 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the performance of phonetic algorithms in microtext normalization
Feb 04, 2024User-generated content published on microblogging social networks constitutes a priceless source of information. However, microtexts usually deviate from the standard lexical and grammatical rules of the language, thus making its processing by traditional intelligent systems very difficult. As an answer, microtext normalization consists in transforming those non-standard microtexts into standard well-written texts as a preprocessing step, allowing traditional approaches to continue with their usual processing. Given the importance of phonetic phenomena in non-standard text formation, an essential element of the knowledge base of a normalizer would be the phonetic rules that encode these phenomena, which can be found in the so-called phonetic algorithms. In this work we experiment with a wide range of phonetic algorithms for the English language. The aim of this study is to determine the best phonetic algorithms within the context of candidate generation for microtext normalization. In other words, we intend to find those algorithms that taking as input non-standard terms to be normalized allow us to obtain as output the smallest possible sets of normalization candidates which still contain the corresponding target standard words. As it will be stated, the choice of the phonetic algorithm will depend heavily on the capabilities of the candidate selection mechanism which we usually find at the end of a microtext normalization pipeline. The faster it can make the right choices among big enough sets of candidates, the more we can sacrifice on the precision of the phonetic algorithms in favour of coverage in order to increase the overall performance of the normalization system. KEYWORDS: microtext normalization; phonetic algorithm; fuzzy matching; Twitter; texting
* Accepted for publication in journal Expert Systems with Applications
Cross-Lingual Word Embeddings for Turkic Languages
May 17, 2020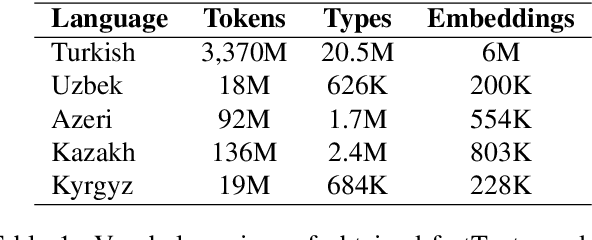
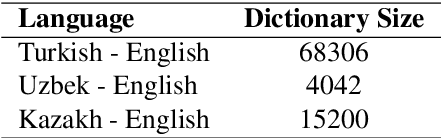
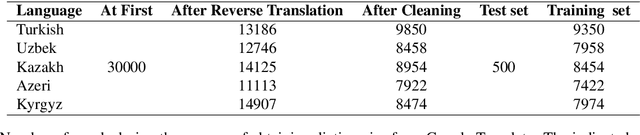

There has been an increasing interest in learning cross-lingual word embeddings to transfer knowledge obtained from a resource-rich language, such as English, to lower-resource languages for which annotated data is scarce, such as Turkish, Russian, and many others. In this paper, we present the first viability study of established techniques to align monolingual embedding spaces for Turkish, Uzbek, Azeri, Kazakh and Kyrgyz, members of the Turkic family which is heavily affected by the low-resource constraint. Those techniques are known to require little explicit supervision, mainly in the form of bilingual dictionaries, hence being easily adaptable to different domains, including low-resource ones. We obtain new bilingual dictionaries and new word embeddings for these languages and show the steps for obtaining cross-lingual word embeddings using state-of-the-art techniques. Then, we evaluate the results using the bilingual dictionary induction task. Our experiments confirm that the obtained bilingual dictionaries outperform previously-available ones, and that word embeddings from a low-resource language can benefit from resource-rich closely-related languages when they are aligned together. Furthermore, evaluation on an extrinsic task (Sentiment analysis on Uzbek) proves that monolingual word embeddings can, although slightly, benefit from cross-lingual alignments.
