 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUzbek affix finite state machine for stemming
Paper and Code
May 20, 2022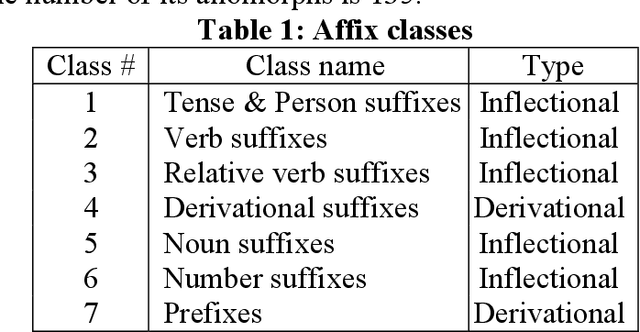
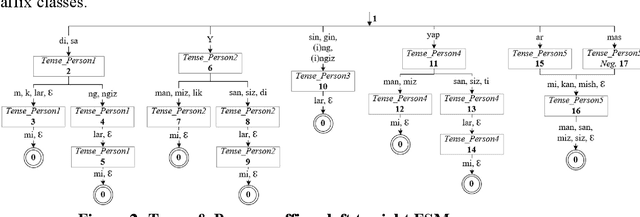
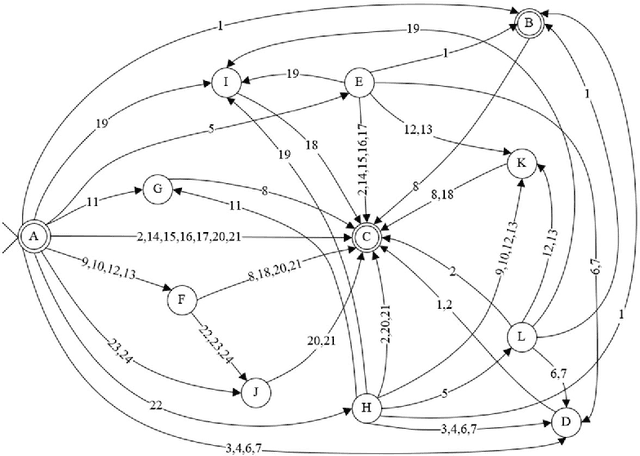

This work presents a morphological analyzer for the Uzbek language using a finite state machine. The proposed methodology is a morphologic analysis of Uzbek words by using an affix striping to find a root and without including any lexicon. This method helps to perform morphological analysis of words from a large amount of text at high speed as well as it is not required using of memory for keeping vocabulary. According to Uzbek, an agglutinative language can be designed with finite state machines (FSMs). In contrast to the previous works, this study modeled the completed FSMs for all word classes by using the Uzbek language's morphotactic rules in right to left order. This paper shows the stages of this methodology including the classification of the affixes, the generation of the FSMs for each affix class, and the combination into a head machine to make analysis a word.