 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual Teaching: A Practical Semi-supervised Wrapper Method
Nov 12, 2016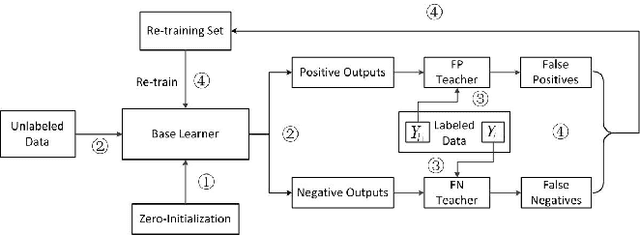
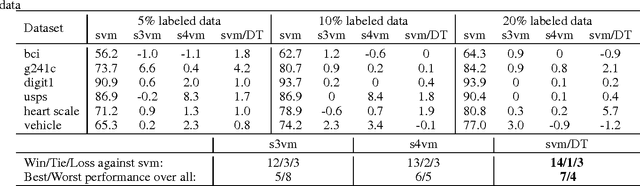

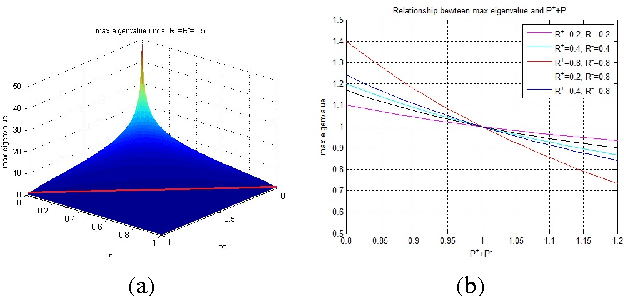
Semi-supervised wrapper methods are concerned with building effective supervised classifiers from partially labeled data. Though previous works have succeeded in some fields, it is still difficult to apply semi-supervised wrapper methods to practice because the assumptions those methods rely on tend to be unrealistic in practice. For practical use, this paper proposes a novel semi-supervised wrapper method, Dual Teaching, whose assumptions are easy to set up. Dual Teaching adopts two external classifiers to estimate the false positives and false negatives of the base learner. Only if the recall of every external classifier is greater than zero and the sum of the precision is greater than one, Dual Teaching will train a base learner from partially labeled data as effectively as the fully-labeled-data-trained classifier. The effectiveness of Dual Teaching is proved in both theory and practice.
Boost Picking: A Universal Method on Converting Supervised Classification to Semi-supervised Classification
Nov 12, 2016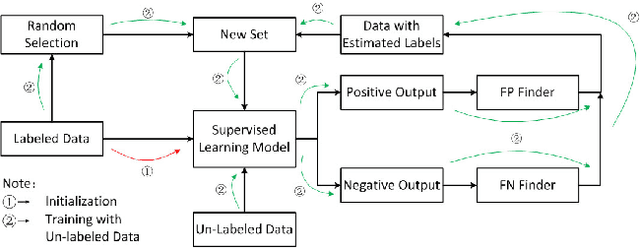
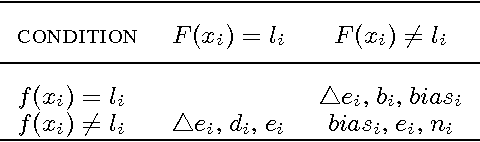
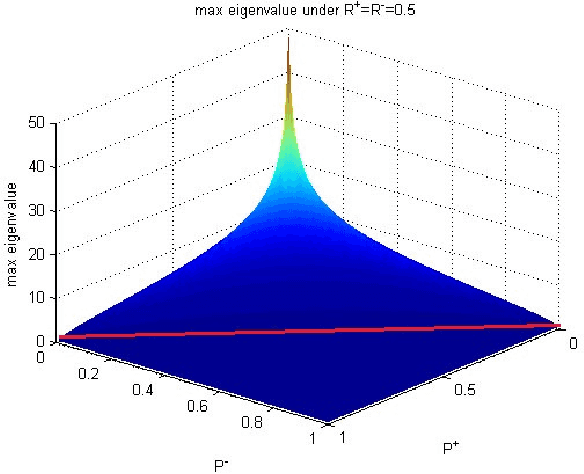

This paper proposes a universal method, Boost Picking, to train supervised classification models mainly by un-labeled data. Boost Picking only adopts two weak classifiers to estimate and correct the error. It is theoretically proved that Boost Picking could train a supervised model mainly by un-labeled data as effectively as the same model trained by 100% labeled data, only if recalls of the two weak classifiers are all greater than zero and the sum of precisions is greater than one. Based on Boost Picking, we present "Test along with Training (TawT)" to improve the generalization of supervised models. Both Boost Picking and TawT are successfully tested in varied little data sets.
Object Recognition Based on Amounts of Unlabeled Data
Mar 25, 2016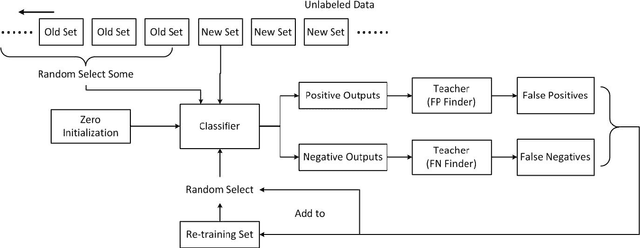

