 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of a Direct Separation Method Based on Adaptive Chirplet Transform for Signals with Crossover Instantaneous Frequencies
May 26, 2022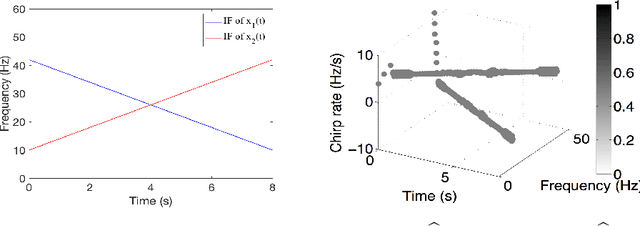
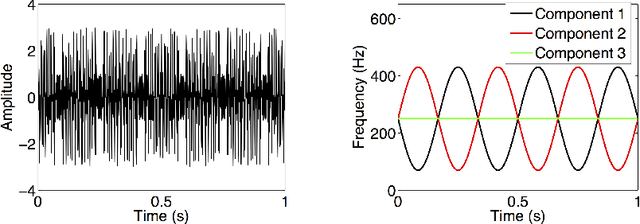
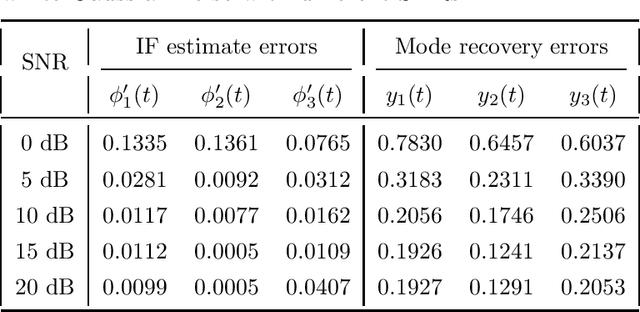
In many applications, it is necessary to retrieve the sub-signal building blocks of a multi-component signal, which is usually non-stationary in real-world and real-life applications. Empirical mode decomposition (EMD), synchrosqueezing transform (SST), signal separation operation (SSO), and iterative filtering decomposition (IFD) have been proposed and developed for this purpose. However, these computational methods are restricted by the specification of well-separation of the sub-signal frequency curves for multi-component signals. On the other hand, the chirplet transform-based signal separation scheme (CT3S) that extends SSO from the two-dimensional "time-frequency" plane to the three-dimensional "time-frequency-chirp rate" space was recently proposed in our recent work to remove the frequency-separation specification, and thereby allowing "frequency crossing". The main objective of this present paper is to carry out an in-depth error analysis study of instantaneous frequency estimation and component recovery for the CT3S method.
Time-Scale-Chirp_rate Operator for Recovery of Non-stationary Signal Components with Crossover Instantaneous Frequency Curves
Dec 27, 2020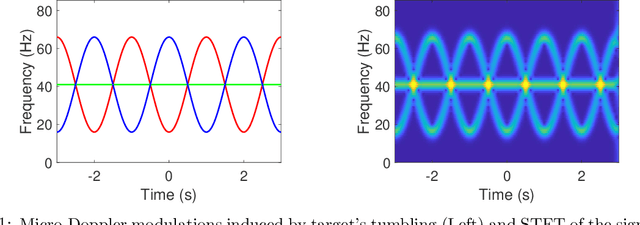
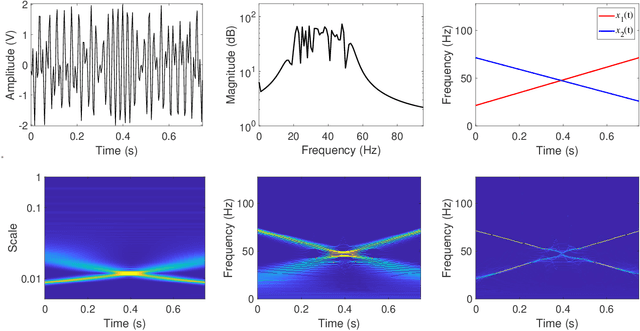

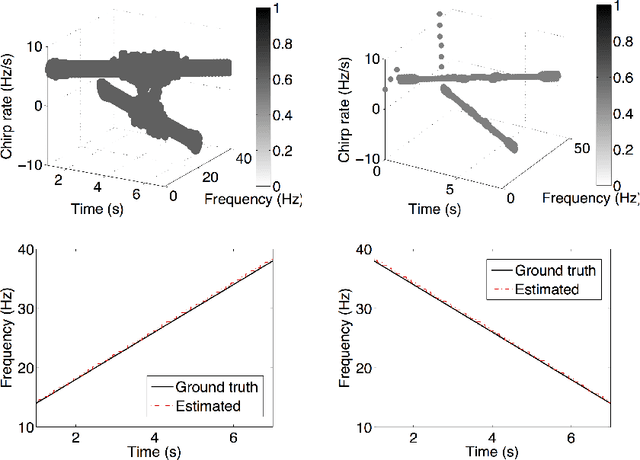
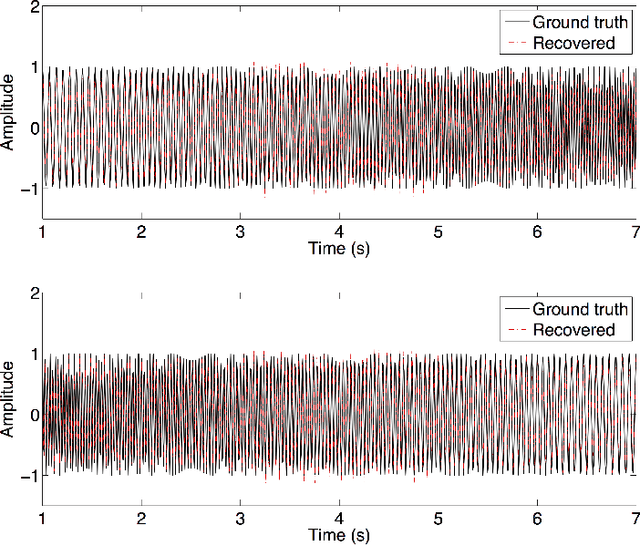
The objective of this paper is to introduce an innovative approach for the recovery of non-stationary signal components with possibly cross-over instantaneous frequency (IF) curves from a multi-component blind-source signal. The main idea is to incorporate a chirp rate parameter with the time-scale