 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFuzzy Information Evolution with Three-Way Decision in Social Network Group Decision-Making
May 22, 2025In group decision-making (GDM) scenarios, uncertainty, dynamic social structures, and vague information present major challenges for traditional opinion dynamics models. To address these issues, this study proposes a novel social network group decision-making (SNGDM) framework that integrates three-way decision (3WD) theory, dynamic network reconstruction, and linguistic opinion representation. First, the 3WD mechanism is introduced to explicitly model hesitation and ambiguity in agent judgments, thereby preventing irrational decisions. Second, a connection adjustment rule based on opinion similarity is developed, enabling agents to adaptively update their communication links and better reflect the evolving nature of social relationships. Third, linguistic terms are used to describe agent opinions, allowing the model to handle subjective, vague, or incomplete information more effectively. Finally, an integrated multi-agent decision-making framework is constructed, which simultaneously considers individual uncertainty, opinion evolution, and network dynamics. The proposed model is applied to a multi-UAV cooperative decision-making scenario, where simulation results and consensus analysis demonstrate its effectiveness. Experimental comparisons further verify the advantages of the algorithm in enhancing system stability and representing realistic decision-making behaviors.
Connecting the Dots in Trustworthy Artificial Intelligence: From AI Principles, Ethics, and Key Requirements to Responsible AI Systems and Regulation
May 02, 2023



Trustworthy Artificial Intelligence (AI) is based on seven technical requirements sustained over three main pillars that should be met throughout the system's entire life cycle: it should be (1) lawful, (2) ethical, and (3) robust, both from a technical and a social perspective. However, attaining truly trustworthy AI concerns a wider vision that comprises the trustworthiness of all processes and actors that are part of the system's life cycle, and considers previous aspects from different lenses. A more holistic vision contemplates four essential axes: the global principles for ethical use and development of AI-based systems, a philosophical take on AI ethics, a risk-based approach to AI regulation, and the mentioned pillars and requirements. The seven requirements (human agency and oversight; robustness and safety; privacy and data governance; transparency; diversity, non-discrimination and fairness; societal and environmental wellbeing; and accountability) are analyzed from a triple perspective: What each requirement for trustworthy AI is, Why it is needed, and How each requirement can be implemented in practice. On the other hand, a practical approach to implement trustworthy AI systems allows defining the concept of responsibility of AI-based systems facing the law, through a given auditing process. Therefore, a responsible AI system is the resulting notion we introduce in this work, and a concept of utmost necessity that can be realized through auditing processes, subject to the challenges posed by the use of regulatory sandboxes. Our multidisciplinary vision of trustworthy AI also includes a regulation debate, with the purpose of serving as an entry point to this crucial field in the present and future progress of our society.
