 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLe and LYS at BioASQ MESINESP8 Task: similarity based descriptor assignment in Spanish
Feb 02, 2024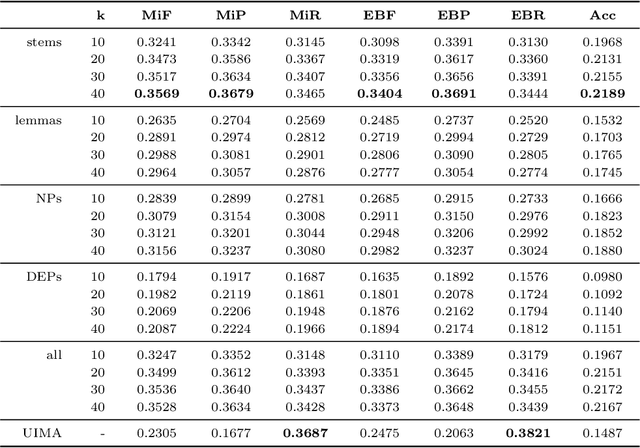

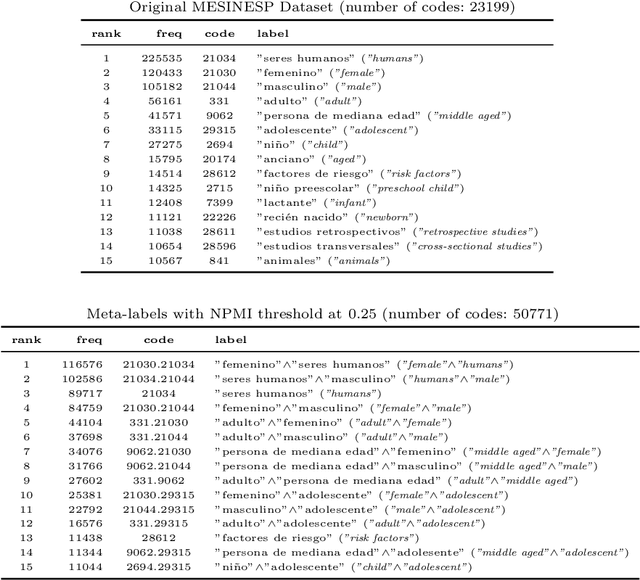
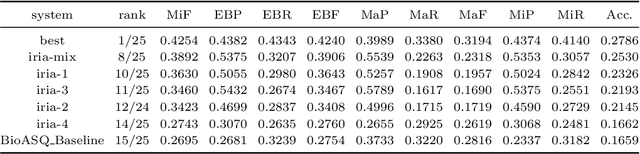
In this paper, we describe our participation in the MESINESP Task of the BioASQ biomedical semantic indexing challenge. The participating system follows an approach based solely on conventional information retrieval tools. We have evaluated various alternatives for extracting index terms from IBECS/LILACS documents in order to be stored in an Apache Lucene index. Those indexed representations are queried using the contents of the article to be annotated and a ranked list of candidate labels is created from the retrieved documents. We also have evaluated a sort of limited Label Powerset approach which creates meta-labels joining pairs of DeCS labels with high co-occurrence scores, and an alternative method based on label profile matching. Results obtained in official runs seem to confirm the suitability of this approach for languages like Spanish.
