 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the nonlinear correlation of ML performance between data subpopulations
May 04, 2023Understanding the performance of machine learning (ML) models across diverse data distributions is critically important for reliable applications. Despite recent empirical studies positing a near-perfect linear correlation between in-distribution (ID) and out-of-distribution (OOD) accuracies, we empirically demonstrate that this correlation is more nuanced under subpopulation shifts. Through rigorous experimentation and analysis across a variety of datasets, models, and training epochs, we demonstrate that OOD performance often has a nonlinear correlation with ID performance in subpopulation shifts. Our findings, which contrast previous studies that have posited a linear correlation in model performance during distribution shifts, reveal a "moon shape" correlation (parabolic uptrend curve) between the test performance on the majority subpopulation and the minority subpopulation. This non-trivial nonlinear correlation holds across model architectures, hyperparameters, training durations, and the imbalance between subpopulations. Furthermore, we found that the nonlinearity of this "moon shape" is causally influenced by the degree of spurious correlations in the training data. Our controlled experiments show that stronger spurious correlation in the training data creates more nonlinear performance correlation. We provide complementary experimental and theoretical analyses for this phenomenon, and discuss its implications for ML reliability and fairness. Our work highlights the importance of understanding the nonlinear effects of model improvement on performance in different subpopulations, and has the potential to inform the development of more equitable and responsible machine learning models.
GPT detectors are biased against non-native English writers
Apr 18, 2023

The rapid adoption of generative language models has brought about substantial advancements in digital communication, while simultaneously raising concerns regarding the potential misuse of AI-generated content. Although numerous detection methods have been proposed to differentiate between AI and human-generated content, the fairness and robustness of these detectors remain underexplored. In this study, we evaluate the performance of several widely-used GPT detectors using writing samples from native and non-native English writers. Our findings reveal that these detectors consistently misclassify non-native English writing samples as AI-generated, whereas native writing samples are accurately identified. Furthermore, we demonstrate that simple prompting strategies can not only mitigate this bias but also effectively bypass GPT detectors, suggesting that GPT detectors may unintentionally penalize writers with constrained linguistic expressions. Our results call for a broader conversation about the ethical implications of deploying ChatGPT content detectors and caution against their use in evaluative or educational settings, particularly when they may inadvertently penalize or exclude non-native English speakers from the global discourse.
Learning Graph Neural Networks for Image Style Transfer
Jul 24, 2022
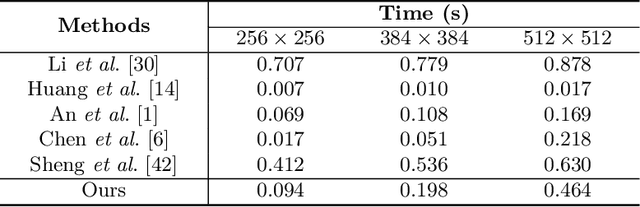
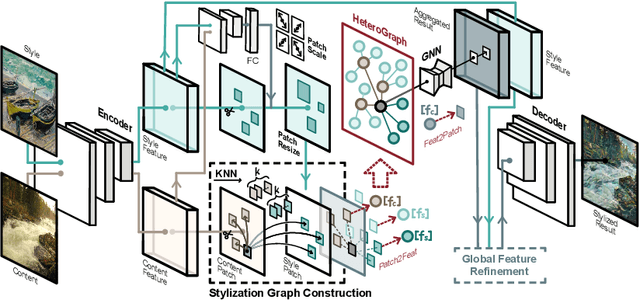

State-of-the-art parametric and non-parametric style transfer approaches are prone to either distorted local style patterns due to global statistics alignment, or unpleasing artifacts resulting from patch mismatching. In this paper, we study a novel semi-parametric neural style transfer framework that alleviates the deficiency of both parametric and non-parametric stylization. The core idea of our approach is to establish accurate and fine-grained content-style correspondences using graph neural networks (GNNs). To this end, we develop an elaborated GNN model with content and style local patches as the graph vertices. The style transfer procedure is then modeled as the attention-based heterogeneous message passing between the style and content nodes in a learnable manner, leading to adaptive many-to-one style-content correlations at the local patch level. In addition, an elaborated deformable graph convolutional operation is introduced for cross-scale style-content matching. Experimental results demonstrate that the proposed semi-parametric image stylization approach yields encouraging results on the challenging style patterns, preserving both global appearance and exquisite details. Furthermore, by controlling the number of edges at the inference stage, the proposed method also triggers novel functionalities like diversified patch-based stylization with a single model.
Safe Distillation Box
Dec 05, 2021



Knowledge distillation (KD) has recently emerged as a powerful strategy to transfer knowledge from a pre-trained teacher model to a lightweight student, and has demonstrated its unprecedented success over a wide spectrum of applications. In spite of the encouraging results, the KD process per se poses a potential threat to network ownership protection, since the knowledge contained in network can be effortlessly distilled and hence exposed to a malicious user. In this paper, we propose a novel framework, termed as Safe Distillation Box (SDB), that allows us to wrap a pre-trained model in a virtual box for intellectual property protection. Specifically, SDB preserves the inference capability of the wrapped model to all users, but precludes KD from unauthorized users. For authorized users, on the other hand, SDB carries out a knowledge augmentation scheme to strengthen the KD performances and the results of the student model. In other words, all users may employ a model in SDB for inference, but only authorized users get access to KD from the model. The proposed SDB imposes no constraints over the model architecture, and may readily serve as a plug-and-play solution to protect the ownership of a pre-trained network. Experiments across various datasets and architectures demonstrate that, with SDB, the performance of an unauthorized KD drops significantly while that of an authorized gets enhanced, demonstrating the effectiveness of SDB.