 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAG-MM: Multi-modal Multi-turn Comprehensive RAG Benchmark
Oct 30, 2025


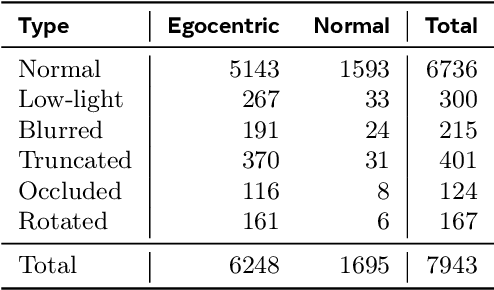
Wearable devices such as smart glasses are transforming the way people interact with their surroundings, enabling users to seek information regarding entities in their view. Multi-Modal Retrieval-Augmented Generation (MM-RAG) plays a key role in supporting such questions, yet there is still no comprehensive benchmark for this task, especially regarding wearables scenarios. To fill this gap, we present CRAG-MM -- a Comprehensive RAG benchmark for Multi-modal Multi-turn conversations. CRAG-MM contains a diverse set of 6.5K (image, question, answer) triplets and 2K visual-based multi-turn conversations across 13 domains, including 6.2K egocentric images designed to mimic captures from wearable devices. We carefully constructed the questions to reflect real-world scenarios and challenges, including five types of image-quality issues, six question types, varying entity popularity, differing information dynamism, and different conversation turns. We design three tasks: single-source augmentation, multi-source augmentation, and multi-turn conversations -- each paired with an associated retrieval corpus and APIs for both image-KG retrieval and webpage retrieval. Our evaluation shows that straightforward RAG approaches achieve only 32% and 43% truthfulness on CRAG-MM single- and multi-turn QA, respectively, whereas state-of-the-art industry solutions have similar quality (32%/45%), underscoring ample room for improvement. The benchmark has hosted KDD Cup 2025, attracting about 1K participants and 5K submissions, with winning solutions improving baseline performance by 28%, highlighting its early impact on advancing the field.
Alzheimer's Disease Brain MRI Classification: Challenges and Insights
Jun 10, 2019
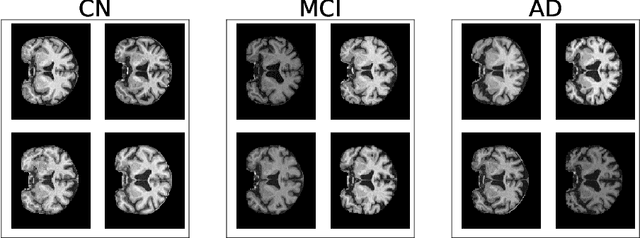
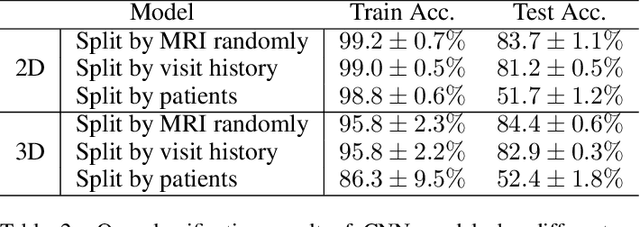
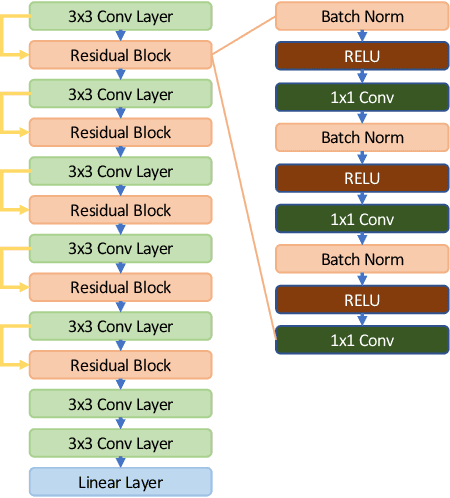
In recent years, many papers have reported state-of-the-art performance on Alzheimer's Disease classification with MRI scans from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset using convolutional neural networks. However, we discover that when we split that data into training and testing sets at the subject level, we are not able to obtain similar performance, bringing the validity of many of the previous studies into question. Furthermore, we point out that previous works use different subsets of the ADNI data, making comparison across similar works tricky. In this study, we present the results of three splitting methods, discuss the motivations behind their validity, and report our results using all of the available subjects.