* Accepted at the 8th BioASQ Workshop at the 11th Conference and Labs of the Evaluation Forum (CLEF) 2020. 11 pages
Design and Implementation of a Tool for Extracting Uzbek Syllables
Dec 25, 2023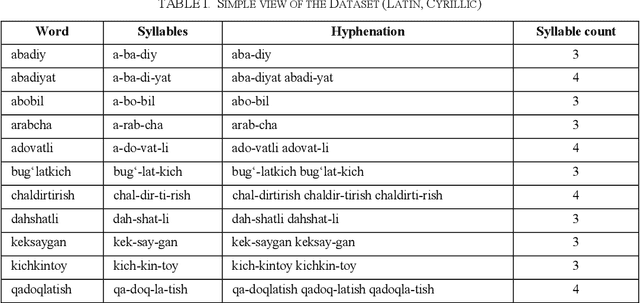
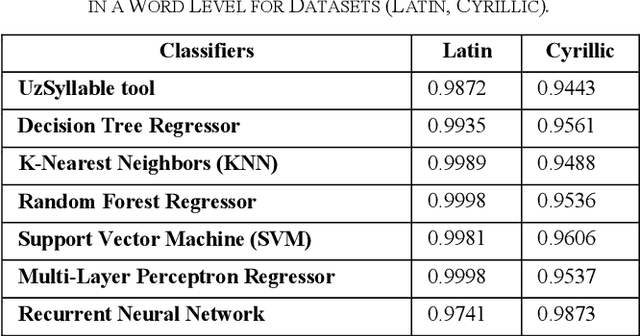
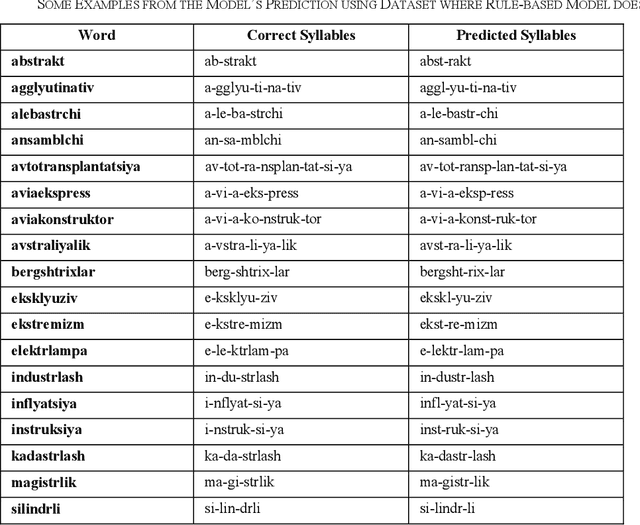
The accurate syllabification of words plays a vital role in various Natural Language Processing applications. Syllabification is a versatile linguistic tool with applications in linguistic research, language technology, education, and various fields where understanding and processing language is essential. In this paper, we present a comprehensive approach to syllabification for the Uzbek language, including rule-based techniques and machine learning algorithms. Our rule-based approach utilizes advanced methods for dividing words into syllables, generating hyphenations for line breaks and count of syllables. Additionally, we collected a dataset for evaluating and training using machine learning algorithms comprising word-syllable mappings, hyphenations, and syllable counts to predict syllable counts as well as for the evaluation of the proposed model. Our results demonstrate the effectiveness and efficiency of both approaches in achieving accurate syllabification. The results of our experiments show that both approaches achieved a high level of accuracy, exceeding 99%. This study provides valuable insights and recommendations for future research on syllabification and related areas in not only the Uzbek language itself, but also in other closely-related Turkic languages with low-resource factor.
Text classification dataset and analysis for Uzbek language
Feb 28, 2023Text classification is an important task in Natural Language Processing (NLP), where the goal is to categorize text data into predefined classes. In this study, we analyse the dataset creation steps and evaluation techniques of multi-label news categorisation task as part of text classification. We first present a newly obtained dataset for Uzbek text classification, which was collected from 10 different news and press websites and covers 15 categories of news, press and law texts. We also present a comprehensive evaluation of different models, ranging from traditional bag-of-words models to deep learning architectures, on this newly created dataset. Our experiments show that the Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN) based models outperform the rule-based models. The best performance is achieved by the BERTbek model, which is a transformer-based BERT model trained on the Uzbek corpus. Our findings provide a good baseline for further research in Uzbek text classification.
