 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReimagining Linear Probing: Kolmogorov-Arnold Networks in Transfer Learning
Sep 12, 2024
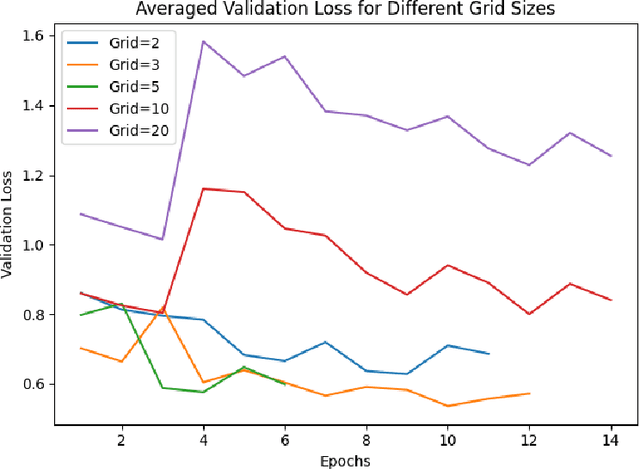


This paper introduces Kolmogorov-Arnold Networks (KAN) as an enhancement to the traditional linear probing method in transfer learning. Linear probing, often applied to the final layer of pre-trained models, is limited by its inability to model complex relationships in data. To address this, we propose substituting the linear probing layer with KAN, which leverages spline-based representations to approximate intricate functions. In this study, we integrate KAN with a ResNet-50 model pre-trained on ImageNet and evaluate its performance on the CIFAR-10 dataset. We perform a systematic hyperparameter search, focusing on grid size and spline degree (k), to optimize KAN's flexibility and accuracy. Our results demonstrate that KAN consistently outperforms traditional linear probing, achieving significant improvements in accuracy and generalization across a range of configurations. These findings indicate that KAN offers a more powerful and adaptable alternative to conventional linear probing techniques in transfer learning.
ChatGPT v.s. Media Bias: A Comparative Study of GPT-3.5 and Fine-tuned Language Models
Mar 29, 2024In our rapidly evolving digital sphere, the ability to discern media bias becomes crucial as it can shape public sentiment and influence pivotal decisions. The advent of large language models (LLMs), such as ChatGPT, noted for their broad utility in various natural language processing (NLP) tasks, invites exploration of their efficacy in media bias detection. Can ChatGPT detect media bias? This study seeks to answer this question by leveraging the Media Bias Identification Benchmark (MBIB) to assess ChatGPT's competency in distinguishing six categories of media bias, juxtaposed against fine-tuned models such as BART, ConvBERT, and GPT-2. The findings present a dichotomy: ChatGPT performs at par with fine-tuned models in detecting hate speech and text-level context bias, yet faces difficulties with subtler elements of other bias detections, namely, fake news, racial, gender, and cognitive biases.
* 9 pages, 1 figure, published on Applied and Computational Engineering
Recovering Surveillance Video Using RF Cues
Dec 27, 2022Video capture is the most extensively utilized human perception source due to its intuitively understandable nature. A desired video capture often requires multiple environmental conditions such as ample ambient-light, unobstructed space, and proper camera angle. In contrast, wireless measurements are more ubiquitous and have fewer environmental constraints. In this paper, we propose CSI2Video, a novel cross-modal method that leverages only WiFi signals from commercial devices and a source of human identity information to recover fine-grained surveillance video in a real-time manner. Specifically, two tailored deep neural networks are designed to conduct cross-modal mapping and video generation tasks respectively. We make use of an auto-encoder-based structure to extract pose features from WiFi frames. Afterward, both extracted pose features and identity information are merged to generate synthetic surveillance video. Our solution generates realistic surveillance videos without any expensive wireless equipment and has ubiquitous, cheap, and real-time characteristics.