 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplying Ensemble Models based on Graph Neural Network and Reinforcement Learning for Wind Power Forecasting
Jan 28, 2025



Accurately predicting the wind power output of a wind farm across various time scales utilizing Wind Power Forecasting (WPF) is a critical issue in wind power trading and utilization. The WPF problem remains unresolved due to numerous influencing variables, such as wind speed, temperature, latitude, and longitude. Furthermore, achieving high prediction accuracy is crucial for maintaining electric grid stability and ensuring supply security. In this paper, we model all wind turbines within a wind farm as graph nodes in a graph built by their geographical locations. Accordingly, we propose an ensemble model based on graph neural networks and reinforcement learning (EMGRL) for WPF. Our approach includes: (1) applying graph neural networks to capture the time-series data from neighboring wind farms relevant to the target wind farm; (2) establishing a general state embedding that integrates the target wind farm's data with the historical performance of base models on the target wind farm; (3) ensembling and leveraging the advantages of all base models through an actor-critic reinforcement learning framework for WPF.
A Stochastic Composite Augmented Lagrangian Method For Reinforcement Learning
May 20, 2021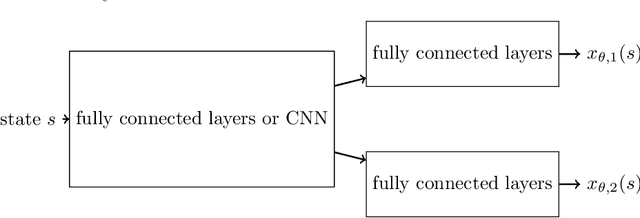
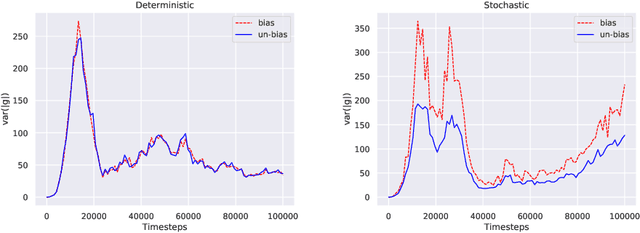
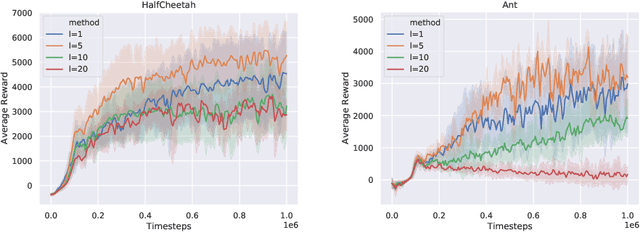
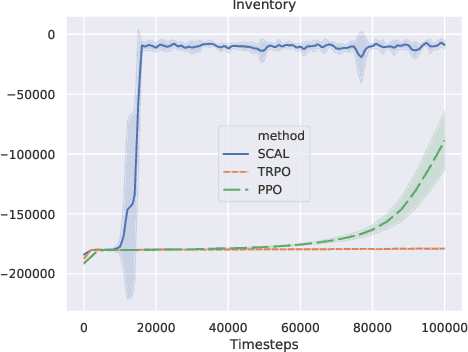
In this paper, we consider the linear programming (LP) formulation for deep reinforcement learning. The number of the constraints depends on the size of state and action spaces, which makes the problem intractable in large or continuous environments. The general augmented Lagrangian method suffers the double-sampling obstacle in solving the LP. Namely, the conditional expectations originated from the constraint functions and the quadratic penalties in the augmented Lagrangian function impose difficulties in sampling and evaluation. Motivated from the updates of the multipliers, we overcome the obstacles in minimizing the augmented Lagrangian function by replacing the intractable conditional expectations with the multipliers. Therefore, a deep parameterized augment Lagrangian method is proposed. Furthermore, the replacement provides a promising breakthrough to integrate the two steps in the augmented Lagrangian method into a single constrained problem. A general theoretical analysis shows that the solutions generated from a sequence of the constrained optimizations converge to the optimal solution of the LP if the error is controlled properly. A theoretical analysis on the quadratic penalty algorithm under neural tangent kernel setting shows the residual can be arbitrarily small if the parameter in network and optimization algorithm is chosen suitably. Preliminary experiments illustrate that our method is competitive to other state-of-the-art algorithms.
