 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Forward Indexes for Efficient Document Ranking
Paper and Code
Oct 12, 2021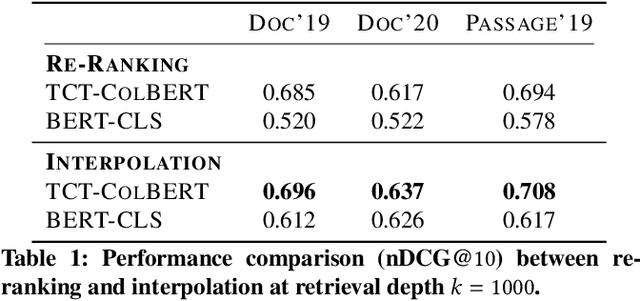

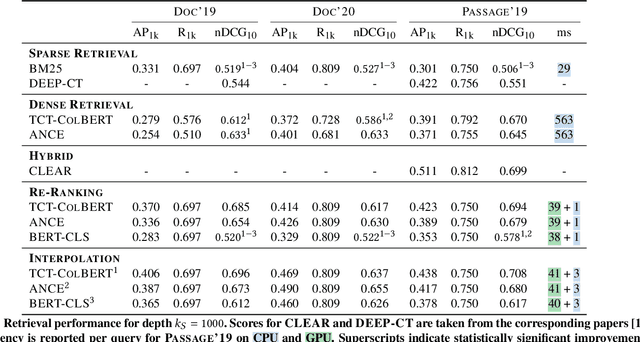
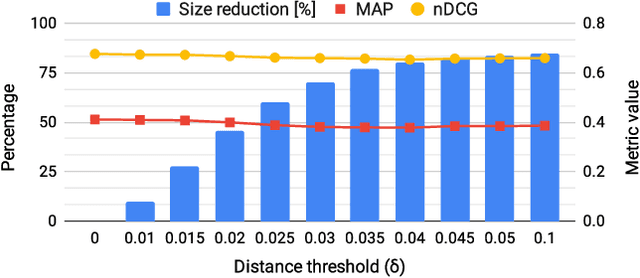
Neural approaches, specifically transformer models, for ranking documents have delivered impressive gains in ranking performance. However, query processing using such over-parameterized models is both resource and time intensive. Consequently, to keep query processing costs manageable, trade-offs are made to reduce the number of documents to be re-ranked or consider leaner models with fewer parameters. In this paper, we propose the fast-forward index -- a simple vector forward index that facilitates ranking documents using interpolation-based ranking models. Fast-forward indexes pre-compute the dense transformer-based vector representations of documents and passages for fast CPU-based semantic similarity computation during query processing. We propose theoretically grounded index pruning and early stopping techniques to improve the query-processing throughput using fast-forward indexes. We conduct extensive large-scale experiments over the TREC-DL datasets and show up to 75% improvement in query-processing performance over hybrid indexes using only CPUs. Along with the efficiency benefits, we show that fast-forward indexes can deliver superior ranking performance due to the complementary benefits of interpolation between lexical and semantic similarities.