 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Neural- and N-Gram-Based Language Models for Word Segmentation
Paper and Code

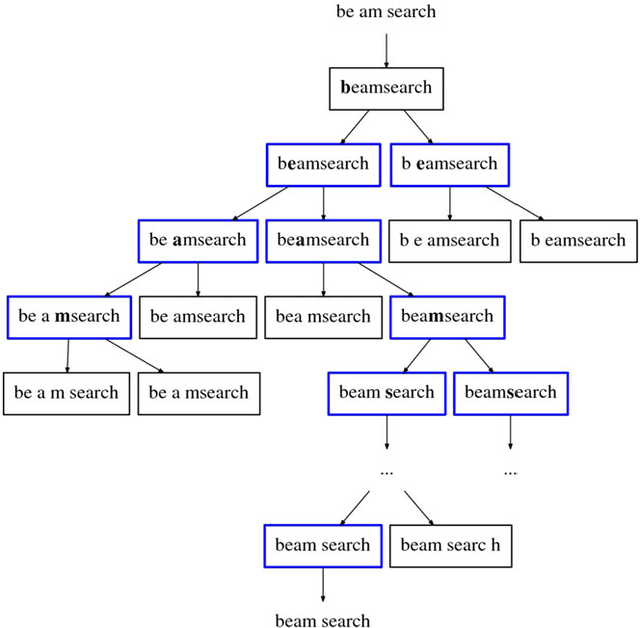
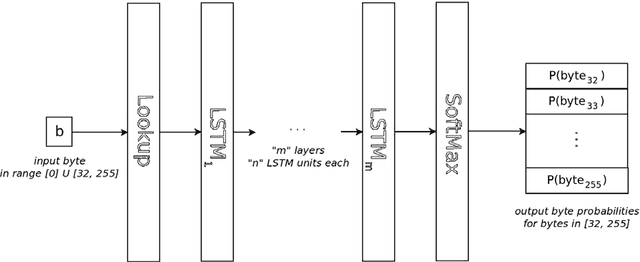

Word segmentation is the task of inserting or deleting word boundary characters in order to separate character sequences that correspond to words in some language. In this article we propose an approach based on a beam search algorithm and a language model working at the byte/character level, the latter component implemented either as an n-gram model or a recurrent neural network. The resulting system analyzes the text input with no word boundaries one token at a time, which can be a character or a byte, and uses the information gathered by the language model to determine if a boundary must be placed in the current position or not. Our aim is to use this system in a preprocessing step for a microtext normalization system. This means that it needs to effectively cope with the data sparsity present on this kind of texts. We also strove to surpass the performance of two readily available word segmentation systems: The well-known and accessible Word Breaker by Microsoft, and the Python module WordSegment by Grant Jenks. The results show that we have met our objectives, and we hope to continue to improve both the precision and the efficiency of our system in the future.