continuous wavelet-like transformation, by considering the quadratic phase representation of the signal components. Hence-forth, even if two IF curves cross, the two corresponding signal components can still be separated and recovered, provided that their chirp rates are different. In other words, signal components with the same IF value at any time instant could still be recovered. To facilitate our presentation, we introduce the notion of time-scale-chirp_rate (TSC-R) recovery transform or TSC-R recovery operator to develop a TSC-R theory for the 3-dimensional space of time, scale, chirp rate. Our theoretical development is based on the approximation of the non-stationary signal components with linear chirps and applying the proposed adaptive TSC-R transform to the multi-component blind-source signal to obtain fairly accurate error bounds of IF estimations and signal components recovery. Several numerical experimental results are presented to demonstrate the out-performance of the proposed method over all existing time-frequency and time-scale approaches in the published literature, particularly for non-stationary source signals with crossover IFs.
Theory inspired deep network for instantaneous-frequency extraction and signal components recovery from discrete blind-source data
Jan 31, 2020
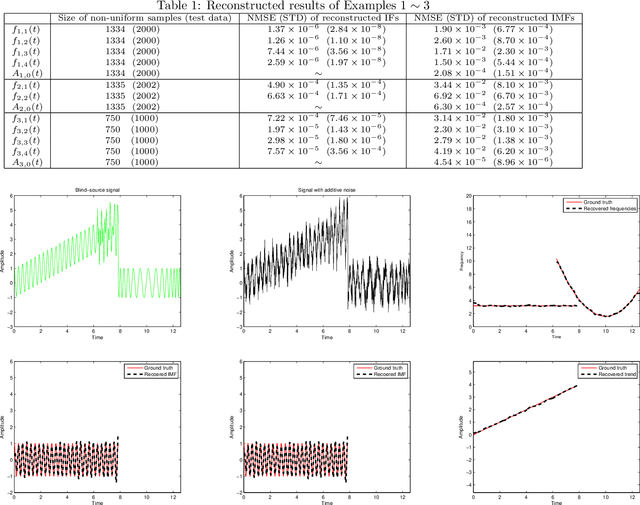
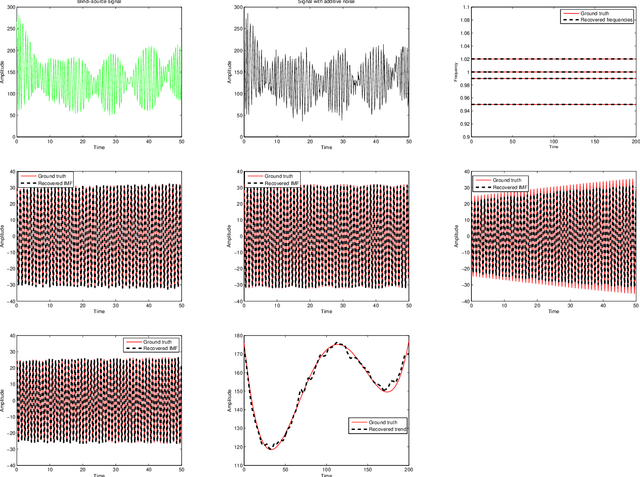
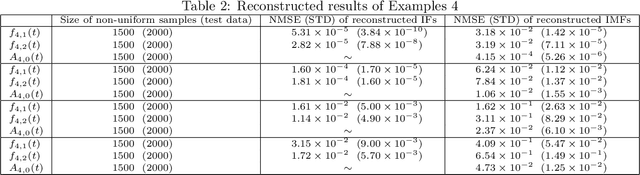
This paper is concerned with the inverse problem of recovering the unknown signal components, along with extraction of their instantaneous frequencies (IFs), governed by the adaptive harmonic model (AHM), from discrete (and possibly non-uniform) samples of the blind-source composite signal. None of the existing decomposition methods and algorithms, including the most popular empirical mode decomposition (EMD) computational scheme and its current modifications, is capable of solving this inverse problem. In order to meet the AHM