Structured Stochastic Quasi-Newton Methods for Large-Scale Optimization Problems
Jun 17, 2020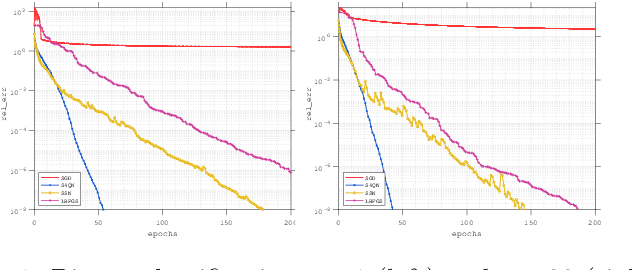

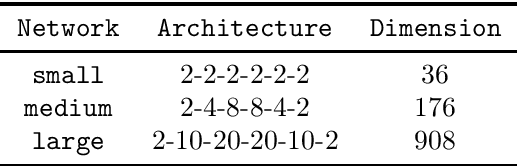
In this paper, we consider large-scale finite-sum nonconvex problems arising from machine learning. Since the Hessian is often a summation of a relative cheap and accessible part and an expensive or even inaccessible part, a stochastic quasi-Newton matrix is constructed using partial Hessian information as much as possible. By further exploiting the low-rank structures based on the Nystr\"om approximation, the computation of the quasi-Newton direction is affordable. To make full use of the gradient estimation, we also develop an extra-step strategy for this framework. Global convergence to stationary point in expectation and local suplinear convergence rate are established under some mild assumptions. Numerical experiments on logistic regression, deep autoencoder networks and deep learning problems show that the efficiency of our proposed method is at least comparable with the state-of-the-art methods.
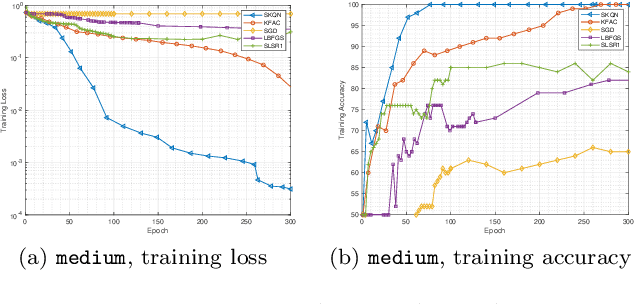
Sketchy Empirical Natural Gradient Methods for Deep Learning
Jun 16, 2020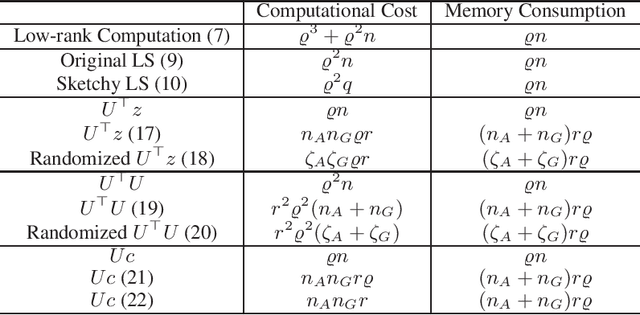
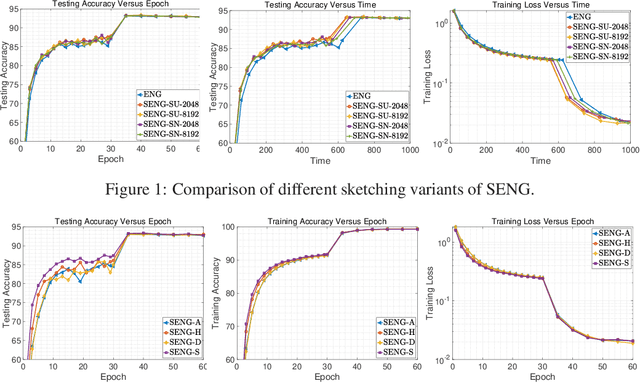
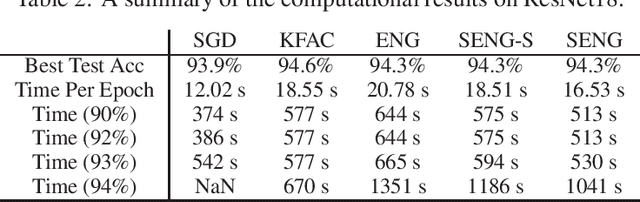
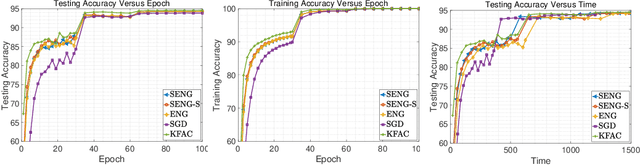
In this paper, we develop an efficient sketchy empirical natural gradient method for large-scale finite-sum optimization problems from deep learning. The empirical Fisher information matrix is usually low-rank since the sampling is only practical on a small amount of data at each iteration. Although the corresponding natural gradient direction lies in a small subspace, both the computational cost and memory requirement are still not tractable due to the curse of dimensionality. We design randomized techniques for different neural network structures to resolve these challenges. For layers with a reasonable dimension, a sketching can be performed on a regularized least squares subproblem. Otherwise, since the gradient is a vectorization of the product between two matrices, we apply sketching on low-rank approximation of these matrices to compute the most expensive parts. Global convergence to stationary point is established under some mild assumptions. Numerical results on deep convolution networks illustrate that our method is quite competitive to the state-of-the-art methods such as SGD and KFAC.