 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign and Implementation of a Tool for Extracting Uzbek Syllables
Dec 25, 2023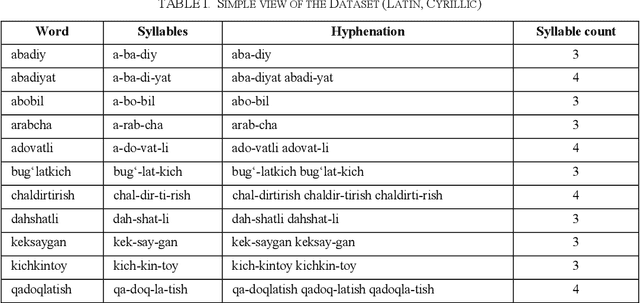
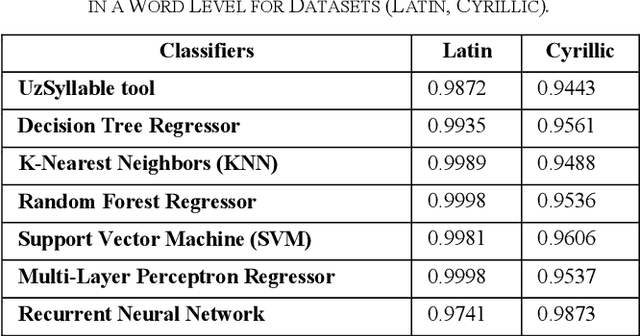
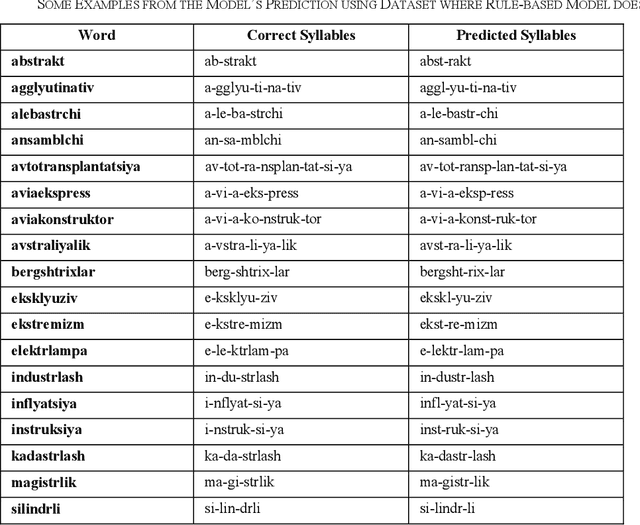
The accurate syllabification of words plays a vital role in various Natural Language Processing applications. Syllabification is a versatile linguistic tool with applications in linguistic research, language technology, education, and various fields where understanding and processing language is essential. In this paper, we present a comprehensive approach to syllabification for the Uzbek language, including rule-based techniques and machine learning algorithms. Our rule-based approach utilizes advanced methods for dividing words into syllables, generating hyphenations for line breaks and count of syllables. Additionally, we collected a dataset for evaluating and training using machine learning algorithms comprising word-syllable mappings, hyphenations, and syllable counts to predict syllable counts as well as for the evaluation of the proposed model. Our results demonstrate the effectiveness and efficiency of both approaches in achieving accurate syllabification. The results of our experiments show that both approaches achieved a high level of accuracy, exceeding 99%. This study provides valuable insights and recommendations for future research on syllabification and related areas in not only the Uzbek language itself, but also in other closely-related Turkic languages with low-resource factor.
Text classification dataset and analysis for Uzbek language
Feb 28, 2023Text classification is an important task in Natural Language Processing (NLP), where the goal is to categorize text data into predefined classes. In this study, we analyse the dataset creation steps and evaluation techniques of multi-label news categorisation task as part of text classification. We first present a newly obtained dataset for Uzbek text classification, which was collected from 10 different news and press websites and covers 15 categories of news, press and law texts. We also present a comprehensive evaluation of different models, ranging from traditional bag-of-words models to deep learning architectures, on this newly created dataset. Our experiments show that the Recurrent Neural Network (RNN) and Convolutional Neural Network (CNN) based models outperform the rule-based models. The best performance is achieved by the BERTbek model, which is a transformer-based BERT model trained on the Uzbek corpus. Our findings provide a good baseline for further research in Uzbek text classification.