 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVersatile Volumetric Medical Image Coding for Human-Machine Vision
Paper and Code
Dec 12, 2024
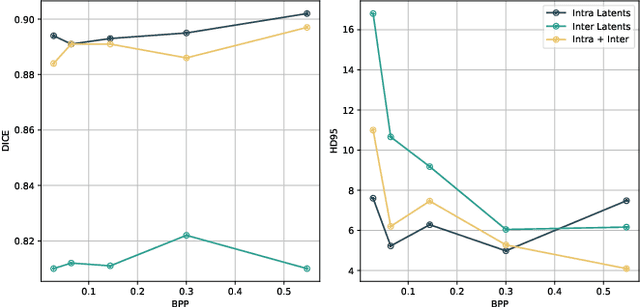
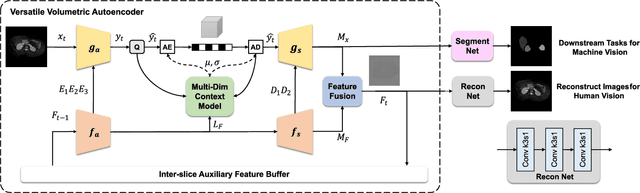
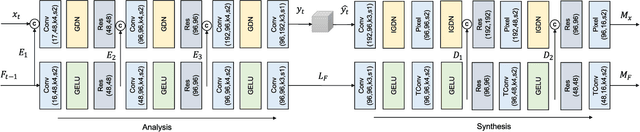
Neural image compression (NIC) has received considerable attention due to its significant advantages in feature representation and data optimization. However, most existing NIC methods for volumetric medical images focus solely on improving human-oriented perception. For these methods, data need to be decoded back to pixels for downstream machine learning analytics, which is a process that lowers the efficiency of diagnosis and treatment in modern digital healthcare scenarios. In this paper, we propose a Versatile Volumetric Medical Image Coding (VVMIC) framework for both human and machine vision, enabling various analytics of coded representations directly without decoding them into pixels. Considering the specific three-dimensional structure distinguished from natural frame images, a Versatile Volumetric Autoencoder (VVAE) module is crafted to learn the inter-slice latent representations to enhance the expressiveness of the current-slice latent representations, and to produce intermediate decoding features for downstream reconstruction and segmentation tasks. To further improve coding performance, a multi-dimensional context model is assembled by aggregating the inter-slice latent context with the spatial-channel context and the hierarchical hypercontext. Experimental results show that our VVMIC framework maintains high-quality image reconstruction for human vision while achieving accurate segmentation results for machine-vision tasks compared to a number of reported traditional and neural methods.