 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUzbekTagger: The rule-based POS tagger for Uzbek language
Jan 30, 2023This research paper presents a part-of-speech (POS) annotated dataset and tagger tool for the low-resource Uzbek language. The dataset includes 12 tags, which were used to develop a rule-based POS-tagger tool. The corpus text used in the annotation process was made sure to be balanced over 20 different fields in order to ensure its representativeness. Uzbek being an agglutinative language so the most of the words in an Uzbek sentence are formed by adding suffixes. This nature of it makes the POS-tagging task difficult to find the stems of words and the right part-of-speech they belong to. The methodology proposed in this research is the stemming of the words with an affix/suffix stripping approach including database of the stem forms of the words in the Uzbek language. The tagger tool was tested on the annotated dataset and showed high accuracy in identifying and tagging parts of speech in Uzbek text. This newly presented dataset and tagger tool can be used for a variety of natural language processing tasks such as language modeling, machine translation, and text-to-speech synthesis. The presented dataset is the first of its kind to be made publicly available for Uzbek, and the POS-tagger tool created can also be used as a pivot to use as a base for other closely-related Turkic languages.
UzbekStemmer: Development of a Rule-Based Stemming Algorithm for Uzbek Language
Oct 28, 2022In this paper we present a rule-based stemming algorithm for the Uzbek language. Uzbek is an agglutinative language, so many words are formed by adding suffixes, and the number of suffixes is also large. For this reason, it is difficult to find a stem of words. The methodology is proposed for doing the stemming of the Uzbek words with an affix stripping approach whereas not including any database of the normal word forms of the Uzbek language. Word affixes are classified into fifteen classes and designed as finite state machines (FSMs) for each class according to morphological rules. We created fifteen FSMs and linked them together to create the Basic FSM. A lexicon of affixes in XML format was created and a stemming application for Uzbek words has been developed based on the FSMs.
Development of a rule-based lemmatization algorithm through Finite State Machine for Uzbek language
Oct 28, 2022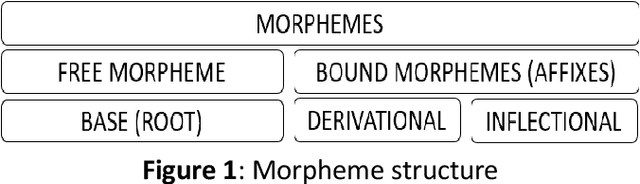
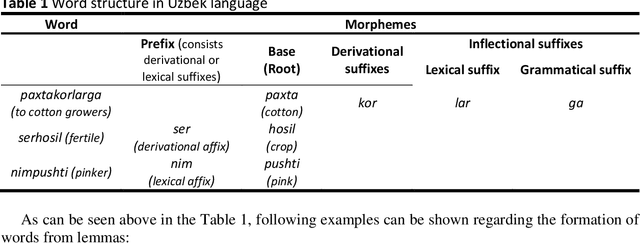
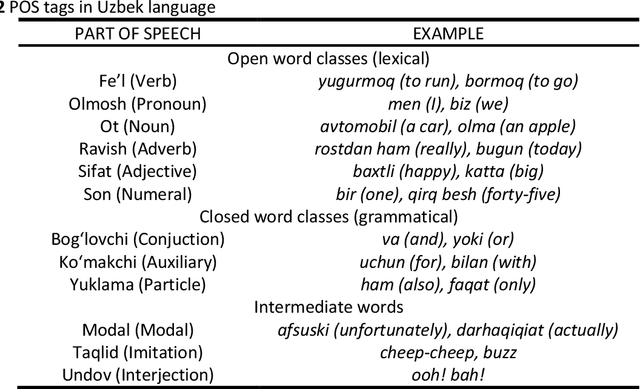
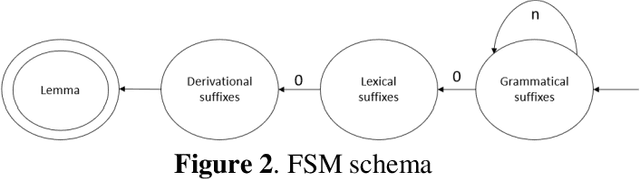
Lemmatization is one of the core concepts in natural language processing, thus creating a lemmatization tool is an important task. This paper discusses the construction of a lemmatization algorithm for the Uzbek language. The main purpose of the work is to remove affixes of words in the Uzbek language by means of the finite state machine and to identify a lemma (a word that can be found in the dictionary) of the word. The process of removing affixes uses a database of affixes and part of speech knowledge. This lemmatization consists of the general rules and a part of speech data of the Uzbek language, affixes, classification of affixes, removing affixes on the basis of the finite state machine for each class, as well as a definition of this word lemma.
