of 3D CNNs is achieved on off-the-shelf mobiles.