 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTool Learning with Foundation Models
Apr 17, 2023Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the potential to be equally adept in tool use as humans. This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field. To this end, we present a systematic investigation of tool learning in this paper. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research into tool-augmented and tool-oriented learning. We formulate a general tool learning framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate the generalization in tool learning. Considering the lack of a systematic tool learning evaluation in prior works, we experiment with 17 representative tools and show the potential of current foundation models in skillfully utilizing tools. Finally, we discuss several open problems that require further investigation for tool learning. Overall, we hope this paper could inspire future research in integrating tools with foundation models.
GSplit: Scaling Graph Neural Network Training on Large Graphs via Split-Parallelism
Mar 24, 2023Large-scale graphs with billions of edges are ubiquitous in many industries, science, and engineering fields such as recommendation systems, social graph analysis, knowledge base, material science, and biology. Graph neural networks (GNN), an emerging class of machine learning models, are increasingly adopted to learn on these graphs due to their superior performance in various graph analytics tasks. Mini-batch training is commonly adopted to train on large graphs, and data parallelism is the standard approach to scale mini-batch training to multiple GPUs. In this paper, we argue that several fundamental performance bottlenecks of GNN training systems have to do with inherent limitations of the data parallel approach. We then propose split parallelism, a novel parallel mini-batch training paradigm. We implement split parallelism in a novel system called gsplit and show that it outperforms state-of-the-art systems such as DGL, Quiver, and PaGraph.
Learning from Lexical Perturbations for Consistent Visual Question Answering
Dec 23, 2020

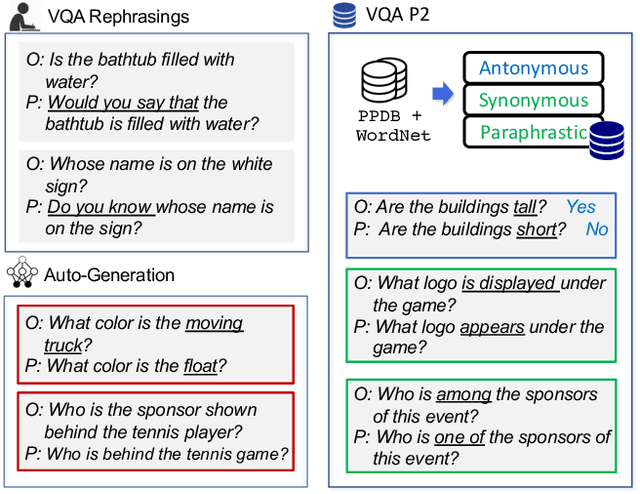
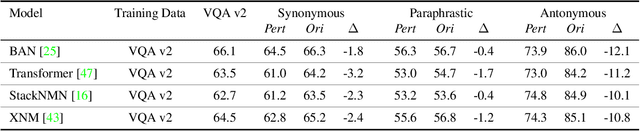
Existing Visual Question Answering (VQA) models are often fragile and sensitive to input variations. In this paper, we propose a novel approach to address this issue based on modular networks, which creates two questions related by linguistic perturbations and regularizes the visual reasoning process between them to be consistent during training. We show that our framework markedly improves consistency and generalization ability, demonstrating the value of controlled linguistic perturbations as a useful and currently underutilized training and regularization tool for VQA models. We also present VQA Perturbed Pairings (VQA P2), a new, low-cost benchmark and augmentation pipeline to create controllable linguistic variations of VQA questions. Our benchmark uniquely draws from large-scale linguistic resources, avoiding human annotation effort while maintaining data quality compared to generative approaches. We benchmark existing VQA models using VQA P2 and provide robustness analysis on each type of linguistic variation.
Responsive Planning and Recognition for Closed-Loop Interaction
Sep 13, 2019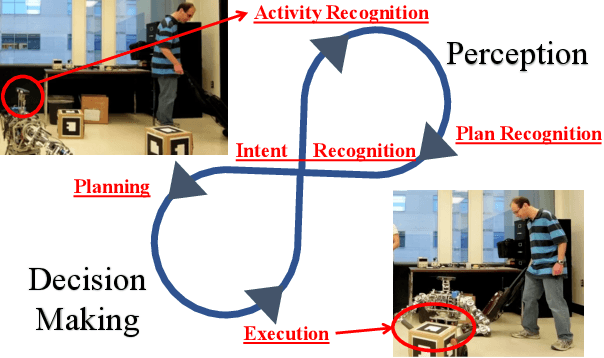
Many intelligent systems currently interact with others using at least one of fixed communication inputs or preset responses, resulting in rigid interaction experiences and extensive efforts developing a variety of scenarios for the system. Fixed inputs limit the natural behavior of the user in order to effectively communicate, and preset responses prevent the system from adapting to the current situation unless it was specifically implemented. Closed-loop interaction instead focuses on dynamic responses that account for what the user is currently doing based on interpretations of their perceived activity. Agents employing closed-loop interaction can also monitor their interactions to ensure that the user responds as expected. We introduce a closed-loop interactive agent framework that integrates planning and recognition to predict what the user is trying to accomplish and autonomously decide on actions to take in response to these predictions. Based on a recent demonstration of such an assistive interactive agent in a turn-based simulated game, we also discuss new research challenges that are not present in the areas of artificial intelligence planning or recognition alone.