Creating a morphological and syntactic tagged corpus for the Uzbek language
Oct 27, 2022Nowadays, creation of the tagged corpora is becoming one of the most important tasks of Natural Language Processing (NLP). There are not enough tagged corpora to build machine learning models for the low-resource Uzbek language. In this paper, we tried to fill that gap by developing a novel Part Of Speech (POS) and syntactic tagset for creating the syntactic and morphologically tagged corpus of the Uzbek language. This work also includes detailed description and presentation of a web-based application to work on a tagging as well. Based on the developed annotation tool and the software, we share our experience results of the first stage of the tagged corpus creation
Uzbek affix finite state machine for stemming
May 20, 2022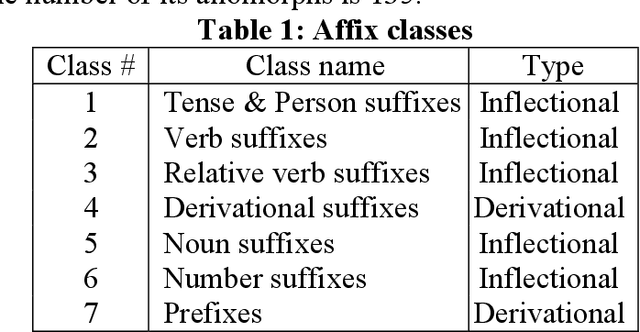
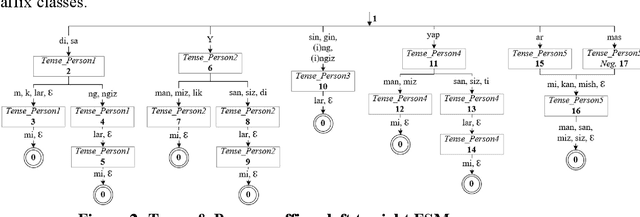
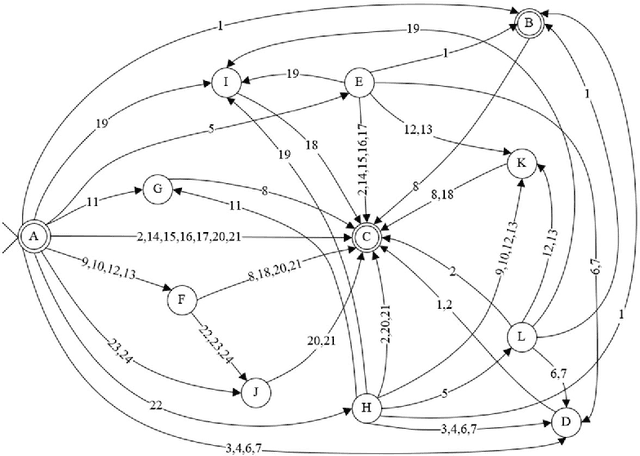

This work presents a morphological analyzer for the Uzbek language using a finite state machine. The proposed methodology is a morphologic analysis of Uzbek words by using an affix striping to find a root and without including any lexicon. This method helps to perform morphological analysis of words from a large amount of text at high speed as well as it is not required using of memory for keeping vocabulary. According to Uzbek, an agglutinative language can be designed with finite state machines (FSMs). In contrast to the previous works, this study modeled the completed FSMs for all word classes by using the Uzbek language's morphotactic rules in right to left order. This paper shows the stages of this methodology including the classification of the affixes, the generation of the FSMs for each affix class, and the combination into a head machine to make analysis a word.