 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenger-Based Combinatorial Bandits for Subcarrier Selection in OFDM Systems
Oct 06, 2025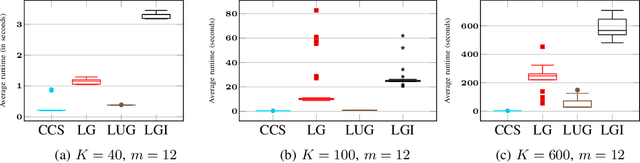
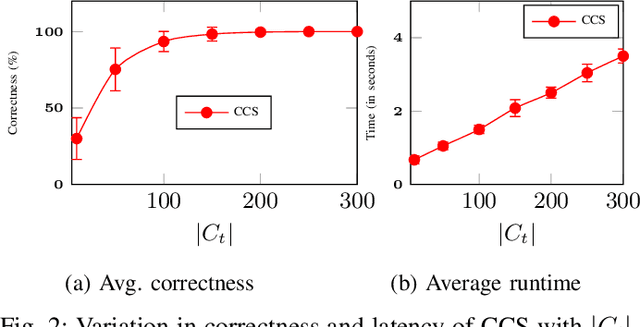

This paper investigates the identification of the top-m user-scheduling sets in multi-user MIMO downlink, which is cast as a combinatorial pure-exploration problem in stochastic linear bandits. Because the action space grows exponentially, exhaustive search is infeasible. We therefore adopt a linear utility model to enable efficient exploration and reliable selection of promising user subsets. We introduce a gap-index framework that maintains a shortlist of current estimates of champion arms (top-m sets) and a rotating shortlist of challenger arms that pose the greatest threat to the champions. This design focuses on measurements that yield the most informative gap-index-based comparisons, resulting in significant reductions in runtime and computation compared to state-of-the-art linear bandit methods, with high identification accuracy. The method also exposes a tunable trade-off between speed and accuracy. Simulations on a realistic OFDM downlink show that shortlist-driven pure exploration makes online, measurement-efficient subcarrier selection practical for AI-enabled communication systems.
Think Right, Not More: Test-Time Scaling for Numerical Claim Verification
Sep 26, 2025



Fact-checking real-world claims, particularly numerical claims, is inherently complex that require multistep reasoning and numerical reasoning for verifying diverse aspects of the claim. Although large language models (LLMs) including reasoning models have made tremendous advances, they still fall short on fact-checking real-world claims that require a combination of compositional and numerical reasoning. They are unable to understand nuance of numerical aspects, and are also susceptible to the reasoning drift issue, where the model is unable to contextualize diverse information resulting in misinterpretation and backtracking of reasoning process. In this work, we systematically explore scaling test-time compute (TTS) for LLMs on the task of fact-checking complex numerical claims, which entails eliciting multiple reasoning paths from an LLM. We train a verifier model (VERIFIERFC) to navigate this space of possible reasoning paths and select one that could lead to the correct verdict. We observe that TTS helps mitigate the reasoning drift issue, leading to significant performance gains for fact-checking numerical claims. To improve compute efficiency in TTS, we introduce an adaptive mechanism that performs TTS selectively based on the perceived complexity of the claim. This approach achieves 1.8x higher efficiency than standard TTS, while delivering a notable 18.8% performance improvement over single-shot claim verification methods. Our code and data can be found at https://github.com/VenkteshV/VerifierFC
Sample Efficient Demonstration Selection for In-Context Learning
Jun 10, 2025The in-context learning paradigm with LLMs has been instrumental in advancing a wide range of natural language processing tasks. The selection of few-shot examples (exemplars / demonstration samples) is essential for constructing effective prompts under context-length budget constraints. In this paper, we formulate the exemplar selection task as a top-m best arms identification problem. A key challenge in this setup is the exponentially large number of arms that need to be evaluated to identify the m-best arms. We propose CASE (Challenger Arm Sampling for Exemplar selection), a novel sample-efficient selective exploration strategy that maintains a shortlist of "challenger" arms, which are current candidates for the top-m arms. In each iteration, only one of the arms from this shortlist or the current topm set is pulled, thereby reducing sample complexity and, consequently, the number of LLM evaluations. Furthermore, we model the scores of exemplar subsets (arms) using a parameterized linear scoring function, leading to stochastic linear bandits setting. CASE achieves remarkable efficiency gains of up to 7x speedup in runtime while requiring 7x fewer LLM calls (87% reduction) without sacrificing performance compared to state-of-the-art exemplar selection methods. We release our code and data at https://github.com/kiranpurohit/CASE
Understanding the User: An Intent-Based Ranking Dataset
Aug 30, 2024As information retrieval systems continue to evolve, accurate evaluation and benchmarking of these systems become pivotal. Web search datasets, such as MS MARCO, primarily provide short keyword queries without accompanying intent or descriptions, posing a challenge in comprehending the underlying information need. This paper proposes an approach to augmenting such datasets to annotate informative query descriptions, with a focus on two prominent benchmark datasets: TREC-DL-21 and TREC-DL-22. Our methodology involves utilizing state-of-the-art LLMs to analyze and comprehend the implicit intent within individual queries from benchmark datasets. By extracting key semantic elements, we construct detailed and contextually rich descriptions for these queries. To validate the generated query descriptions, we employ crowdsourcing as a reliable means of obtaining diverse human perspectives on the accuracy and informativeness of the descriptions. This information can be used as an evaluation set for tasks such as ranking, query rewriting, or others.