* Final version, published in the proceedings of LREC 2020
Towards robust word embeddings for noisy texts
Nov 28, 2019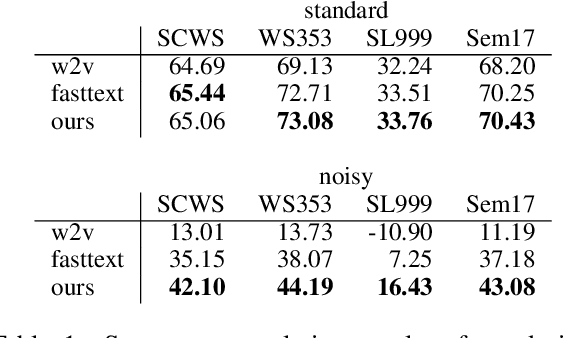
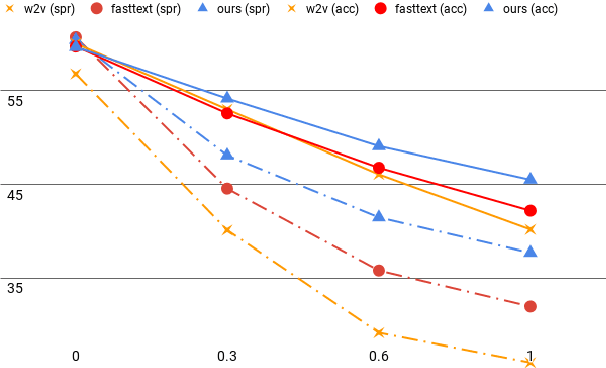
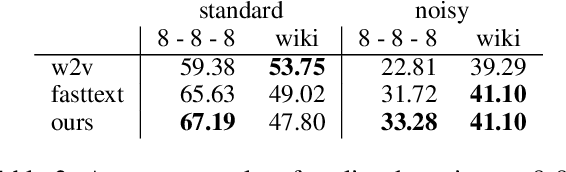
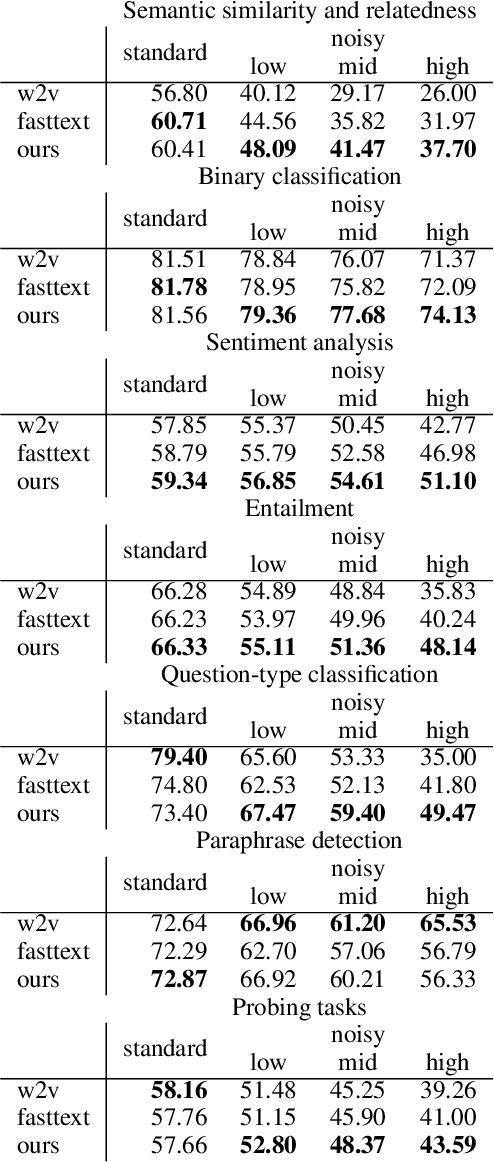
Research on word embeddings has mainly focused on improving their performance on standard corpora, disregarding the difficulties posed by noisy texts in the form of tweets and other types of non-standard writing from social media. In this work, we propose a simple extension to the skipgram model in which we introduce the concept of bridge-words, which are artificial words added to the model to strengthen the similarity between standard words and their noisy variants. Our new embeddings outperform the state of the art on noisy texts on a wide range of evaluation tasks, both intrinsic and extrinsic, while retaining a good performance on standard texts. To the best of our knowledge, this is the first explicit approach at dealing with this type of noisy texts at the word embedding level that goes beyond the support for out-of-vocabulary words.
