 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Pretraining with Classification Labels for Temporal Activity Detection
Paper and Code
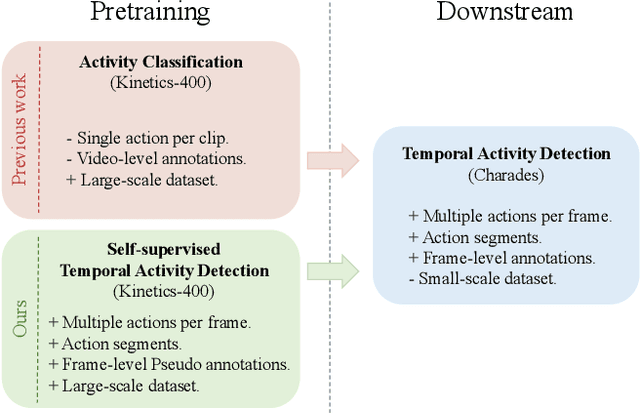
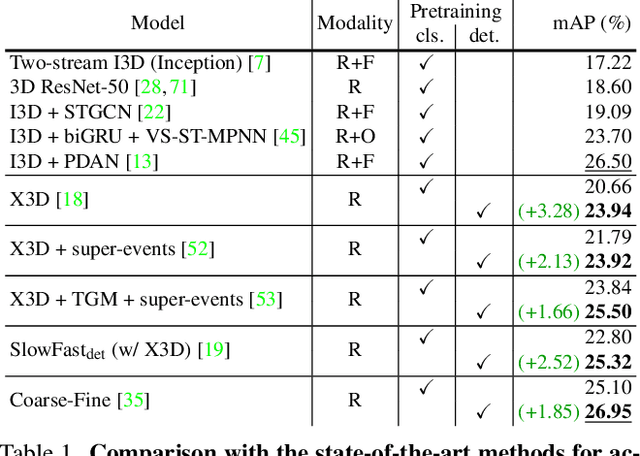
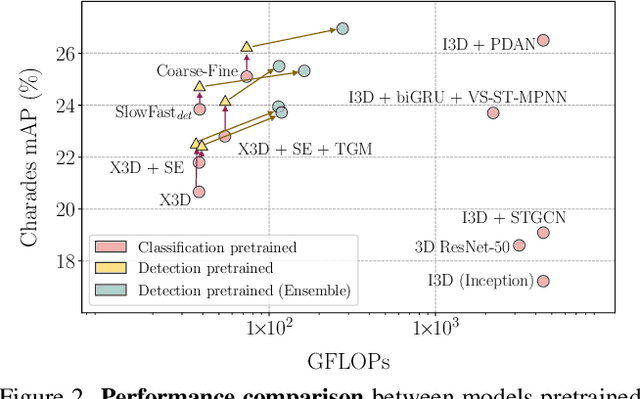
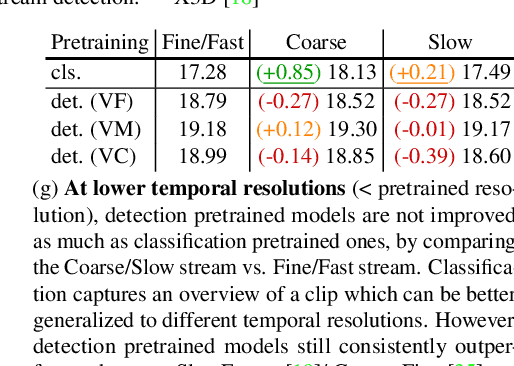
Temporal Activity Detection aims to predict activity classes per frame, in contrast to video-level predictions as done in Activity Classification (i.e., Activity Recognition). Due to the expensive frame-level annotations required for detection, the scale of detection datasets is limited. Thus, commonly, previous work on temporal activity detection resorts to fine-tuning a classification model pretrained on large-scale classification datasets (e.g., Kinetics-400). However, such pretrained models are not ideal for downstream detection performance due to the disparity between the pretraining and the downstream fine-tuning tasks. This work proposes a novel self-supervised pretraining method for detection leveraging classification labels to mitigate such disparity by introducing frame-level pseudo labels, multi-action frames, and action segments. We show that the models pretrained with the proposed self-supervised detection task outperform prior work on multiple challenging activity detection benchmarks, including Charades and MultiTHUMOS. Our extensive ablations further provide insights on when and how to use the proposed models for activity detection. Code and models will be released online.