 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Value Decomposition Networks with Networked Agents
Feb 11, 2025



We investigate the problem of distributed training under partial observability, whereby cooperative multi-agent reinforcement learning agents (MARL) maximize the expected cumulative joint reward. We propose distributed value decomposition networks (DVDN) that generate a joint Q-function that factorizes into agent-wise Q-functions. Whereas the original value decomposition networks rely on centralized training, our approach is suitable for domains where centralized training is not possible and agents must learn by interacting with the physical environment in a decentralized manner while communicating with their peers. DVDN overcomes the need for centralized training by locally estimating the shared objective. We contribute with two innovative algorithms, DVDN and DVDN (GT), for the heterogeneous and homogeneous agents settings respectively. Empirically, both algorithms approximate the performance of value decomposition networks, in spite of the information loss during communication, as demonstrated in ten MARL tasks in three standard environments.
Networked Agents in the Dark: Team Value Learning under Partial Observability
Jan 15, 2025



We propose a novel cooperative multi-agent reinforcement learning (MARL) approach for networked agents. In contrast to previous methods that rely on complete state information or joint observations, our agents must learn how to reach shared objectives under partial observability. During training, they collect individual rewards and approximate a team value function through local communication, resulting in cooperative behavior. To describe our problem, we introduce the networked dynamic partially observable Markov game framework, where agents communicate over a switching topology communication network. Our distributed method, DNA-MARL, uses a consensus mechanism for local communication and gradient descent for local computation. DNA-MARL increases the range of the possible applications of networked agents, being well-suited for real world domains that impose privacy and where the messages may not reach their recipients. We evaluate DNA-MARL across benchmark MARL scenarios. Our results highlight the superior performance of DNA-MARL over previous methods.
A Methodology for the Development of RL-Based Adaptive Traffic Signal Controllers
Jan 24, 2021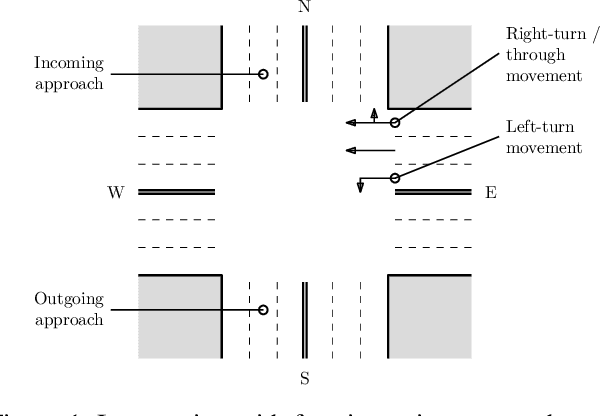


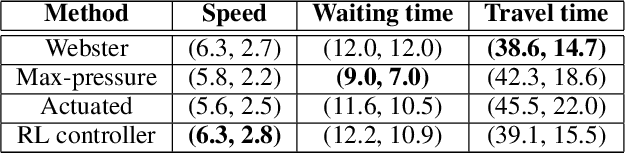
This article proposes a methodology for the development of adaptive traffic signal controllers using reinforcement learning. Our methodology addresses the lack of standardization in the literature that renders the comparison of approaches in different works meaningless, due to differences in metrics, environments, and even experimental design and methodology. The proposed methodology thus comprises all the steps necessary to develop, deploy and evaluate an adaptive traffic signal controller -- from simulation setup to problem formulation and experimental design. We illustrate the proposed methodology in two simple scenarios, highlighting how its different steps address limitations found in the current literature.