 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamics via Graph Neural Networks for Human Pose Estimation and Tracking
Paper and Code
Jun 07, 2021
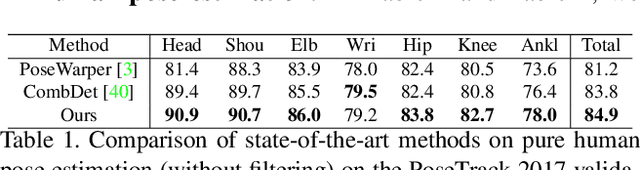
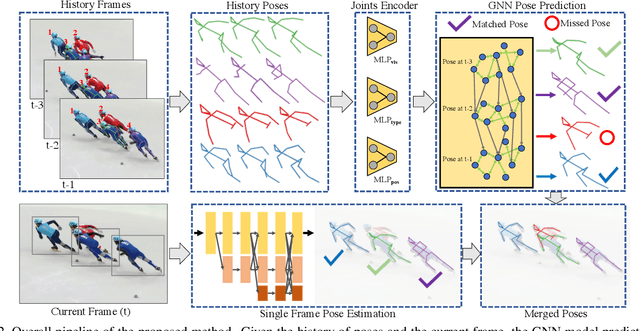
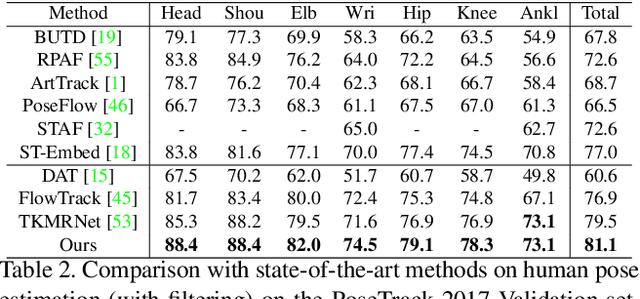
Multi-person pose estimation and tracking serve as crucial steps for video understanding. Most state-of-the-art approaches rely on first estimating poses in each frame and only then implementing data association and refinement. Despite the promising results achieved, such a strategy is inevitably prone to missed detections especially in heavily-cluttered scenes, since this tracking-by-detection paradigm is, by nature, largely dependent on visual evidences that are absent in the case of occlusion. In this paper, we propose a novel online approach to learning the pose dynamics, which are independent of pose detections in current fame, and hence may serve as a robust estimation even in challenging scenarios including occlusion. Specifically, we derive this prediction of dynamics through a graph neural network~(GNN) that explicitly accounts for both spatial-temporal and visual information. It takes as input the historical pose tracklets and directly predicts the corresponding poses in the following frame for each tracklet. The predicted poses will then be aggregated with the detected poses, if any, at the same frame so as to produce the final pose, potentially recovering the occluded joints missed by the estimator. Experiments on PoseTrack 2017 and PoseTrack 2018 datasets demonstrate that the proposed method achieves results superior to the state of the art on both human pose estimation and tracking tasks.