formulation and to extract the IFs of the decomposed components, called intrinsic mode functions (IMFs), each IMF of EMD is extended to an analytic function in the upper half of the complex plane via the Hilbert transform, followed by taking the real part of the polar form of the analytic extension. Unfortunately, this approach most often fails to resolve the inverse problem satisfactorily. More recently, to resolve the inverse problem, the notion of synchrosqueezed wavelet transform (SST) was proposed by Daubechies and Maes, and further developed in many other papers, while a more direct method, called signal separation operation (SSO), was proposed and developed in our previous work published in the journal, Applied and Computational Harmonic Analysis, vol. 30(2):243-261, 2016. In the present paper, we propose a synthesis of SSO using a deep neural network, based directly on a discrete sample set, that may be non-uniformly sampled, of the blind-source signal. Our method is localized, as illustrated by a number of numerical examples, including components with different signal arrival and departure times. It also yields short-term prediction of the signal components, along with their IFs. Our neural networks are inspired by theory, designed so that they do not require any training in the traditional sense.
Realization of spatial sparseness by deep ReLU nets with massive data
Dec 16, 2019
The great success of deep learning poses urgent challenges for understanding its working mechanism and rationality. The depth, structure, and massive size of the data are recognized to be three key ingredients for deep learning. Most of the recent theoretical studies for deep learning focus on the necessity and advantages of depth and structures of neural networks. In this paper, we aim at rigorous verification of the importance of massive data in embodying the out-performance of deep learning. To approximate and learn spatially sparse and smooth