 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOLO-UniOW: Efficient Universal Open-World Object Detection
Paper and Code
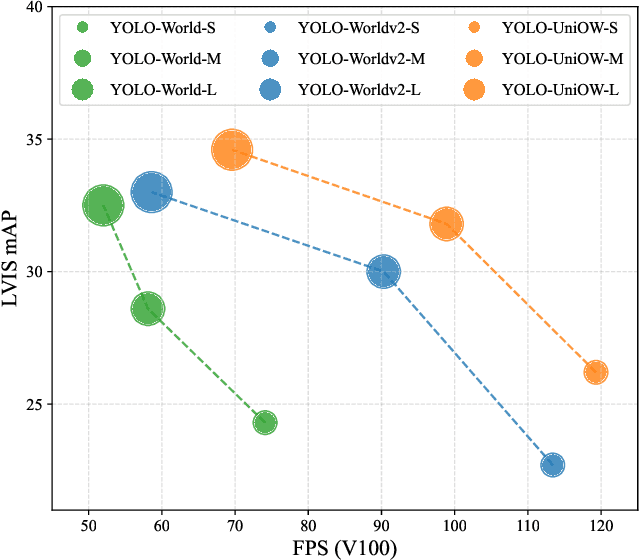
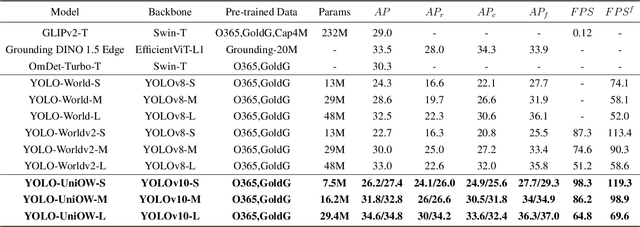
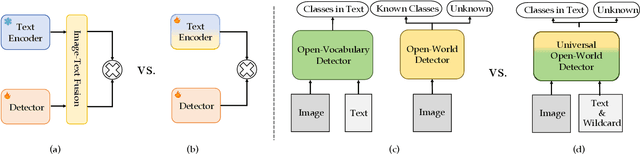
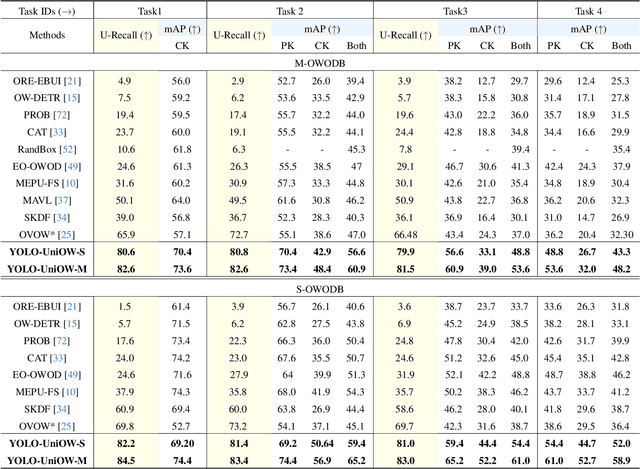
Traditional object detection models are constrained by the limitations of closed-set datasets, detecting only categories encountered during training. While multimodal models have extended category recognition by aligning text and image modalities, they introduce significant inference overhead due to cross-modality fusion and still remain restricted by predefined vocabulary, leaving them ineffective at handling unknown objects in open-world scenarios. In this work, we introduce Universal Open-World Object Detection (Uni-OWD), a new paradigm that unifies open-vocabulary and open-world object detection tasks. To address the challenges of this setting, we propose YOLO-UniOW, a novel model that advances the boundaries of efficiency, versatility, and performance. YOLO-UniOW incorporates Adaptive Decision Learning to replace computationally expensive cross-modality fusion with lightweight alignment in the CLIP latent space, achieving efficient detection without compromising generalization. Additionally, we design a Wildcard Learning strategy that detects out-of-distribution objects as "unknown" while enabling dynamic vocabulary expansion without the need for incremental learning. This design empowers YOLO-UniOW to seamlessly adapt to new categories in open-world environments. Extensive experiments validate the superiority of YOLO-UniOW, achieving achieving 34.6 AP and 30.0 APr on LVIS with an inference speed of 69.6 FPS. The model also sets benchmarks on M-OWODB, S-OWODB, and nuScenes datasets, showcasing its unmatched performance in open-world object detection. Code and models are available at https://github.com/THU-MIG/YOLO-UniOW.