 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTheory inspired deep network for instantaneous-frequency extraction and signal components recovery from discrete blind-source data
Jan 31, 2020
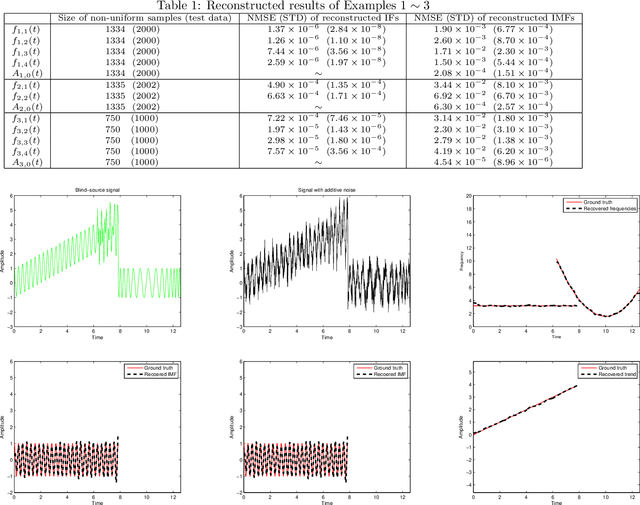
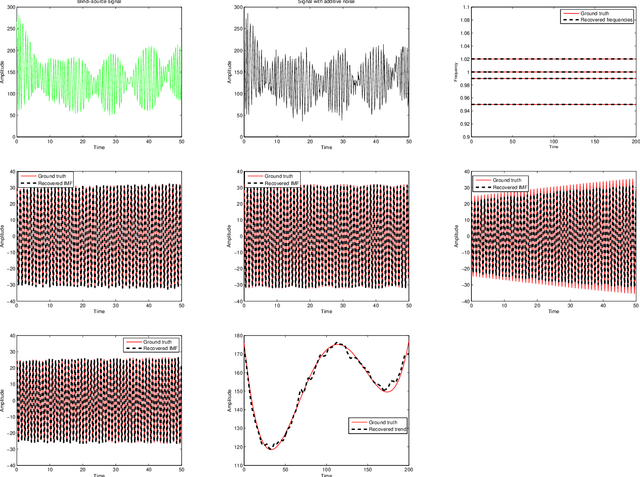
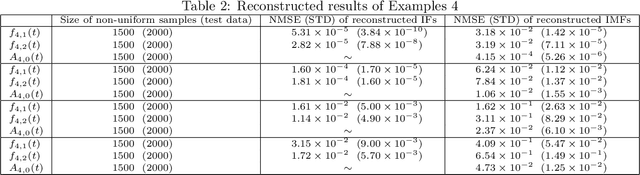
This paper is concerned with the inverse problem of recovering the unknown signal components, along with extraction of their instantaneous frequencies (IFs), governed by the adaptive harmonic model (AHM), from discrete (and possibly non-uniform) samples of the blind-source composite signal. None of the existing decomposition methods and algorithms, including the most popular empirical mode decomposition (EMD) computational scheme and its current modifications, is capable of solving this inverse problem. In order to meet the AHM formulation and to extract the IFs of the decomposed components, called intrinsic mode functions (IMFs), each IMF of EMD is extended to an analytic function in the upper half of the complex plane via the Hilbert transform, followed by taking the real part of the polar form of the analytic extension. Unfortunately, this approach most often fails to resolve the inverse problem satisfactorily. More recently, to resolve the inverse problem, the notion of synchrosqueezed wavelet transform (SST) was proposed by Daubechies and Maes, and further developed in many other papers, while a more direct method, called signal separation operation (SSO), was proposed and developed in our previous work published in the journal, Applied and Computational Harmonic Analysis, vol. 30(2):243-261, 2016. In the present paper, we propose a synthesis of SSO using a deep neural network, based directly on a discrete sample set, that may be non-uniformly sampled, of the blind-source signal. Our method is localized, as illustrated by a number of numerical examples, including components with different signal arrival and departure times. It also yields short-term prediction of the signal components, along with their IFs. Our neural networks are inspired by theory, designed so that they do not require any training in the traditional sense.
