 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCentralized Training with Hybrid Execution in Multi-Agent Reinforcement Learning
Paper and Code

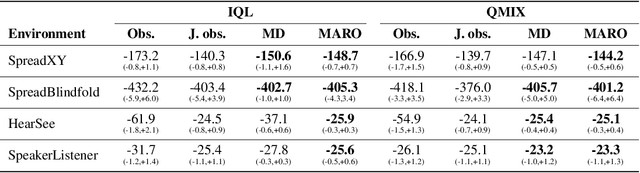

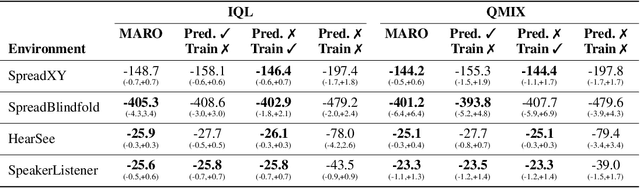
We introduce hybrid execution in multi-agent reinforcement learning (MARL), a new paradigm in which agents aim to successfully perform cooperative tasks with any communication level at execution time by taking advantage of information-sharing among the agents. Under hybrid execution, the communication level can range from a setting in which no communication is allowed between agents (fully decentralized), to a setting featuring full communication (fully centralized). To formalize our setting, we define a new class of multi-agent partially observable Markov decision processes (POMDPs) that we name hybrid-POMDPs, which explicitly models a communication process between the agents. We contribute MARO, an approach that combines an autoregressive predictive model to estimate missing agents' observations, and a dropout-based RL training scheme that simulates different communication levels during the centralized training phase. We evaluate MARO on standard scenarios and extensions of previous benchmarks tailored to emphasize the negative impact of partial observability in MARL. Experimental results show that our method consistently outperforms baselines, allowing agents to act with faulty communication while successfully exploiting shared information.