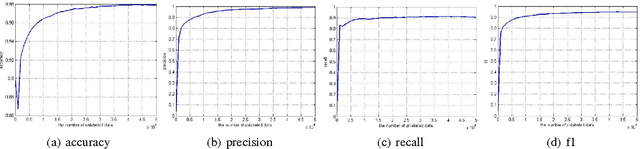
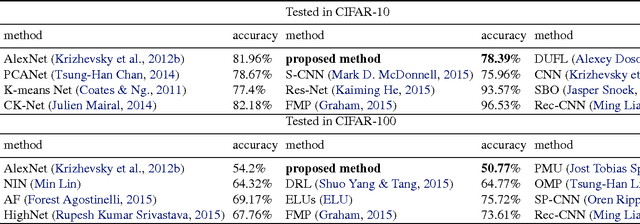
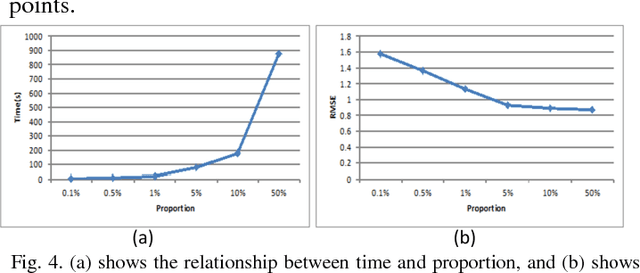
This paper proposes a novel semi-supervised method on object recognition. First, based on Boost Picking, a universal algorithm, Boost Picking Teaching (BPT), is proposed to train an effective binary-classifier just using a few labeled data and amounts of unlabeled data. Then, an ensemble strategy is detailed to synthesize multiple BPT-trained binary-classifiers to be a high-performance multi-classifier. The rationality of the strategy is also analyzed in theory. Finally, the proposed method is tested on two databases, CIFAR-10 and CIFAR-100. Using 2% labeled data and 98% unlabeled data, the accuracies of the proposed method on the two data sets are 78.39% and 50.77% respectively.
Feature-Area Optimization: A Novel SAR Image Registration Method
Feb 18, 2016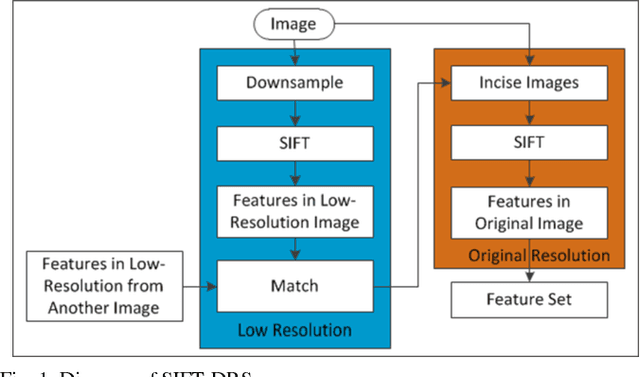
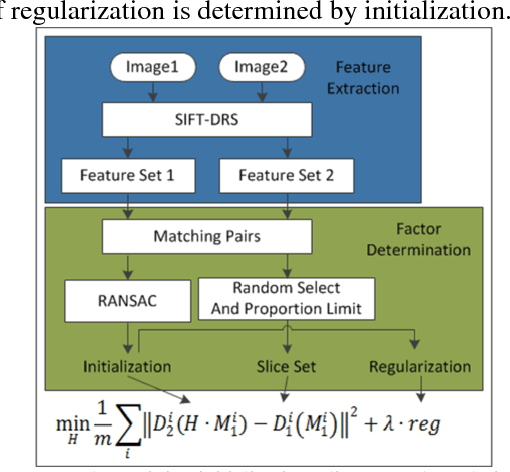
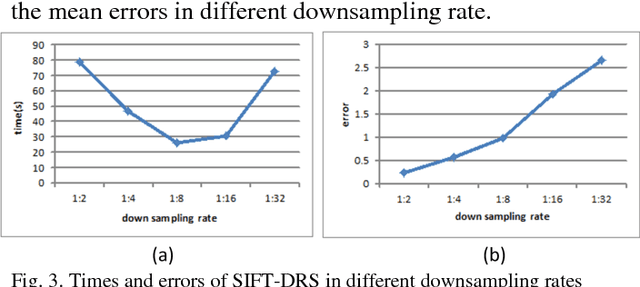
This letter proposes a synthetic aperture radar (SAR) image registration method named Feature-Area Optimization (FAO). First, the traditional area-based optimization model is reconstructed and decomposed into three key but uncertain factors: initialization, slice set and regularization. Next, structural features are extracted by scale invariant feature transform (SIFT) in dual-resolution space (SIFT-DRS), a novel SIFT-Like method dedicated to FAO. Then, the three key factors are determined based on these features. Finally, solving the factor-determined optimization model can get the registration result. A series of experiments demonstrate that the proposed method can register multi-temporal SAR images accurately and efficiently.
* 5 pages, 5 figures