Dimension independent bounds for general shallow networks
Aug 26, 2019This paper proves an abstract theorem addressing in a unified manner two important problems in function approximation: avoiding curse of dimensionality and estimating the degree of approximation for out-of-sample extension in manifold learning. We consider an abstract (shallow) network that includes, for example, neural networks, radial basis function networks, and kernels on data defined manifolds used for function approximation in various settings. A deep network is obtained by a composition of the shallow networks according to a directed acyclic graph, representing the architecture of the deep network. In this paper, we prove dimension independent bounds for approximation by shallow networks in the very general setting of what we have called $G$-networks on a compact metric measure space, where the notion of dimension is defined in terms of the cardinality of maximal distinguishable sets, generalizing the notion of dimension of a cube or a manifold. Our techniques give bounds that improve without saturation with the smoothness of the kernel involved in an integral representation of the target function. In the context of manifold learning, our bounds provide estimates on the degree of approximation for an out-of-sample extension of the target function to the ambient space. One consequence of our theorem is that without the requirement of robust parameter selection, deep networks using a non-smooth activation function such as the ReLU, do not provide any significant advantage over shallow networks in terms of the degree of approximation alone.
Function approximation with zonal function networks with activation functions analogous to the rectified linear unit functions
Jul 08, 2018
A zonal function (ZF) network on the $q$ dimensional sphere $\mathbb{S}^q$ is a network of the form $\mathbf{x}\mapsto \sum_{k=1}^n a_k\phi(\mathbf{x}\cdot\mathbf{x}_k)$ where $\phi :[-1,1]\to\mathbf{R}$ is the activation function, $\mathbf{x}_k\in\mathbb{S}^q$ are the centers, and $a_k\in\mathbb{R}$. While the approximation properties of such networks are well studied in the context of positive definite activation functions, recent interest in deep and shallow networks motivate the study of activation functions of the form $\phi(t)=|t|$, which are not positive definite. In this paper, we define an appropriate smoothess class and establish approximation properties of such networks for functions in this class. The centers can be chosen independently of the target function, and the coefficients are linear combinations of the training data. The constructions preserve rotational symmetries.
Deep Algorithms: designs for networks
Jun 06, 2018
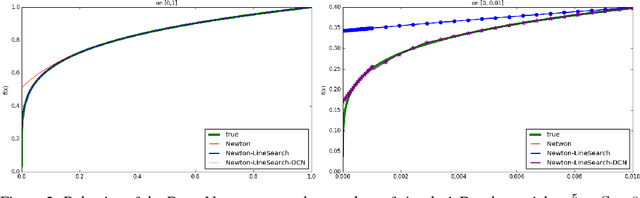
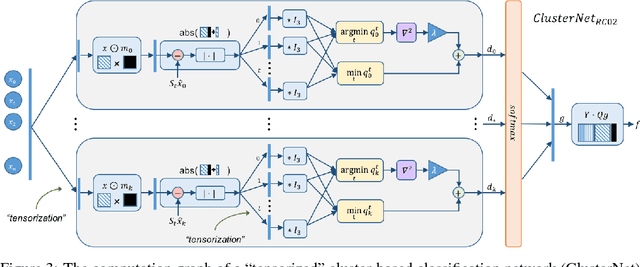
A new design methodology for neural networks that is guided by traditional algorithm design is presented. To prove our point, we present two heuristics and demonstrate an algorithmic technique for incorporating additional weights in their signal-flow graphs. We show that with training the performance of these networks can not only exceed the performance of the initial network, but can match the performance of more-traditional neural network architectures. A key feature of our approach is that these networks are initialized with parameters that provide a known performance threshold for the architecture on a given task.
A unified method for super-resolution recovery and real exponential-sum separation
Jul 26, 2017In this paper, motivated by diffraction of traveling light waves, a simple mathematical model is proposed, both for the multivariate super-resolution problem and the problem of blind-source separation of real-valued exponential sums. This model facilitates the development of a unified theory and a unified solution of both problems in this paper. Our consideration of the super-resolution problem is aimed at applications to fluorescence microscopy and observational astronomy, and the motivation for our consideration of the second problem is the current need of extracting multivariate exponential features in magnetic resonance spectroscopy (MRS) for the neurologist and radiologist as well as for providing a mathematical tool for isotope separation in Nuclear Chemistry. The unified method introduced in this paper can be easily realized by processing only finitely many data, sampled at locations that are not necessarily prescribed in advance, with computational scheme consisting only of matrix - vector multiplication, peak finding, and clustering.
A Fourier-invariant method for locating point-masses and computing their attributes
Jul 26, 2017Motivated by the interest of observing the growth of cancer cells among normal living cells and exploring how galaxies and stars are truly formed, the objective of this paper is to introduce a rigorous and effective method for counting point-masses, determining their spatial locations, and computing their attributes. Based on computation of Hermite moments that are Fourier-invariant, our approach facilitates the processing of both spatial and Fourier data in any dimension.