 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUzbek Sentiment Analysis based on local Restaurant Reviews
May 31, 2022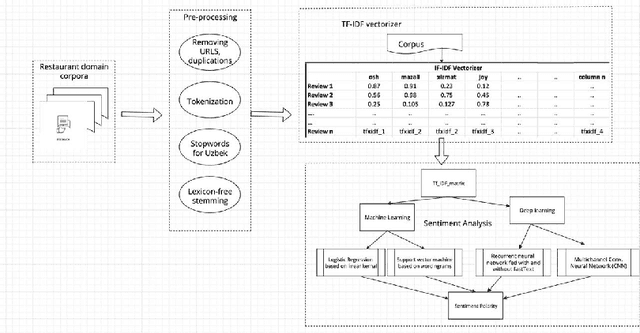

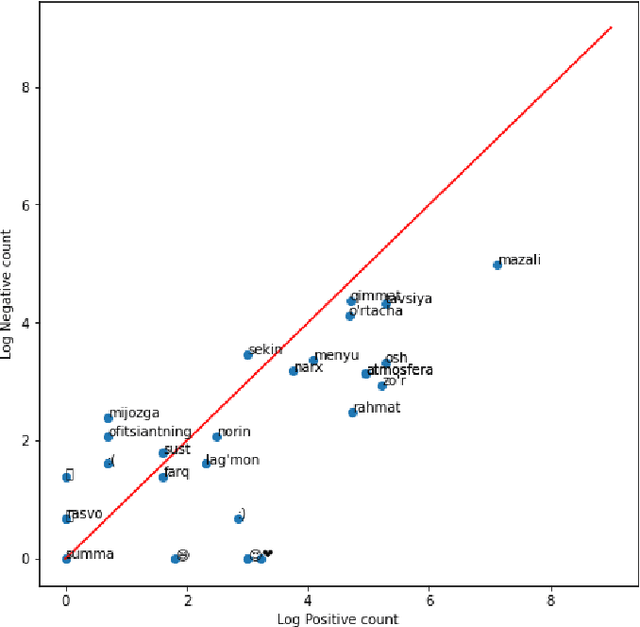

Extracting useful information for sentiment analysis and classification problems from a big amount of user-generated feedback, such as restaurant reviews, is a crucial task of natural language processing, which is not only for customer satisfaction where it can give personalized services, but can also influence the further development of a company. In this paper, we present a work done on collecting restaurant reviews data as a sentiment analysis dataset for the Uzbek language, a member of the Turkic family which is heavily affected by the low-resource constraint, and provide some further analysis of the novel dataset by evaluation using different techniques, from logistic regression based models, to support vector machines, and even deep learning models, such as recurrent neural networks, as well as convolutional neural networks. The paper includes detailed information on how the data was collected, how it was pre-processed for better quality optimization, as well as experimental setups for the evaluation process. The overall evaluation results indicate that by performing pre-processing steps, such as stemming for agglutinative languages, the system yields better results, eventually achieving 91% accuracy result in the best performing model