A Survey on Federated Learning and its Applications for Accelerating Industrial Internet of Things
Apr 21, 2021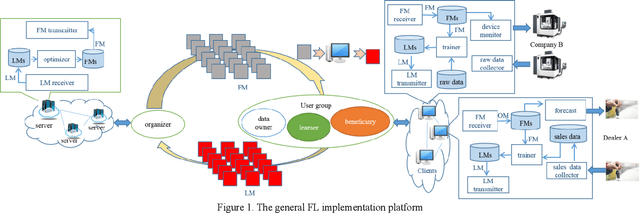
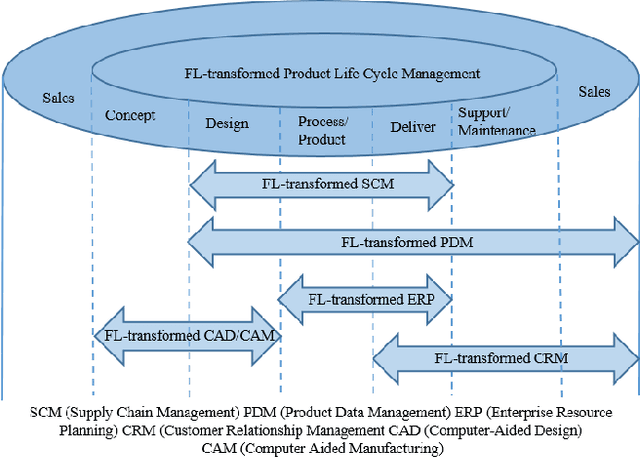

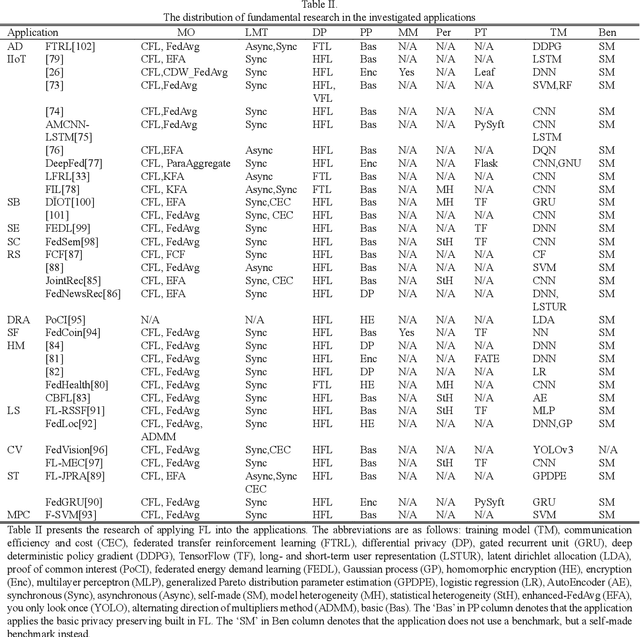
Federated learning (FL) brings collaborative intelligence into industries without centralized training data to accelerate the process of Industry 4.0 on the edge computing level. FL solves the dilemma in which enterprises wish to make the use of data intelligence with security concerns. To accelerate industrial Internet of things with the further leverage of FL, existing achievements on FL are developed from three aspects: 1) define terminologies and elaborate a general framework of FL for accommodating various scenarios; 2) discuss the state-of-the-art of FL on fundamental researches including data partitioning, privacy preservation, model optimization, local model transportation, personalization, motivation mechanism, platform & tools, and benchmark; 3) discuss the impacts of FL from the economic perspective. To attract more attention from industrial academia and practice, a FL-transformed manufacturing paradigm is presented, and future research directions of FL are given and possible immediate applications in Industry 4.0 domain are also proposed.
Sentiment Analysis based Multi-person Multi-criteria Decision Making Methodology: Using Natural Language Processing and Deep Learning for Decision Aid
Jul 31, 2020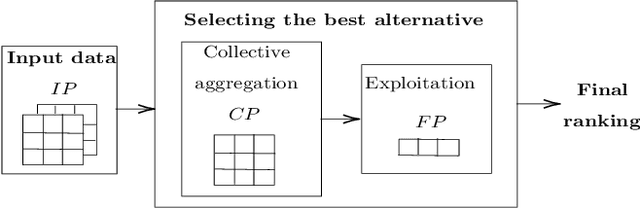
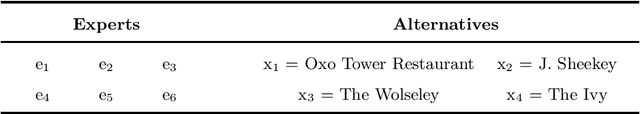

Decision making models are constrained by taking the expert evaluations with pre-defined numerical or linguistic terms. We claim that the use of sentiment analysis will allow decision making models to consider expert evaluations in natural language. Accordingly, we propose the Sentiment Analysis based Multi-person Multi-criteria Decision Making (SA-MpMcDM) methodology, which builds the expert evaluations from their natural language reviews, and even from their numerical ratings if they are available. The SA-MpMcDM methodology incorporates an end-to-end multi-task deep learning model for aspect based sentiment analysis, named DMuABSA model, able to identify the aspect categories mentioned in an expert review, and to distill their opinions and criteria. The individual expert evaluations are aggregated via a criteria weighting through the attention of the experts. We evaluate the methodology in a restaurant decision problem, hence we build the TripR-2020 dataset of restaurant reviews, which we manually annotate and release. We analyze the SA-MpMcDM methodology in different scenarios using and not using natural language and numerical evaluations. The analysis shows that the combination of both sources of information results in a higher quality preference vector.
