 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Well Do Deep Learning Models Capture Human Concepts? The Case of the Typicality Effect
May 25, 2024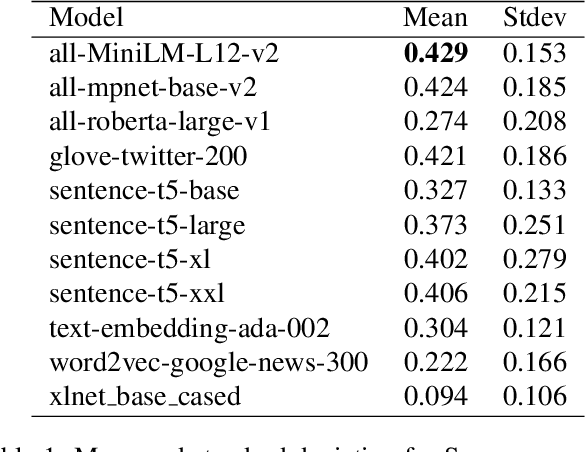
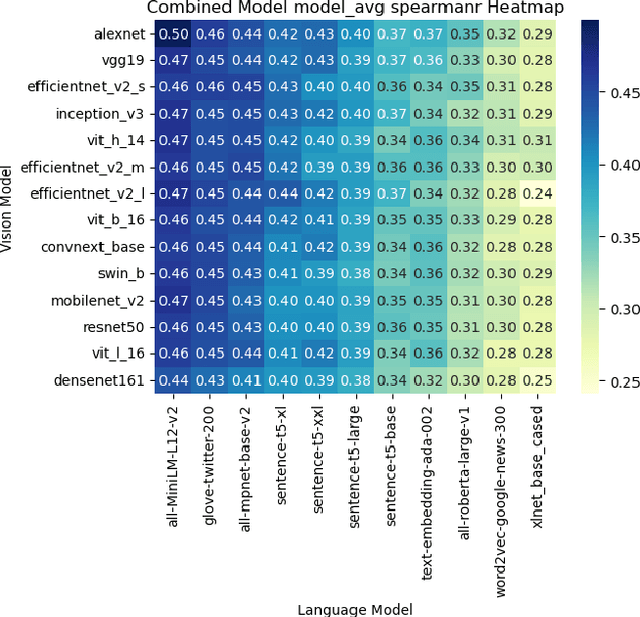
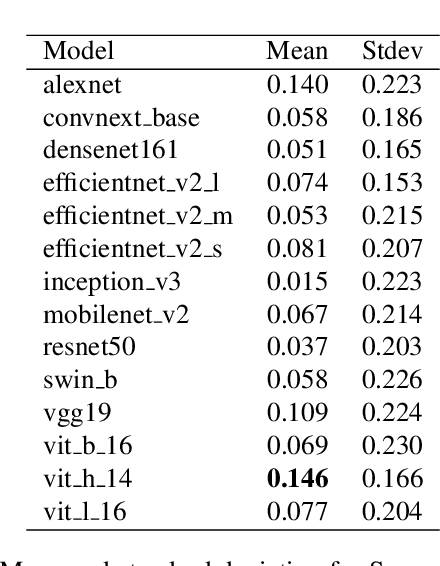
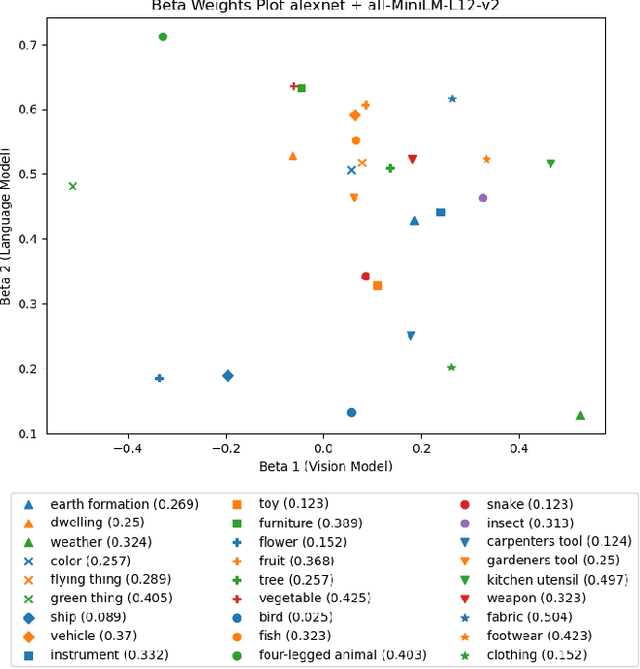
How well do representations learned by ML models align with those of humans? Here, we consider concept representations learned by deep learning models and evaluate whether they show a fundamental behavioral signature of human concepts, the typicality effect. This is the finding that people judge some instances (e.g., robin) of a category (e.g., Bird) to be more typical than others (e.g., penguin). Recent research looking for human-like typicality effects in language and vision models has focused on models of a single modality, tested only a small number of concepts, and found only modest correlations with human typicality ratings. The current study expands this behavioral evaluation of models by considering a broader range of language (N = 8) and vision (N = 10) model architectures. It also evaluates whether the combined typicality predictions of vision + language model pairs, as well as a multimodal CLIP-based model, are better aligned with human typicality judgments than those of models of either modality alone. Finally, it evaluates the models across a broader range of concepts (N = 27) than prior studies. There were three important findings. First, language models better align with human typicality judgments than vision models. Second, combined language and vision models (e.g., AlexNet + MiniLM) better predict the human typicality data than the best-performing language model (i.e., MiniLM) or vision model (i.e., ViT-Huge) alone. Third, multimodal models (i.e., CLIP ViT) show promise for explaining human typicality judgments. These results advance the state-of-the-art in aligning the conceptual representations of ML models and humans. A methodological contribution is the creation of a new image set for testing the conceptual alignment of vision models.