 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUzbek text's correspondence with the educational potential of pupils: a case study of the School corpus
Mar 18, 2023



One of the major challenges of an educational system is choosing appropriate content considering pupils' age and intellectual potential. In this article the experiment of primary school grades (from 1st to 4th grades) is considered for automatically determining the correspondence of an educational materials recommended for pupils by using the School corpus where it includes the dataset of 25 school textbooks confirmed by the Ministry of preschool and school education of the Republic of Uzbekistan. In this case, TF-IDF scores of the texts are determined, they are converted into a vector representation, and the given educational materials are compared with the corresponding class of the School corpus using the cosine similarity algorithm. Based on the results of the calculation, it is determined whether the given educational material is appropriate or not appropriate for the pupils' educational potential.
Text classification dataset and analysis for Uzbek language
Feb 28, 2023Text classification is an important task in Natural Language Processing (NLP), where the goal is to categorize text data into predefined classes. In this study, we analyse the dataset creation steps and evaluation techniques of multi-label news categorisation task as part of text classification. We first present a newly obtained dataset for Uzbek text classification, which was collected from 10 different news and press websites and covers 15 categories of news, press and law texts. We also present a comprehensive evaluation of different models, ranging from traditional bag-of-words models to deep learning architectures, on this newly created dataset. Our experiments show that the Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN) based models outperform the rule-based models. The best performance is achieved by the BERTbek model, which is a transformer-based BERT model trained on the Uzbek corpus. Our findings provide a good baseline for further research in Uzbek text classification.
Uzbek Sentiment Analysis based on local Restaurant Reviews
May 31, 2022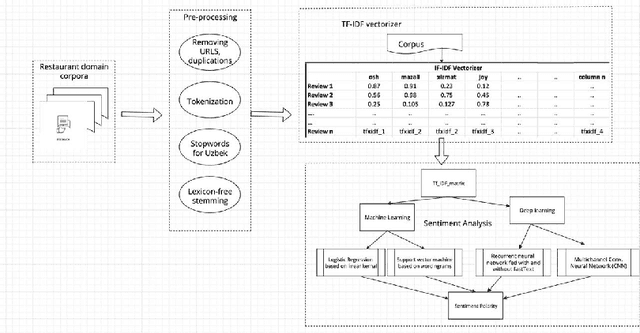

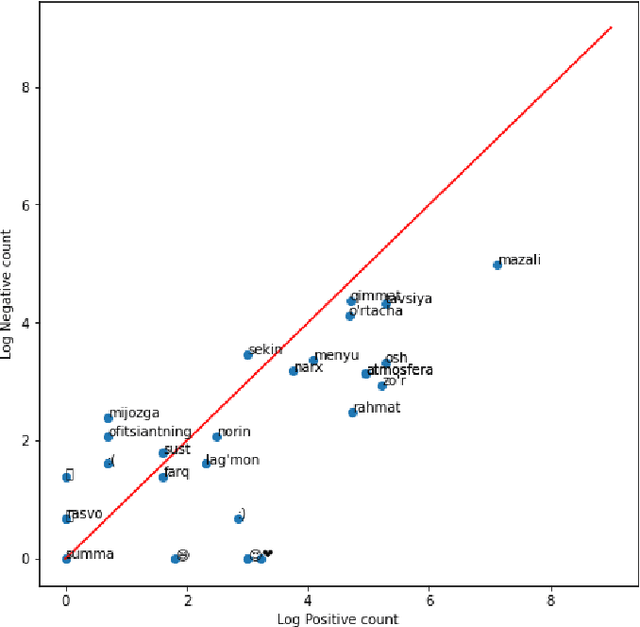

Extracting useful information for sentiment analysis and classification problems from a big amount of user-generated feedback, such as restaurant reviews, is a crucial task of natural language processing, which is not only for customer satisfaction where it can give personalized services, but can also influence the further development of a company. In this paper, we present a work done on collecting restaurant reviews data as a sentiment analysis dataset for the Uzbek language, a member of the Turkic family which is heavily affected by the low-resource constraint, and provide some further analysis of the novel dataset by evaluation using different techniques, from logistic regression based models, to support vector machines, and even deep learning models, such as recurrent neural networks, as well as convolutional neural networks. The paper includes detailed information on how the data was collected, how it was pre-processed for better quality optimization, as well as experimental setups for the evaluation process. The overall evaluation results indicate that by performing pre-processing steps, such as stemming for agglutinative languages, the system yields better results, eventually achieving 91% accuracy result in the best performing model