 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Cross-lingual Embeddings from Twitter via Distant Supervision
Paper and Code
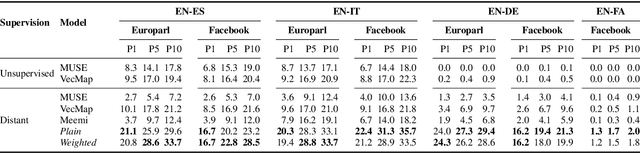
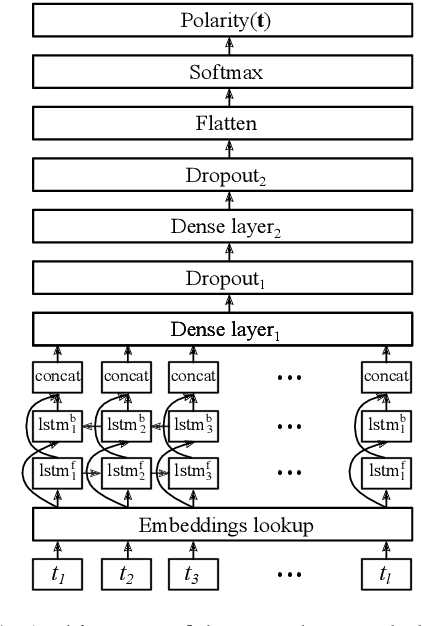
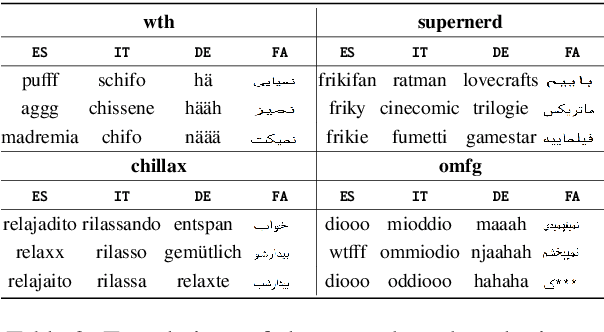

Cross-lingual embeddings represent the meaning of words from different languages in the same vector space. Recent work has shown that it is possible to construct such representations by aligning independently learned monolingual embedding spaces, and that accurate alignments can be obtained even without external bilingual data. In this paper we explore a research direction which has been surprisingly neglected in the literature: leveraging noisy user-generated text to learn cross-lingual embeddings particularly tailored towards social media applications. While the noisiness and informal nature of the social media genre poses additional challenges to cross-lingual embedding methods, we find that it also provides key opportunities due to the abundance of code-switching and the existence of a shared vocabulary of emoji and named entities. Our contribution consists in a very simple post-processing step that exploits these phenomena to significantly improve the performance of state-of-the-art alignment methods.