Reciprocal Recommender Systems: Analysis of State-of-Art Literature, Challenges and Opportunities on Social Recommendation
Jul 17, 2020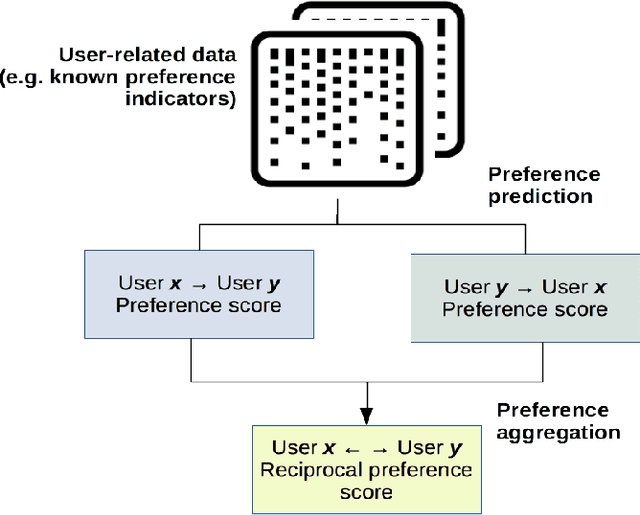
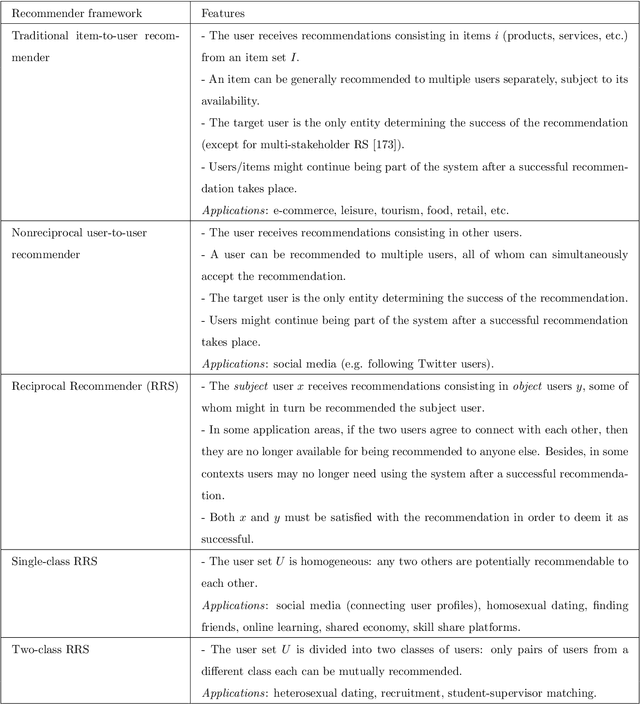
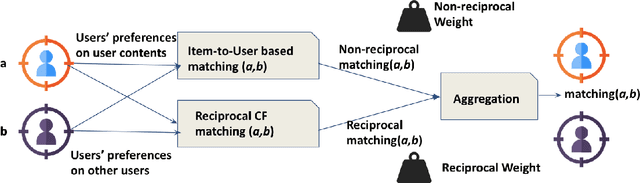
Many social services including online dating, social media, recruitment and online learning, largely rely on \matching people with the right people". The success of these services and the user experience with them often depends on their ability to match users. Reciprocal Recommender Systems (RRS) arose to facilitate this process by identifying users who are a potential match for each other, based on information provided by them. These systems are inherently more complex than user-item recommendation approaches and unidirectional user recommendation services, since they need to take into account both users' preferences towards each other in the recommendation process. This entails not only predicting accurate preference estimates as classical recommenders do, but also defining adequate fusion processes for aggregating user-to-user preferential information. The latter is a crucial and distinctive, yet barely investigated aspect in RRS research. This paper presents a snapshot analysis of the extant literature to summarize the state-of-the-art RRS research to date, focusing on the fundamental features that differentiate RRSs from other classes of recommender systems. Following this, we discuss the challenges and opportunities for future research on RRSs, with special focus on (i) fusion strategies to account for reciprocity and (ii) emerging application domains related to social recommendation.