Meemi: A Simple Method for Post-processing Cross-lingual Word Embeddings
Oct 22, 2019
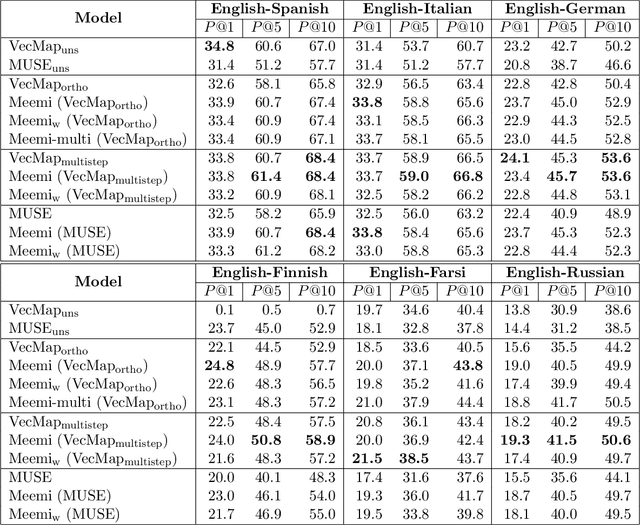
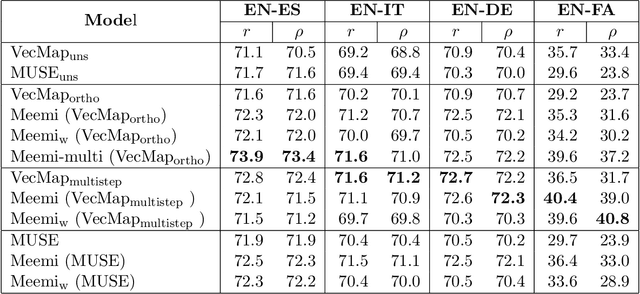
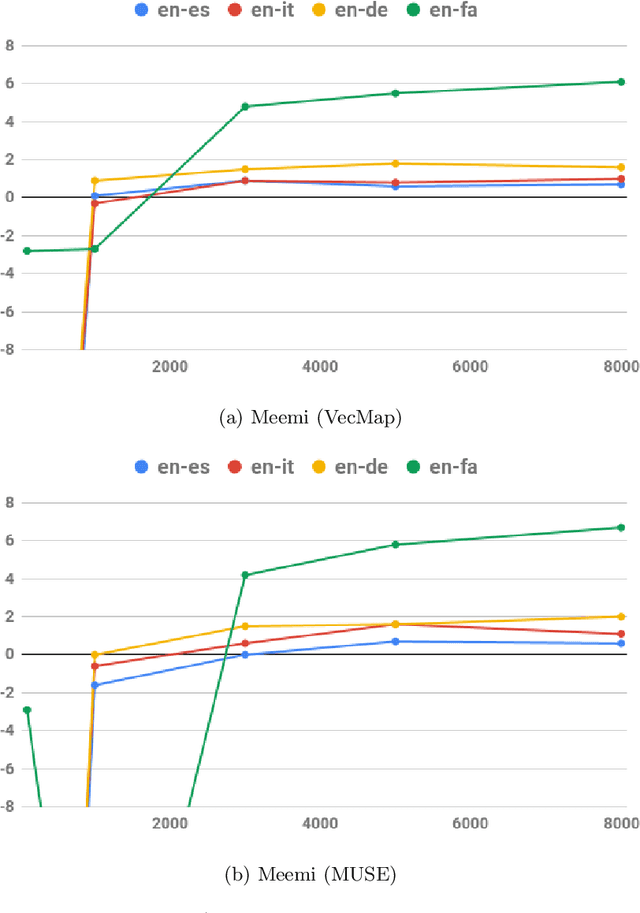
Word embeddings have become a standard resource in the toolset of any Natural Language Processing practitioner. While monolingual word embeddings encode information about words in the context of a particular language, cross-lingual embeddings define a multilingual space where word embeddings from two or more languages are integrated together. Current state-of-the-art approaches learn these embeddings by aligning two disjoint monolingual vector spaces through an orthogonal transformation which preserves the structure of the monolingual counterparts. In this work, we propose to apply an additional transformation after this initial alignment step, which aims to bring the vector representations of a given word and its translations closer to their average. Since this additional transformation is non-orthogonal, it also affects the structure of the monolingual spaces. We show that our approach both improves the integration of the monolingual spaces as well as the quality of the monolingual spaces themselves. Furthermore, because our transformation can be applied to an arbitrary number of languages, we are able to effectively obtain a truly multilingual space. The resulting (monolingual and multilingual) spaces show consistent gains over the current state-of-the-art in standard intrinsic tasks, namely dictionary induction and word similarity, as well as in extrinsic tasks such as cross-lingual hypernym discovery and cross-lingual natural language inference.
