 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling long-term interactions to enhance action recognition
Paper and Code
Apr 23, 2021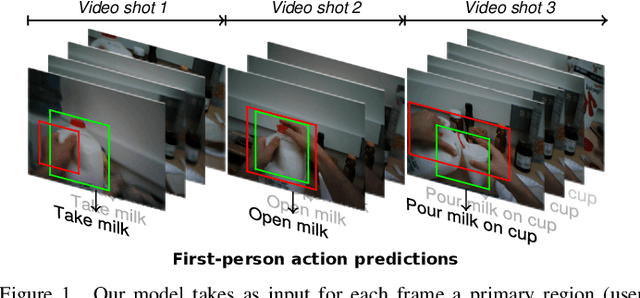

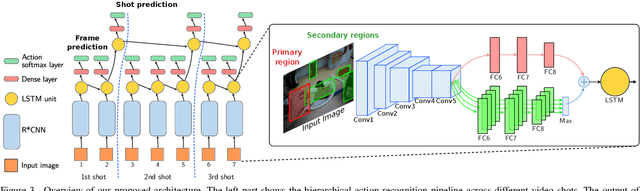
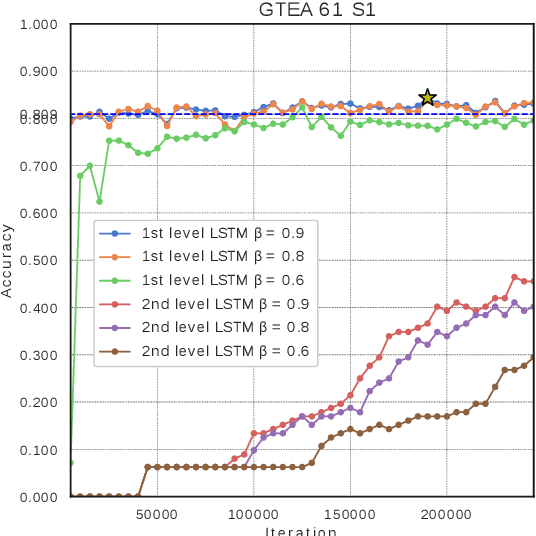
In this paper, we propose a new approach to under-stand actions in egocentric videos that exploits the semantics of object interactions at both frame and temporal levels. At the frame level, we use a region-based approach that takes as input a primary region roughly corresponding to the user hands and a set of secondary regions potentially corresponding to the interacting objects and calculates the action score through a CNN formulation. This information is then fed to a Hierarchical LongShort-Term Memory Network (HLSTM) that captures temporal dependencies between actions within and across shots. Ablation studies thoroughly validate the proposed approach, showing in particular that both levels of the HLSTM architecture contribute to performance improvement. Furthermore, quantitative comparisons show that the proposed approach outperforms the state-of-the-art in terms of action recognition on standard benchmarks,without relying on motion information