 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Real-Time Execution of Transformer-based Large-scale Models on Mobile with Compiler-aware Neural Architecture Optimization
Paper and Code
Sep 15, 2020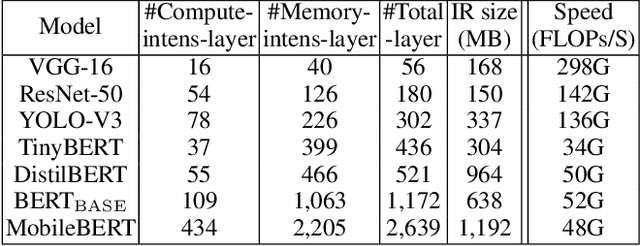
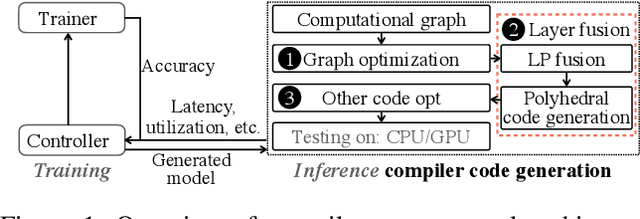
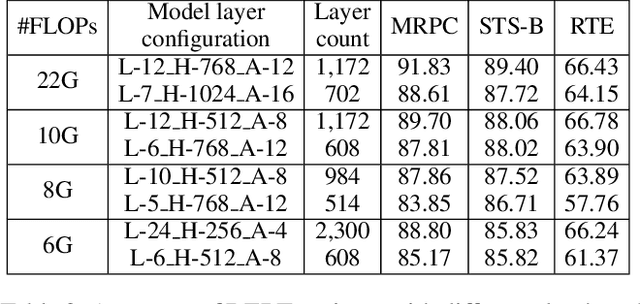
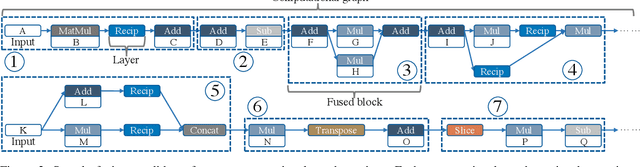
Pre-trained large-scale language models have increasingly demonstrated high accuracy on many natural language processing (NLP) tasks. However, the limited weight storage and computational speed on hardware platforms have impeded the popularity of pre-trained models, especially in the era of edge computing. In this paper, we seek to find the best model structure of BERT for a given computation size to match specific devices. We propose the first compiler-aware neural architecture optimization framework (called CANAO). CANAO can guarantee the identified model to meet both resource and real-time specifications of mobile devices, thus achieving real-time execution of large transformer-based models like BERT variants. We evaluate our model on several NLP tasks, achieving competitive results on well-known benchmarks with lower latency on mobile devices. Specifically, our model is 5.2x faster on CPU and 4.1x faster on GPU with 0.5-2% accuracy loss compared with BERT-base. Our overall framework achieves up to 7.8x speedup compared with TensorFlow-Lite with only minor accuracy loss.