On the Robustness of Unsupervised and Semi-supervised Cross-lingual Word Embedding Learning
Aug 21, 2019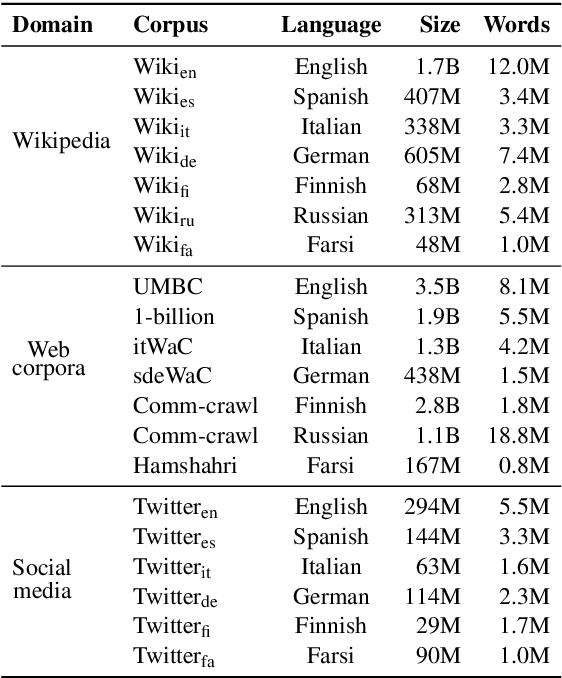
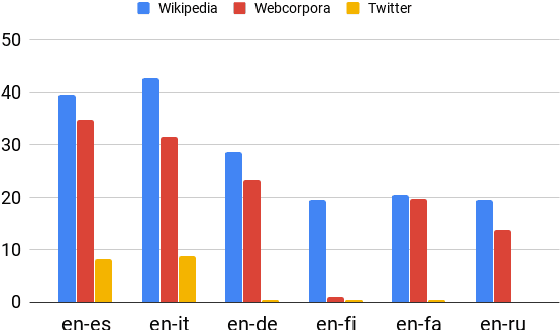


Cross-lingual word embeddings are vector representations of words in different languages where words with similar meaning are represented by similar vectors, regardless of the language. Recent developments which construct these embeddings by aligning monolingual spaces have shown that accurate alignments can be obtained with little or no supervision. However, the focus has been on a particular controlled scenario for evaluation, and there is no strong evidence on how current state-of-the-art systems would fare with noisy text or for language pairs with major linguistic differences. In this paper we present an extensive evaluation over multiple cross-lingual embedding models, analyzing their strengths and limitations with respect to different variables such as target language, training corpora and amount of supervision. Our conclusions put in doubt the view that high-quality cross-lingual embeddings can always be learned without much supervision.
