 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Lexical Perturbations for Consistent Visual Question Answering
Paper and Code


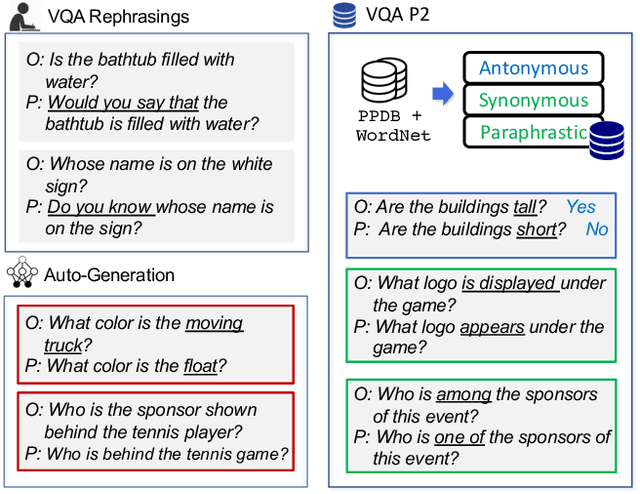
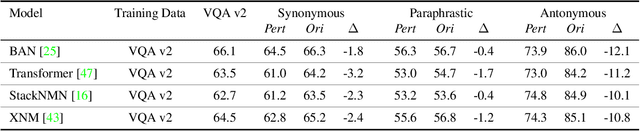
Existing Visual Question Answering (VQA) models are often fragile and sensitive to input variations. In this paper, we propose a novel approach to address this issue based on modular networks, which creates two questions related by linguistic perturbations and regularizes the visual reasoning process between them to be consistent during training. We show that our framework markedly improves consistency and generalization ability, demonstrating the value of controlled linguistic perturbations as a useful and currently underutilized training and regularization tool for VQA models. We also present VQA Perturbed Pairings (VQA P2), a new, low-cost benchmark and augmentation pipeline to create controllable linguistic variations of VQA questions. Our benchmark uniquely draws from large-scale linguistic resources, avoiding human annotation effort while maintaining data quality compared to generative approaches. We benchmark existing VQA models using VQA P2 and provide robustness analysis on each type of linguistic variation.