 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoLe and LYS at BioASQ MESINESP8 Task: similarity based descriptor assignment in Spanish
Paper and Code
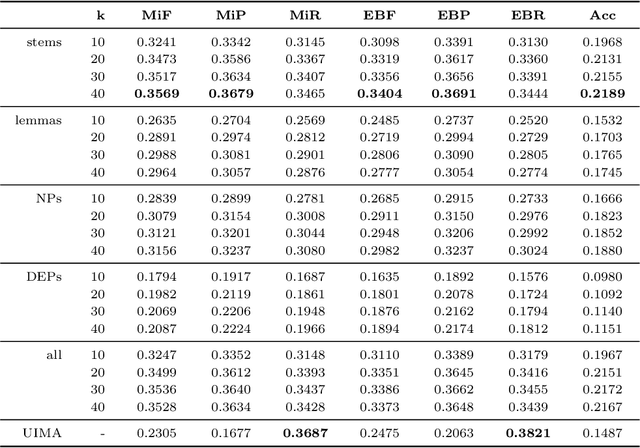

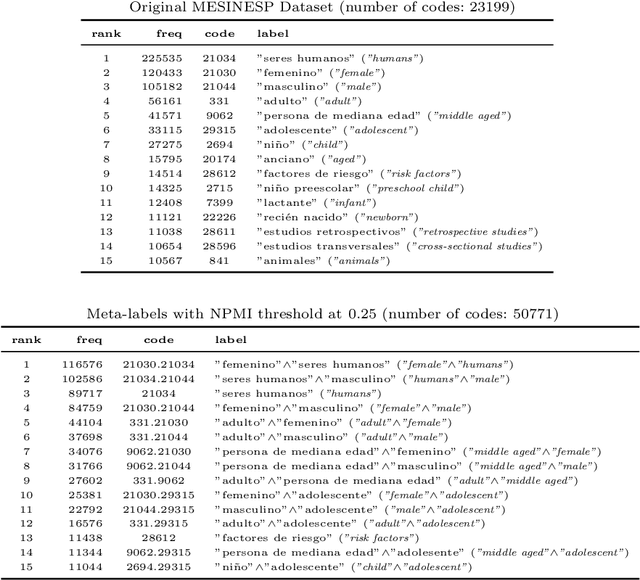
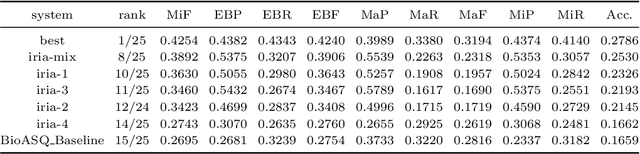
In this paper, we describe our participation in the MESINESP Task of the BioASQ biomedical semantic indexing challenge. The participating system follows an approach based solely on conventional information retrieval tools. We have evaluated various alternatives for extracting index terms from IBECS/LILACS documents in order to be stored in an Apache Lucene index. Those indexed representations are queried using the contents of the article to be annotated and a ranked list of candidate labels is created from the retrieved documents. We also have evaluated a sort of limited Label Powerset approach which creates meta-labels joining pairs of DeCS labels with high co-occurrence scores, and an alternative method based on label profile matching. Results obtained in official runs seem to confirm the suitability of this approach for languages like Spanish.