functions, we establish a novel sampling theorem in learning theory to show the necessity of massive data. We then prove that implementing the classical empirical risk minimization on some deep nets facilitates in realization of the optimal learning rates derived in the sampling theorem. This perhaps explains why deep learning performs so well in the era of big data.
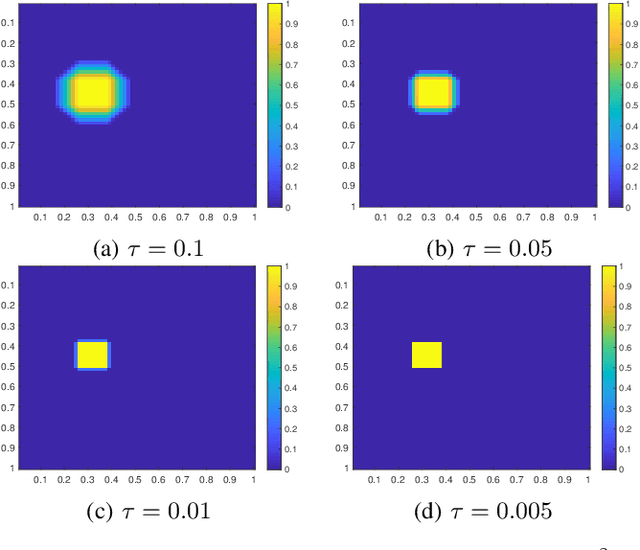
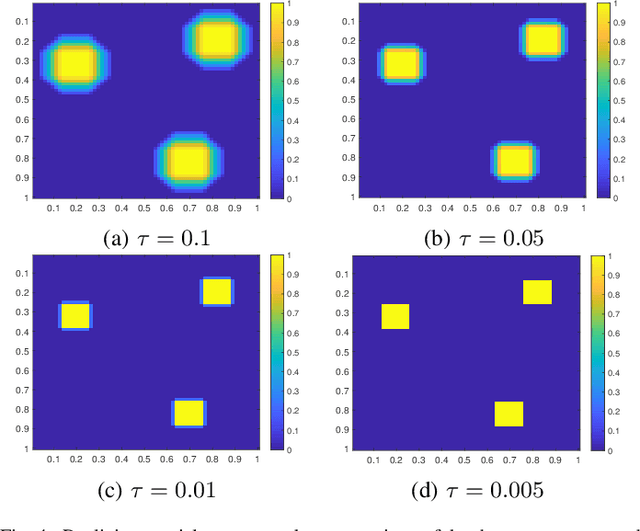
CASS: Cross Adversarial Source Separation via Autoencoder
May 23, 2019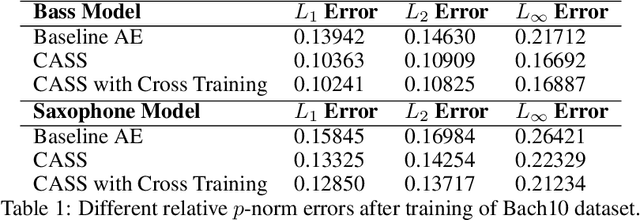
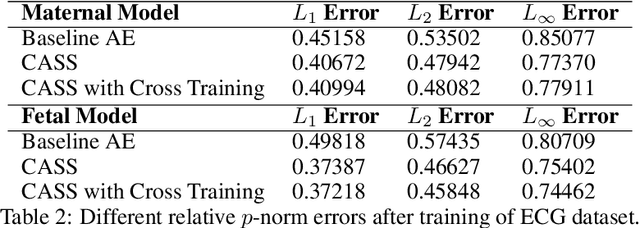
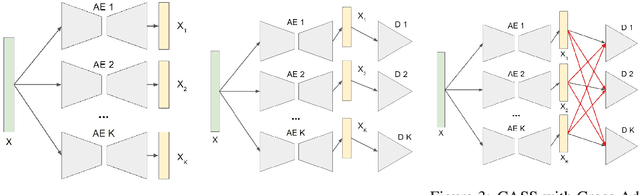
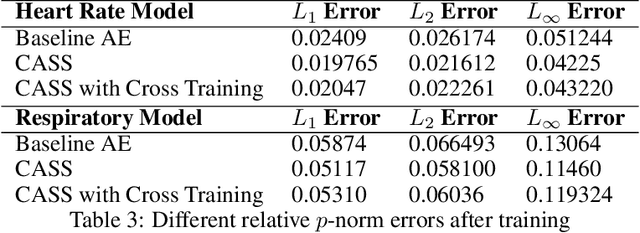
This paper introduces a cross adversarial source separation (CASS) framework via autoencoder, a new model that aims at separating an input signal consisting of a mixture of multiple components into individual components defined via adversarial learning and autoencoder fitting. CASS unifies popular generative networks like auto-encoders (AEs) and generative adversarial networks (GANs) in a single framework. The basic building block that filters the input signal and reconstructs the $i$-th target component is a pair of deep neural networks $\mathcal{EN}_i$ and $\mathcal{DE}_i$ as an encoder for dimension reduction and a decoder for component reconstruction, respectively. The decoder $\mathcal{DE}_i$ as a generator is enhanced by a discriminator network $\mathcal{D}_i$ that favors signal structures of the $i$-th component in the $i$-th given dataset as guidance through adversarial learning. In contrast with existing practices in AEs which trains each Auto-Encoder independently, or in GANs that share the same generator, we introduce cross adversarial training that emphasizes adversarial relation between any arbitrary network pairs $(\mathcal{DE}_i,\mathcal{D}_j)$, achieving state-of-the-art performance especially when target components share similar data structures.