UzbekTagger: The rule-based POS tagger for Uzbek language
Jan 30, 2023This research paper presents a part-of-speech (POS) annotated dataset and tagger tool for the low-resource Uzbek language. The dataset includes 12 tags, which were used to develop a rule-based POS-tagger tool. The corpus text used in the annotation process was made sure to be balanced over 20 different fields in order to ensure its representativeness. Uzbek being an agglutinative language so the most of the words in an Uzbek sentence are formed by adding suffixes. This nature of it makes the POS-tagging task difficult to find the stems of words and the right part-of-speech they belong to. The methodology proposed in this research is the stemming of the words with an affix/suffix stripping approach including database of the stem forms of the words in the Uzbek language. The tagger tool was tested on the annotated dataset and showed high accuracy in identifying and tagging parts of speech in Uzbek text. This newly presented dataset and tagger tool can be used for a variety of natural language processing tasks such as language modeling, machine translation, and text-to-speech synthesis. The presented dataset is the first of its kind to be made publicly available for Uzbek, and the POS-tagger tool created can also be used as a pivot to use as a base for other closely-related Turkic languages.
Uzbek Sentiment Analysis based on local Restaurant Reviews
May 31, 2022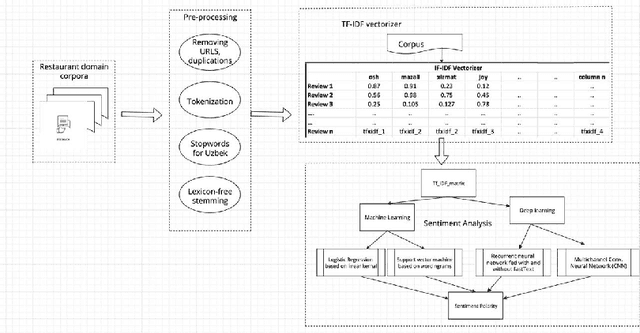

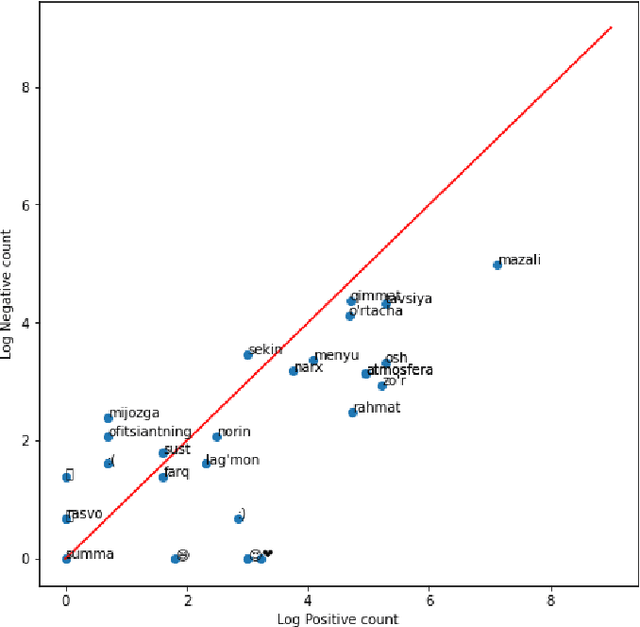

Extracting useful information for sentiment analysis and classification problems from a big amount of user-generated feedback, such as restaurant reviews, is a crucial task of natural language processing, which is not only for customer satisfaction where it can give personalized services, but can also influence the further development of a company. In this paper, we present a work done on