 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext vs Target Word: Quantifying Biases in Lexical Semantic Datasets
Dec 13, 2021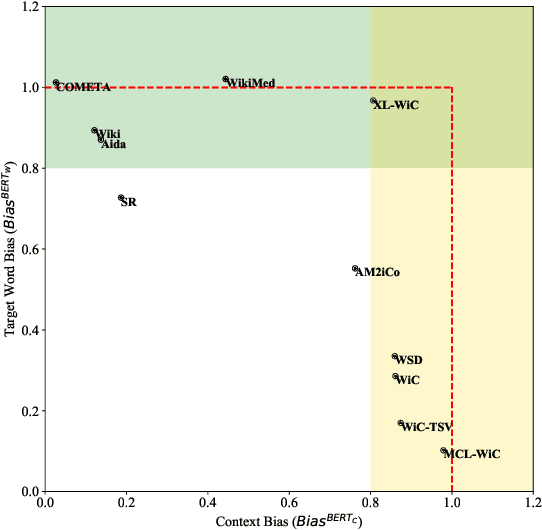


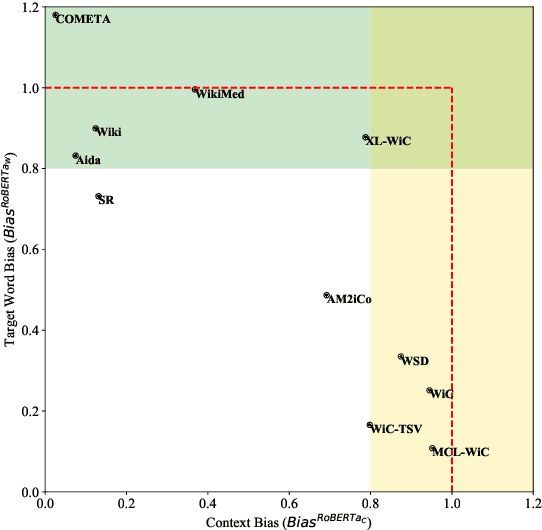
State-of-the-art contextualized models such as BERT use tasks such as WiC and WSD to evaluate their word-in-context representations. This inherently assumes that performance in these tasks reflect how well a model represents the coupled word and context semantics. This study investigates this assumption by presenting the first quantitative analysis (using probing baselines) on the context-word interaction being tested in major contextual lexical semantic tasks. Specifically, based on the probing baseline performance, we propose measures to calculate the degree of context or word biases in a dataset, and plot existing datasets on a continuum. The analysis shows most existing datasets fall into the extreme ends of the continuum (i.e. they are either heavily context-biased or target-word-biased) while only AM$^2$iCo and Sense Retrieval challenge a model to represent both the context and target words. Our case study on WiC reveals that human subjects do not share models' strong context biases in the dataset (humans found semantic judgments much more difficult when the target word is missing) and models are learning spurious correlations from context alone. This study demonstrates that models are usually not being tested for word-in-context representations as such in these tasks and results are therefore open to misinterpretation. We recommend our framework as sanity check for context and target word biases of future task design and application in lexical semantics.
AM2iCo: Evaluating Word Meaning in Context across Low-ResourceLanguages with Adversarial Examples
Apr 17, 2021
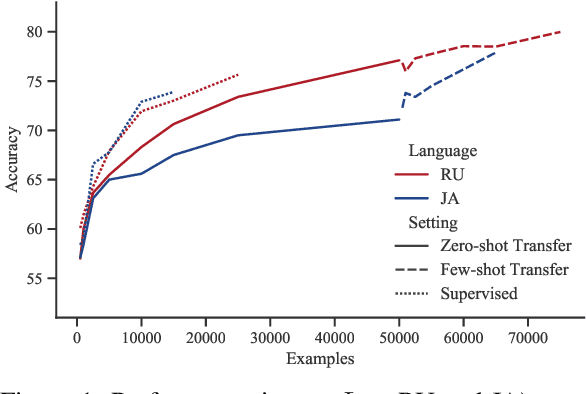


Capturing word meaning in context and distinguishing between correspondences and variations across languages is key to building successful multilingual and cross-lingual text representation models. However, existing multilingual evaluation datasets that evaluate lexical semantics "in-context" have various limitations, in particular, (1) their language coverage is restricted to high-resource languages and skewed in favor of only a few language families and areas, (2) a design that makes the task solvable via superficial cues, which results in artificially inflated (and sometimes super-human) performances of pretrained encoders, on many target languages, which limits their usefulness for model probing and diagnostics, and (3) no support for cross-lingual evaluation. In order to address these gaps, we present AM2iCo, Adversarial and Multilingual Meaning in Context, a wide-coverage cross-lingual and multilingual evaluation set; it aims to faithfully assess the ability of state-of-the-art (SotA) representation models to understand the identity of word meaning in cross-lingual contexts for 14 language pairs. We conduct a series of experiments in a wide range of setups and demonstrate the challenging nature of AM2iCo. The results reveal that current SotA pretrained encoders substantially lag behind human performance, and the largest gaps are observed for low-resource languages and languages dissimilar to English.