 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs generate structurally realistic social networks but overestimate political homophily
Aug 29, 2024
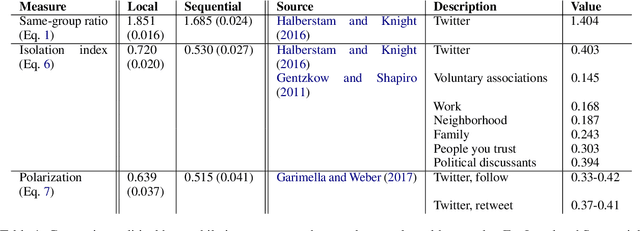


Generating social networks is essential for many applications, such as epidemic modeling and social simulations. Prior approaches either involve deep learning models, which require many observed networks for training, or stylized models, which are limited in their realism and flexibility. In contrast, LLMs offer the potential for zero-shot and flexible network generation. However, two key questions are: (1) are LLM's generated networks realistic, and (2) what are risks of bias, given the importance of demographics in forming social ties? To answer these questions, we develop three prompting methods for network generation and compare the generated networks to real social networks. We find that more realistic networks are generated with "local" methods, where the LLM constructs relations for one persona at a time, compared to "global" methods that construct the entire network at once. We also find that the generated networks match real networks on many characteristics, including density, clustering, community structure, and degree. However, we find that LLMs emphasize political homophily over all other types of homophily and overestimate political homophily relative to real-world measures.
Multi-Level Feedback Generation with Large Language Models for Empowering Novice Peer Counselors
Mar 21, 2024Realistic practice and tailored feedback are key processes for training peer counselors with clinical skills. However, existing mechanisms of providing feedback largely rely on human supervision. Peer counselors often lack mechanisms to receive detailed feedback from experienced mentors, making it difficult for them to support the large number of people with mental health issues who use peer counseling. Our work aims to leverage large language models to provide contextualized and multi-level feedback to empower peer counselors, especially novices, at scale. To achieve this, we co-design with a group of senior psychotherapy supervisors to develop a multi-level feedback taxonomy, and then construct a publicly available dataset with comprehensive feedback annotations of 400 emotional support conversations. We further design a self-improvement method on top of large language models to enhance the automatic generation of feedback. Via qualitative and quantitative evaluation with domain experts, we demonstrate that our method minimizes the risk of potentially harmful and low-quality feedback generation which is desirable in such high-stakes scenarios.
Is Task-Agnostic Explainable AI a Myth?
Jul 13, 2023Our work serves as a framework for unifying the challenges of contemporary explainable AI (XAI). We demonstrate that while XAI methods provide supplementary and potentially useful output for machine learning models, researchers and decision-makers should be mindful of their conceptual and technical limitations, which frequently result in these methods themselves becoming black boxes. We examine three XAI research avenues spanning image, textual, and graph data, covering saliency, attention, and graph-type explainers. Despite the varying contexts and timeframes of the mentioned cases, the same persistent roadblocks emerge, highlighting the need for a conceptual breakthrough in the field to address the challenge of compatibility between XAI methods and application tasks.