collecting restaurant reviews data as a sentiment analysis dataset for the Uzbek language, a member of the Turkic family which is heavily affected by the low-resource constraint, and provide some further analysis of the novel dataset by evaluation using different techniques, from logistic regression based models, to support vector machines, and even deep learning models, such as recurrent neural networks, as well as convolutional neural networks. The paper includes detailed information on how the data was collected, how it was pre-processed for better quality optimization, as well as experimental setups for the evaluation process. The overall evaluation results indicate that by performing pre-processing steps, such as stemming for agglutinative languages, the system yields better results, eventually achieving 91% accuracy result in the best performing model
A machine transliteration tool between Uzbek alphabets
May 19, 2022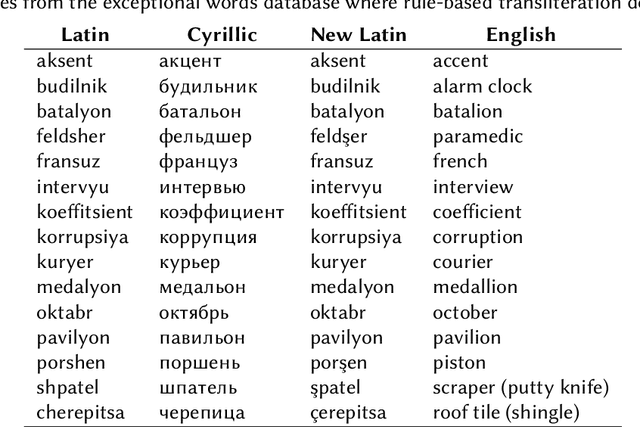
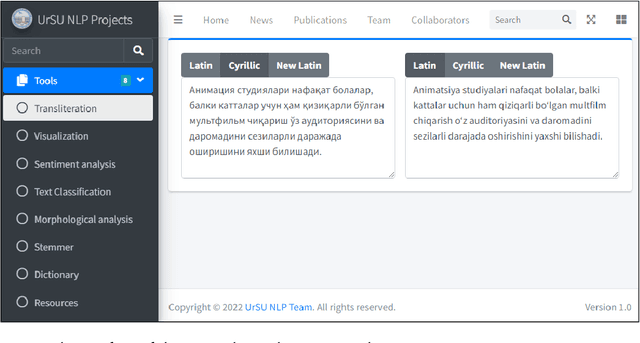
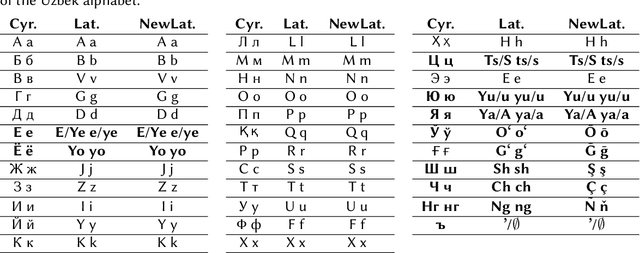
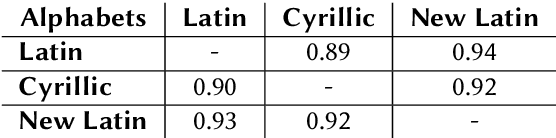
Machine transliteration, as defined in this paper, is a process of automatically transforming written script of words from a source alphabet into words of another target alphabet within the same language, while preserving their meaning, as well as pronunciation. The main goal of this paper is to present a machine transliteration tool between three common scripts used in low-resource Uzbek language: the old Cyrillic, currently official Latin, and newly announced New Latin alphabets. The tool has been created using a combination of rule-based and fine-tuning approaches. The created tool is available as an open-source Python package, as well as a web-based application including a public API. To our knowledge, this is the first machine transliteration tool that supports the newly announced Latin alphabet of the Uzbek language.