Learning Cross-lingual Embeddings from Twitter via Distant Supervision
May 17, 2019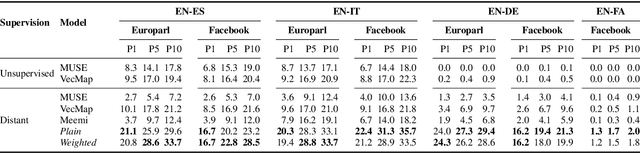
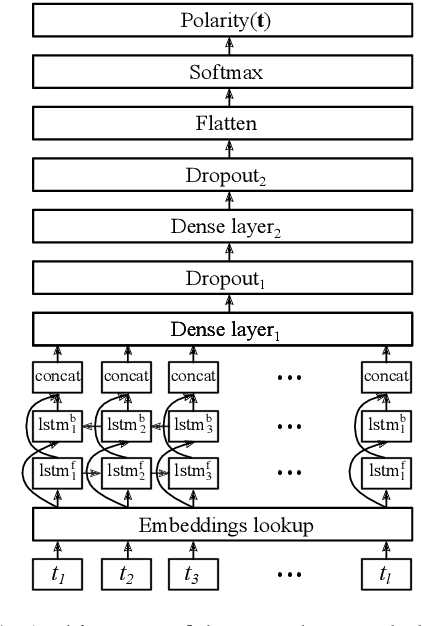
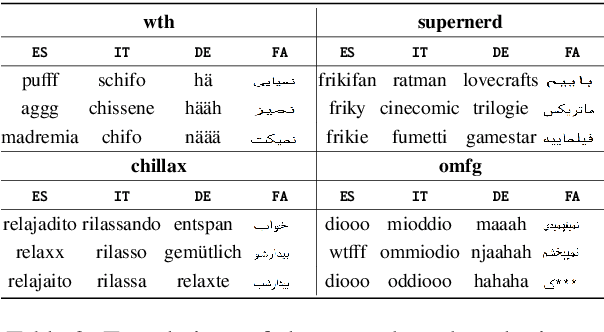

Cross-lingual embeddings represent the meaning of words from different languages in the same vector space. Recent work has shown that it is possible to construct such representations by aligning independently learned monolingual embedding spaces, and that accurate alignments can be obtained even without external bilingual data. In this paper we explore a research direction which has been surprisingly neglected in the literature: leveraging noisy user-generated text to learn cross-lingual embeddings particularly tailored towards social media applications. While the noisiness and informal nature of the social media genre poses additional challenges to cross-lingual embedding methods, we find that it also provides key opportunities due to the abundance of code-switching and the existence of a shared vocabulary of emoji and named entities. Our contribution consists in a very simple post-processing step that exploits these phenomena to significantly improve the performance of state-of-the-art alignment methods.
Comparing Neural- and N-Gram-Based Language Models for Word Segmentation
Dec 03, 2018
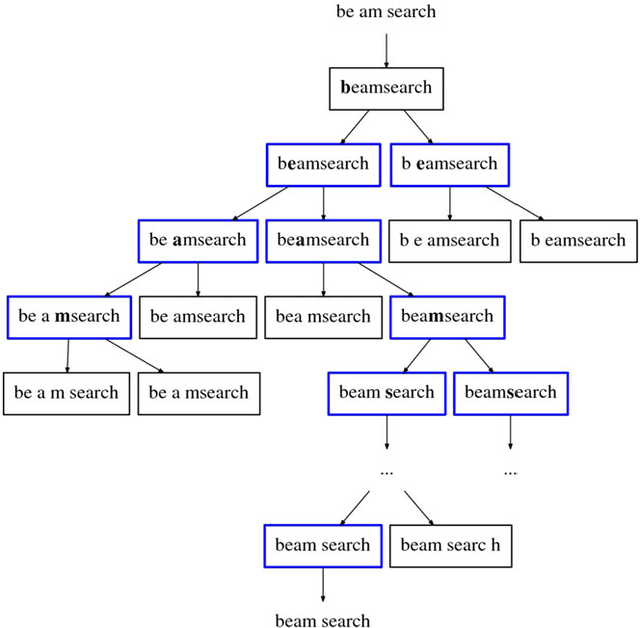
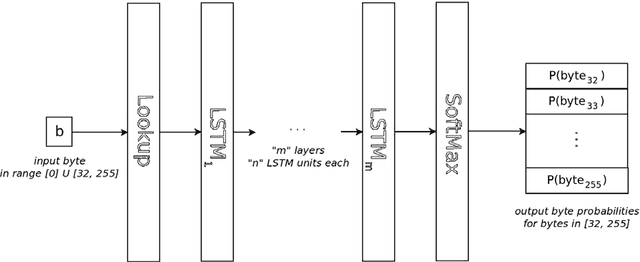

Word segmentation is the task of inserting or deleting word boundary characters in order to separate character sequences that correspond to words in some language. In this article we propose an approach based on a beam search algorithm and a language model working at the byte/character level, the latter component implemented either as an n-gram model or a recurrent neural network. The resulting system analyzes the text input with no word boundaries one token at a time, which can be a character or a byte, and uses the information gathered by the language