Deep Neural Networks for Rotation-Invariance Approximation and Learning
Apr 03, 2019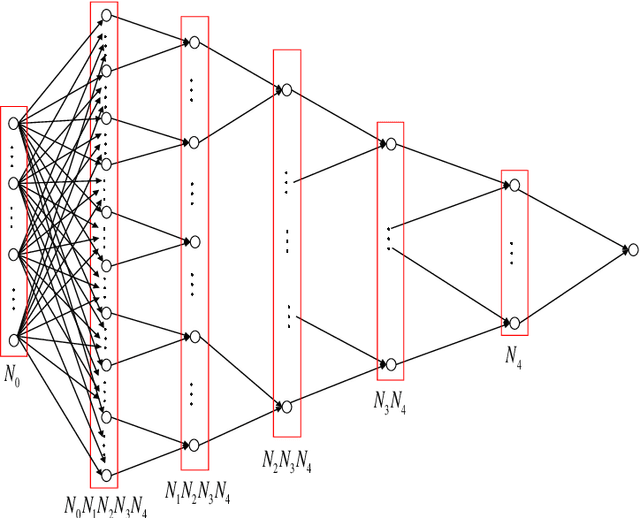
Based on the tree architecture, the objective of this paper is to design deep neural networks with two or more hidden layers (called deep nets) for realization of radial functions so as to enable rotational invariance for near-optimal function approximation in an arbitrarily high dimensional Euclidian space. It is shown that deep nets have much better performance than shallow nets (with only one hidden layer) in terms of approximation accuracy and learning capabilities. In particular, for learning radial functions, it is shown that near-optimal rate can be achieved by deep nets but not by shallow nets. Our results illustrate the necessity of depth in neural network design for realization of rotation-invariance target functions.
Construction of neural networks for realization of localized deep learning
Mar 09, 2018The subject of deep learning has recently attracted users of machine learning from various disciplines, including: medical diagnosis and bioinformatics, financial market analysis and online advertisement, speech and handwriting recognition, computer vision and natural language processing, time series forecasting, and search engines. However, theoretical development of deep learning is still at its infancy. The objective of this paper is to introduce a deep neural network (also called deep-net) approach to localized manifold learning, with each hidden layer endowed with a specific learning task. For the purpose of illustrations, we only focus on deep-nets with three hidden layers, with the first layer for dimensionality reduction, the second layer for bias reduction, and the third layer for variance reduction. A feedback component also designed to eliminate outliers. The main theoretical result in this paper is the order $\mathcal O\left(m^{-2s/(2s+d)}\right)$ of approximation of the regression function with regularity $s$, in terms of the number $m$ of sample points, where the (unknown) manifold dimension $d$ replaces the dimension $D$ of the sampling (Euclidean) space for shallow nets.
A unified method for super-resolution recovery and real exponential-sum separation
Jul 26, 2017In this paper, motivated by diffraction of traveling light waves, a simple mathematical model is proposed, both for the multivariate super-resolution problem and the problem of blind-source separation of real-valued exponential sums. This model facilitates the development of a unified theory and a unified solution of both problems in this paper. Our consideration of the super-resolution problem is aimed at applications to fluorescence microscopy and observational astronomy, and the motivation for our consideration of the second problem is the current need of extracting multivariate exponential features in magnetic resonance spectroscopy (MRS) for the neurologist and radiologist as well as for providing a mathematical tool for isotope separation in Nuclear Chemistry. The unified method introduced in this paper can be easily realized by processing only finitely many data, sampled at locations that are not necessarily prescribed in advance, with computational scheme consisting only of matrix - vector multiplication, peak finding, and clustering.
A Fourier-invariant method for locating point-masses and computing their attributes
Jul 26, 2017Motivated by the interest of observing the growth of cancer cells among normal living cells and exploring how galaxies and stars are truly formed, the objective of this paper is to introduce a rigorous and effective method for counting point-masses, determining their spatial locations, and computing their attributes. Based on computation of Hermite moments that are Fourier-invariant, our approach facilitates the processing of both spatial and Fourier data in any dimension.
Deep nets for local manifold learning
Jul 24, 2016The problem of extending a function $f$ defined on a training data $\mathcal{C}$ on an unknown manifold $\mathbb{X}$ to the entire manifold and a tubular neighborhood of this manifold is considered in this paper. For $\mathbb{X}$ embedded in a high dimensional ambient Euclidean space $\mathbb{R}^D$, a deep learning algorithm is developed for finding a local coordinate system for the manifold {\bf without eigen--decomposition}, which reduces the problem to the classical problem of function approximation on a low dimensional cube. Deep nets (or multilayered neural networks) are proposed to accomplish this approximation scheme by using the training data. Our methods do not involve such optimization techniques as back--propagation, while assuring optimal (a priori) error bounds on the output in terms of the number of derivatives of the target function. In addition, these methods are universal, in that they do not require a prior knowledge of the smoothness of the target function, but adjust the accuracy of approximation locally and automatically, depending only upon the local smoothness of the target function. Our ideas are easily extended to solve both the pre--image problem and the out--of--sample extension problem, with a priori bounds on the growth of the function thus extended.