SimRelUz: Similarity and Relatedness scores as a Semantic Evaluation dataset for Uzbek language
May 12, 2022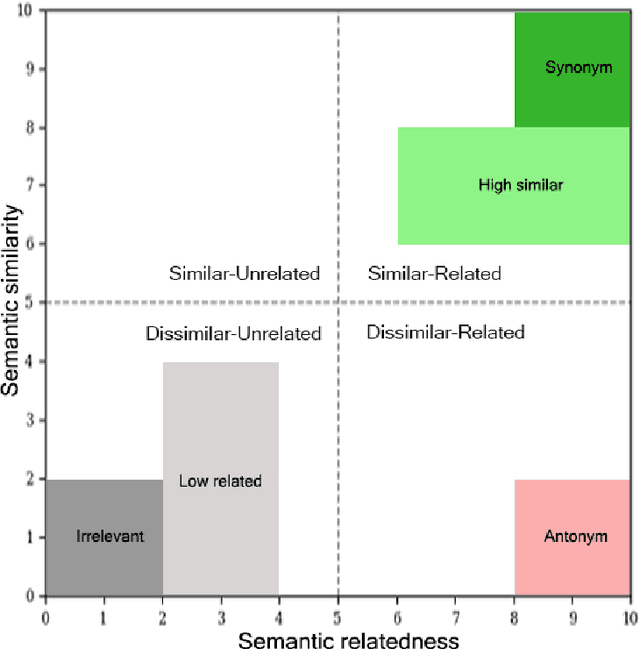

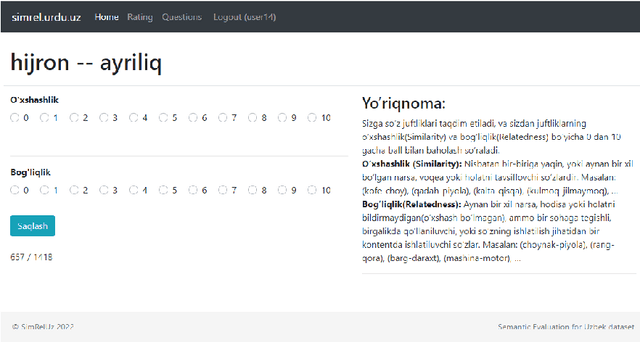

Semantic relatedness between words is one of the core concepts in natural language processing, thus making semantic evaluation an important task. In this paper, we present a semantic model evaluation dataset: SimRelUz - a collection of similarity and relatedness scores of word pairs for the low-resource Uzbek language. The dataset consists of more than a thousand pairs of words carefully selected based on their morphological features, occurrence frequency, semantic relation, as well as annotated by eleven native Uzbek speakers from different age groups and gender. We also paid attention to the problem of dealing with rare words and out-of-vocabulary words to thoroughly evaluate the robustness of semantic models.
Cross-Lingual Word Embeddings for Turkic Languages
May 17, 2020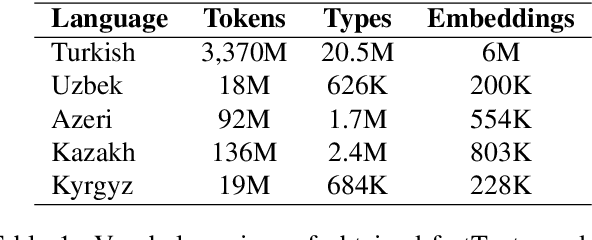
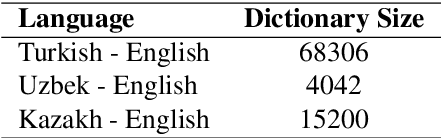
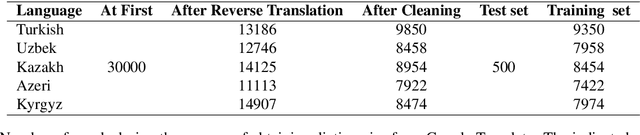

There has been an increasing interest in learning cross-lingual word embeddings to transfer knowledge obtained from a resource-rich language, such as English, to lower-resource languages for which annotated data is scarce, such as Turkish, Russian, and many others. In this paper, we present the first viability study of established techniques to align monolingual embedding spaces for Turkish, Uzbek, Azeri, Kazakh and Kyrgyz, members of the Turkic family which is heavily affected by the low-resource constraint. Those techniques are known to require little explicit supervision, mainly in the form of bilingual dictionaries, hence being easily adaptable to different domains, including low-resource ones. We obtain new bilingual dictionaries and new word embeddings for these languages and show the steps for obtaining cross-lingual word embeddings using state-of-the-art techniques. Then, we evaluate the results using the bilingual dictionary induction task. Our experiments confirm that the obtained bilingual dictionaries outperform previously-available ones, and that word embeddings from a low-resource language can benefit from resource-rich closely-related languages when they are aligned together. Furthermore, evaluation on an extrinsic task (Sentiment analysis on Uzbek) proves that monolingual word embeddings can, although slightly, benefit from cross-lingual alignments.
* Final version, published in the proceedings of LREC 2020