Composite Monte Carlo Decision Making under High Uncertainty of Novel Coronavirus Epidemic Using Hybridized Deep Learning and Fuzzy Rule Induction
Mar 22, 2020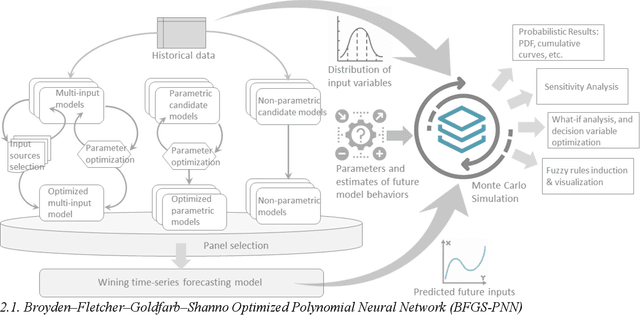
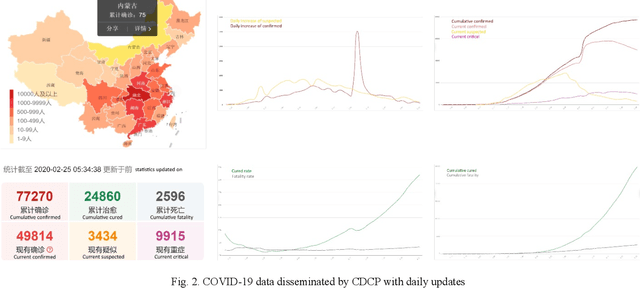
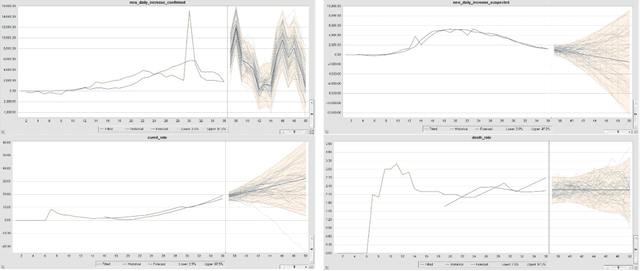

In the advent of the novel coronavirus epidemic since December 2019, governments and authorities have been struggling to make critical decisions under high uncertainty at their best efforts. Composite Monte-Carlo (CMC) simulation is a forecasting method which extrapolates available data which are broken down from multiple correlated/casual micro-data sources into many possible future outcomes by drawing random samples from some probability distributions. For instance, the overall trend and propagation of the infested cases in China are influenced by the temporal-spatial data of the nearby cities around the Wuhan city (where the virus is originated from), in terms of the population density, travel mobility, medical resources such as hospital beds and the timeliness of quarantine control in each city etc. Hence a CMC is reliable only up to the closeness of the underlying statistical distribution of a CMC, that is supposed to represent the behaviour of the future events, and the correctness of the composite data relationships. In this paper, a case study of using CMC that is enhanced by deep learning network and fuzzy rule induction for gaining better stochastic insights about the epidemic development is experimented. Instead of applying simplistic and uniform assumptions for a MC which is a common practice, a deep learning-based CMC is used in conjunction of fuzzy rule induction techniques. As a result, decision makers are benefited from a better fitted MC outputs complemented by min-max rules that foretell about the extreme ranges of future possibilities with respect to the epidemic.