 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlternated Training with Synthetic and Authentic Data for Neural Machine Translation
Paper and Code
Jun 16, 2021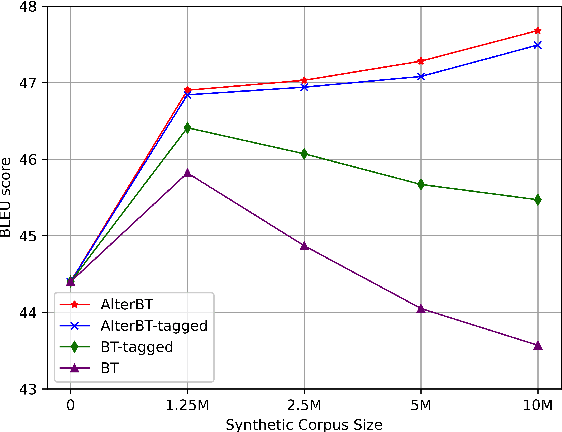
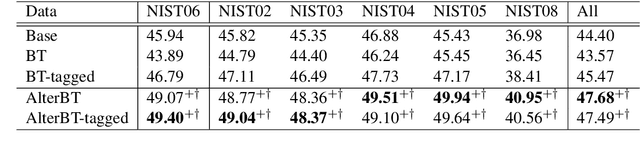
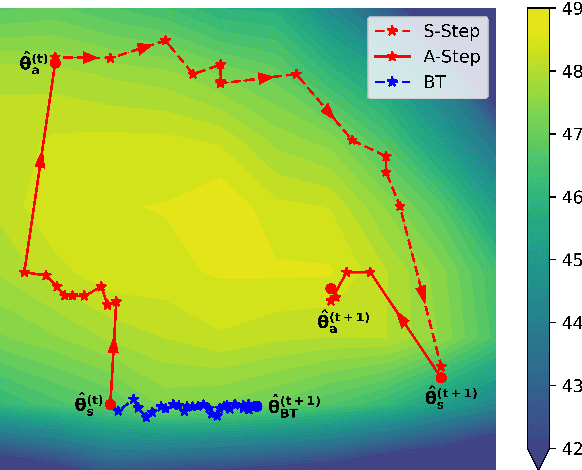
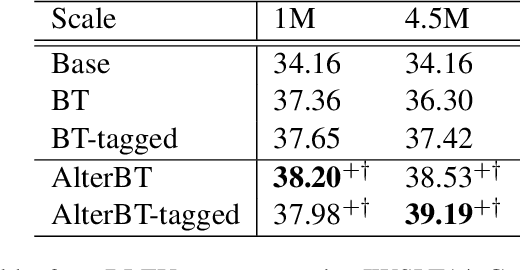
While synthetic bilingual corpora have demonstrated their effectiveness in low-resource neural machine translation (NMT), adding more synthetic data often deteriorates translation performance. In this work, we propose alternated training with synthetic and authentic data for NMT. The basic idea is to alternate synthetic and authentic corpora iteratively during training. Compared with previous work, we introduce authentic data as guidance to prevent the training of NMT models from being disturbed by noisy synthetic data. Experiments on Chinese-English and German-English translation tasks show that our approach improves the performance over several strong baselines. We visualize the BLEU landscape to further investigate the role of authentic and synthetic data during alternated training. From the visualization, we find that authentic data helps to direct the NMT model parameters towards points with higher BLEU scores and leads to consistent translation performance improvement.