Alzheimer's Disease Brain MRI Classification: Challenges and Insights
Jun 10, 2019
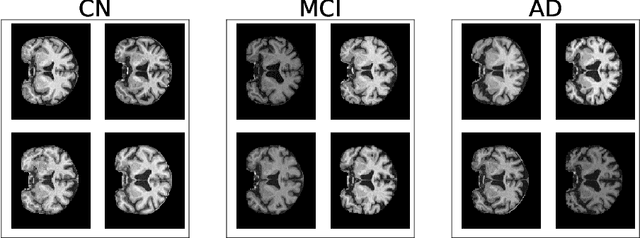
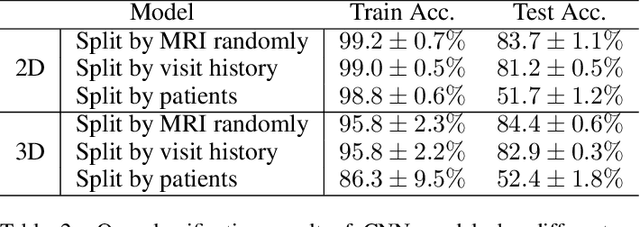
In recent years, many papers have reported state-of-the-art performance on Alzheimer's Disease classification with MRI scans from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset using convolutional neural networks. However, we discover that when we split that data into training and testing sets at the subject level, we are not able to obtain similar performance, bringing the validity of many of the previous studies into question. Furthermore, we point out that previous works use different subsets of the ADNI data, making comparison across similar works tricky. In this study, we present the results of three splitting methods, discuss the motivations behind their validity, and report our results using all of the available subjects.
A Comprehensive Study of Alzheimer's Disease Classification Using Convolutional Neural Networks
Apr 16, 2019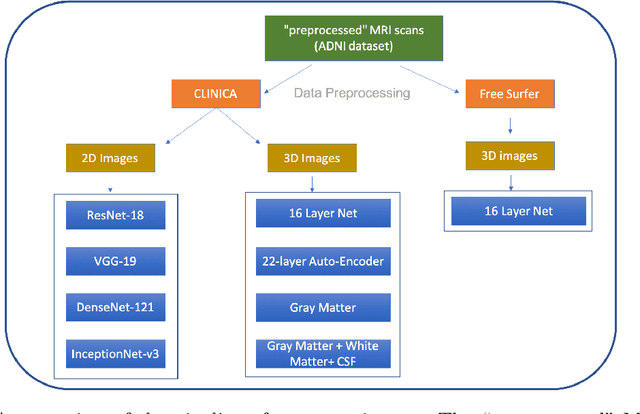
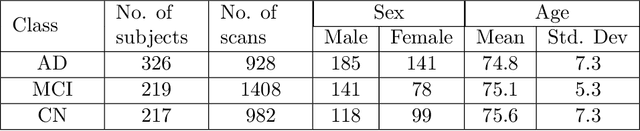
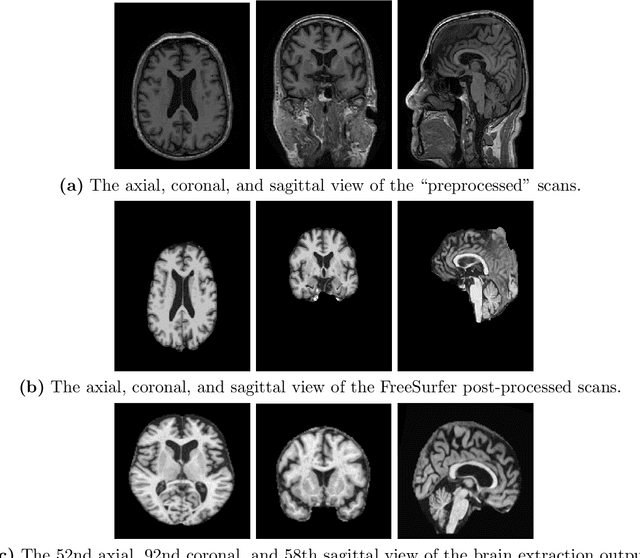
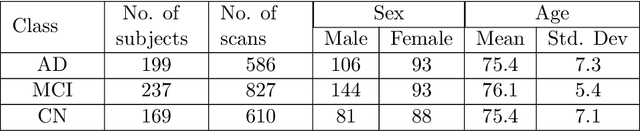
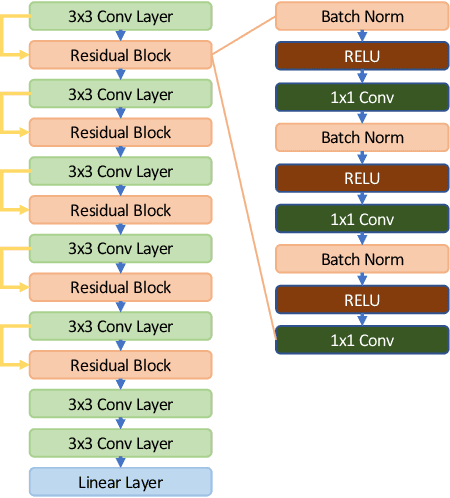
A plethora of deep learning models have been developed for the task of Alzheimer's disease classification from brain MRI scans. Many of these models report high performance, achieving three-class classification accuracy of up to 95%. However, it is common for these studies to draw performance comparisons between models that are trained on different subsets of a dataset or use varying imaging preprocessing techniques, making it difficult to objectively assess model performance. Furthermore, many of these works do not provide details such as hyperparameters, the specific MRI scans used, or their source code, making it difficult to replicate their experiments. To address these concerns, we present a comprehensive study of some of the deep learning methods and architectures on the full set of images available from ADNI. We find that, (1) classification using 3D models gives an improvement of 1% in our setup, at the cost of significantly longer training time and more computation power, (2) with our dataset, pre-training yields minimal ($<0.5\%$) improvement in model performance, (3) most popular convolutional neural network models yield similar performance when compared to each other. Lastly, we briefly compare the effects of two image preprocessing programs: FreeSurfer and Clinica, and find that the spatially normalized and segmented outputs from Clinica increased the accuracy of model prediction from 63% to 89% when compared to FreeSurfer images.