 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Ultra: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Jun 12, 2026We introduce Nemotron 3 Ultra, a 550 billion total and 55 billion active parameter Mixture-of-Experts Hybrid Mamba-Attention language model. We pre-trained Nemotron 3 Ultra on 20 trillion text tokens, then extended the context length to 1M tokens, and post-trained using Supervised Fine Tuning (SFT), Reinforcement Learning (RL), and Multi-teacher On-Policy Distillation (MOPD). Nemotron 3 Ultra is our most capable model yet, employing multiple key technologies - LatentMoE, Multi Token Prediction (MTP), NVFP4 pre-training, multi-environment RLVR, MOPD, and reasoning budget control. Nemotron 3 Ultra achieves up to ~6x higher inference throughput as compared to state-of-the-art publicly available LLMs while attaining on-par accuracy. The state-of-the-art accuracy, high inference throughput, and 1M token context length make Nemotron 3 Ultra ideal for long-running autonomous agentic tasks. We open-source the base, post-trained, and quantized checkpoints, along with the training data and recipe on HuggingFace.
Nemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
PivotRL: High Accuracy Agentic Post-Training at Low Compute Cost
Mar 22, 2026Post-training for long-horizon agentic tasks has a tension between compute efficiency and generalization. While supervised fine-tuning (SFT) is compute efficient, it often suffers from out-of-domain (OOD) degradation. Conversely, end-to-end reinforcement learning (E2E RL) preserves OOD capabilities, but incurs high compute costs due to many turns of on-policy rollout. We introduce PivotRL, a novel framework that operates on existing SFT trajectories to combine the compute efficiency of SFT with the OOD accuracy of E2E RL. PivotRL relies on two key mechanisms: first, it executes local, on-policy rollouts and filters for pivots: informative intermediate turns where sampled actions exhibit high variance in outcomes; second, it utilizes rewards for functional-equivalent actions rather than demanding strict string matching with the SFT data demonstration. We theoretically show that these mechanisms incentivize strong learning signals with high natural gradient norm, while maximally preserving policy probability ordering on actions unrelated to training tasks. In comparison to standard SFT on identical data, we demonstrate that PivotRL achieves +4.17% higher in-domain accuracy on average across four agentic domains, and +10.04% higher OOD accuracy in non-agentic tasks. Notably, on agentic coding tasks, PivotRL achieves competitive accuracy with E2E RL with 4x fewer rollout turns. PivotRL is adopted by NVIDIA's Nemotron-3-Super-120B-A12B, acting as the workhorse in production-scale agentic post-training.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
Development of Cognitive Intelligence in Pre-trained Language Models
Jul 01, 2024Recent studies show evidence for emergent cognitive abilities in Large Pre-trained Language Models (PLMs). The increasing cognitive alignment of these models has made them candidates for cognitive science theories. Prior research into the emergent cognitive abilities of PLMs has largely been path-independent to model training, i.e., has focused on the final model weights and not the intermediate steps. However, building plausible models of human cognition using PLMs would benefit from considering the developmental alignment of their performance during training to the trajectories of children's thinking. Guided by psychometric tests of human intelligence, we choose four sets of tasks to investigate the alignment of ten popular families of PLMs and evaluate their available intermediate and final training steps. These tasks are Numerical ability, Linguistic abilities, Conceptual understanding, and Fluid reasoning. We find a striking regularity: regardless of model size, the developmental trajectories of PLMs consistently exhibit a window of maximal alignment to human cognitive development. Before that window, training appears to endow "blank slate" models with the requisite structure to be poised to rapidly learn from experience. After that window, training appears to serve the engineering goal of reducing loss but not the scientific goal of increasing alignment with human cognition.
Pre-training LLMs using human-like development data corpus
Nov 18, 2023
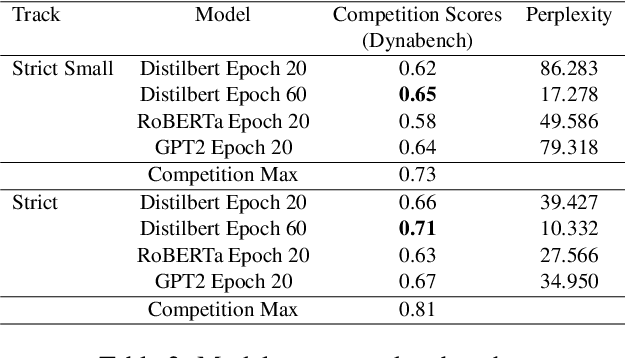


Pre-trained Large Language Models (LLMs) have shown success in a diverse set of language inference and understanding tasks. The pre-training stage of LLMs looks at a large corpus of raw textual data. The BabyLM shared task compares LLM pre-training to human language acquisition, where the number of tokens seen by 13-year-old kids is magnitudes smaller than the number of tokens seen by LLMs. In this work, we pre-train and evaluate LLMs on their ability to learn contextual word representations using roughly the same number of tokens as seen by children. We provide a strong set of baselines; with different architectures, evaluation of changes in performance across epochs, and reported pre-training metrics for the strict small and strict tracks of the task. We also try to loosely replicate the RoBERTa baseline given by the task organizers to observe the training robustness to hyperparameter selection and replicability. We provide the submission details to the strict and strict-small tracks in this report.
Numeric Magnitude Comparison Effects in Large Language Models
May 18, 2023



Large Language Models (LLMs) do not differentially represent numbers, which are pervasive in text. In contrast, neuroscience research has identified distinct neural representations for numbers and words. In this work, we investigate how well popular LLMs capture the magnitudes of numbers (e.g., that $4 < 5$) from a behavioral lens. Prior research on the representational capabilities of LLMs evaluates whether they show human-level performance, for instance, high overall accuracy on standard benchmarks. Here, we ask a different question, one inspired by cognitive science: How closely do the number representations of LLMscorrespond to those of human language users, who typically demonstrate the distance, size, and ratio effects? We depend on a linking hypothesis to map the similarities among the model embeddings of number words and digits to human response times. The results reveal surprisingly human-like representations across language models of different architectures, despite the absence of the neural circuitry that directly supports these representations in the human brain. This research shows the utility of understanding LLMs using behavioral benchmarks and points the way to future work on the number of representations of LLMs and their cognitive plausibility.