 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Surprising Effectiveness of Rankers Trained on Expanded Queries
Paper and Code
Apr 03, 2024
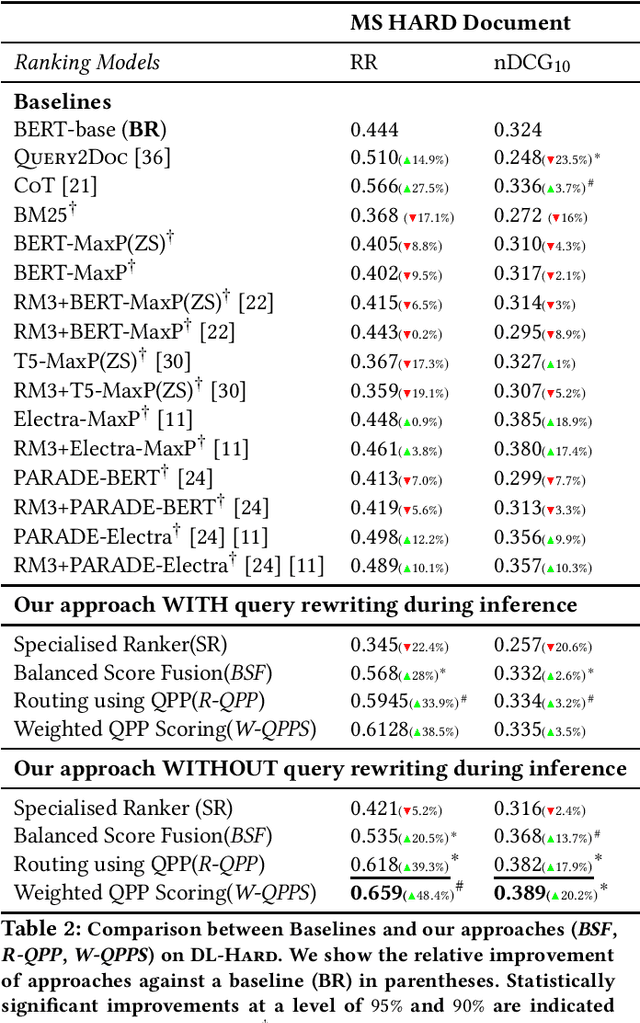
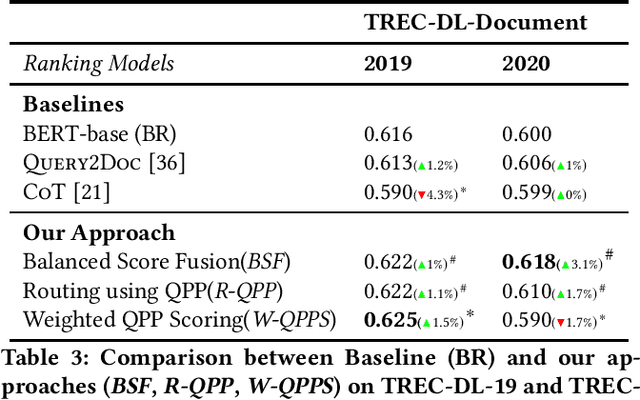
An important problem in text-ranking systems is handling the hard queries that form the tail end of the query distribution. The difficulty may arise due to the presence of uncommon, underspecified, or incomplete queries. In this work, we improve the ranking performance of hard or difficult queries without compromising the performance of other queries. Firstly, we do LLM based query enrichment for training queries using relevant documents. Next, a specialized ranker is fine-tuned only on the enriched hard queries instead of the original queries. We combine the relevance scores from the specialized ranker and the base ranker, along with a query performance score estimated for each query. Our approach departs from existing methods that usually employ a single ranker for all queries, which is biased towards easy queries, which form the majority of the query distribution. In our extensive experiments on the DL-Hard dataset, we find that a principled query performance based scoring method using base and specialized ranker offers a significant improvement of up to 25% on the passage ranking task and up to 48.4% on the document ranking task when compared to the baseline performance of using original queries, even outperforming SOTA model.