model to determine if a boundary must be placed in the current position or not. Our aim is to use this system in a preprocessing step for a microtext normalization system. This means that it needs to effectively cope with the data sparsity present on this kind of texts. We also strove to surpass the performance of two readily available word segmentation systems: The well-known and accessible Word Breaker by Microsoft, and the Python module WordSegment by Grant Jenks. The results show that we have met our objectives, and we hope to continue to improve both the precision and the efficiency of our system in the future.
* 11 pages, 4 figures, 5 tables, accepted in Journal of the Association for Information Science and Technology
Improving Cross-Lingual Word Embeddings by Meeting in the Middle
Aug 27, 2018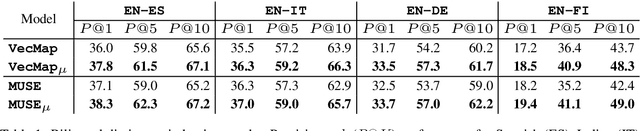
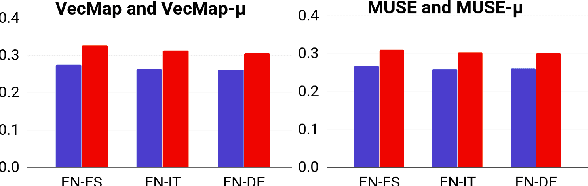
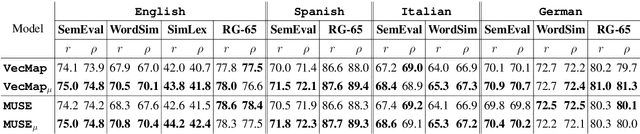
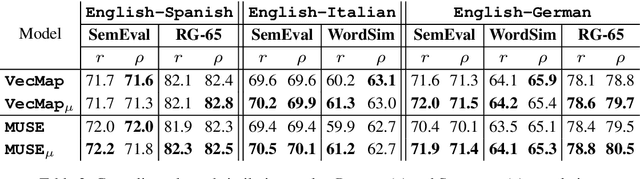
Cross-lingual word embeddings are becoming increasingly important in multilingual NLP. Recently, it has been shown that these embeddings can be effectively learned by aligning two disjoint monolingual vector spaces through linear transformations, using no more than a small bilingual dictionary as supervision. In this work, we propose to apply an additional transformation after the initial alignment step, which moves cross-lingual synonyms towards a middle point between them. By applying this transformation our aim is to obtain a better cross-lingual integration of the vector spaces. In addition, and perhaps surprisingly, the monolingual spaces also improve by this transformation. This is in contrast to the original alignment, which is typically learned such that the structure of the monolingual spaces is preserved. Our experiments confirm that the resulting cross-lingual embeddings outperform state-of-the-art models in both monolingual and cross-lingual evaluation tasks.