A Comprehensive Study of Alzheimer's Disease Classification Using Convolutional Neural Networks
Apr 16, 2019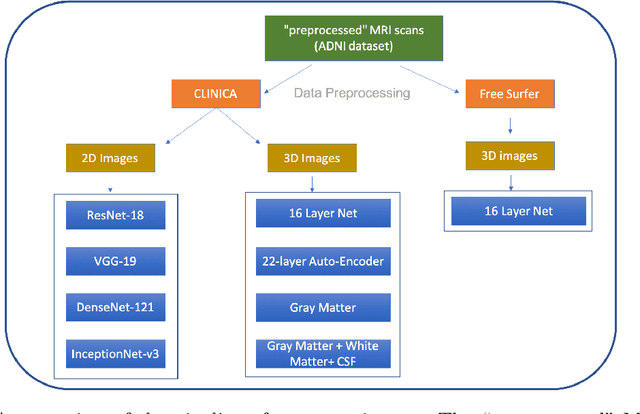
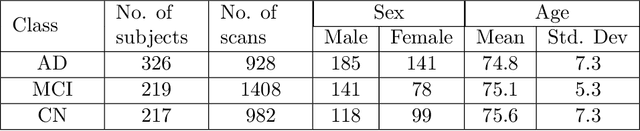
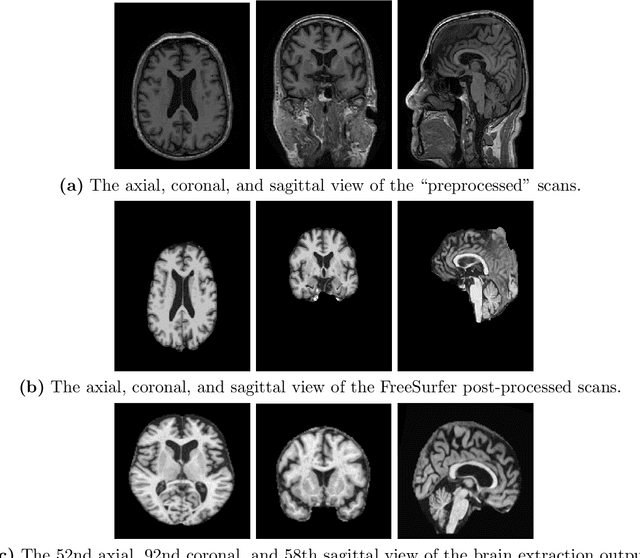
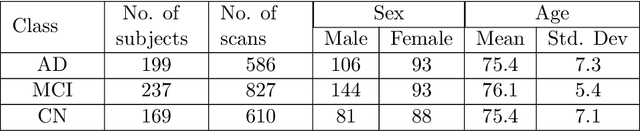
A plethora of deep learning models have been developed for the task of Alzheimer's disease classification from brain MRI scans. Many of these models report high performance, achieving three-class classification accuracy of up to 95%. However, it is common for these studies to draw performance comparisons between models that are trained on different subsets of a dataset or use varying imaging preprocessing techniques, making it difficult to objectively assess model performance. Furthermore, many of these works do not provide details such as hyperparameters, the specific MRI scans used, or their source code, making it difficult to replicate their experiments. To address these concerns, we present a comprehensive study of some of the deep learning methods and architectures on the full set of images available from ADNI. We find that, (1) classification using 3D models gives an improvement of 1% in our setup, at the cost of significantly longer training time and more computation power, (2) with our dataset, pre-training yields minimal ($<0.5\%$) improvement in model performance, (3) most popular convolutional neural network models yield similar performance when compared to each other. Lastly, we briefly compare the effects of two image preprocessing programs: FreeSurfer and Clinica, and find that the spatially normalized and segmented outputs from Clinica increased the accuracy of model prediction from 63% to 89% when compared to FreeSurfer images.