 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC-MoE: Switch Conformer Mixture of Experts for Unified Streaming and Non-streaming Code-Switching ASR
Jun 26, 2024In this work, we propose a Switch-Conformer-based MoE system named SC-MoE for unified streaming and non-streaming code-switching (CS) automatic speech recognition (ASR), where we design a streaming MoE layer consisting of three language experts, which correspond to Mandarin, English, and blank, respectively, and equipped with a language identification (LID) network with a Connectionist Temporal Classification (CTC) loss as a router in the encoder of SC-MoE to achieve a real-time streaming CS ASR system. To further utilize the language information embedded in text, we also incorporate MoE layers into the decoder of SC-MoE. In addition, we introduce routers into every MoE layer of the encoder and the decoder and achieve better recognition performance. Experimental results show that the SC-MoE significantly improves CS ASR performances over baseline with comparable computational efficiency.
The RoyalFlush Automatic Speech Diarization and Recognition System for In-Car Multi-Channel Automatic Speech Recognition Challenge
May 09, 2024

This paper presents our system submission for the In-Car Multi-Channel Automatic Speech Recognition (ICMC-ASR) Challenge, which focuses on speaker diarization and speech recognition in complex multi-speaker scenarios. To address these challenges, we develop end-to-end speaker diarization models that notably decrease the diarization error rate (DER) by 49.58\% compared to the official baseline on the development set. For speech recognition, we utilize self-supervised learning representations to train end-to-end ASR models. By integrating these models, we achieve a character error rate (CER) of 16.93\% on the track 1 evaluation set, and a concatenated minimum permutation character error rate (cpCER) of 25.88\% on the track 2 evaluation set.
The RoyalFlush System of Speech Recognition for M2MeT Challenge
Feb 03, 2022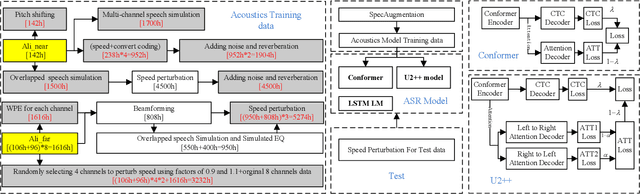
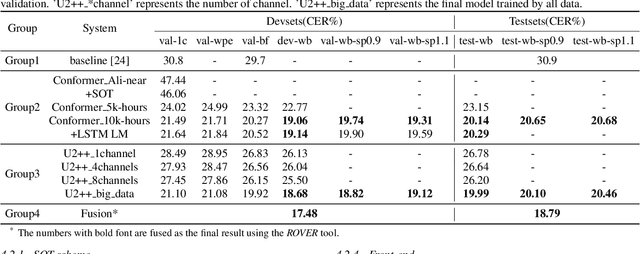
This paper describes our RoyalFlush system for the track of multi-speaker automatic speech recognition (ASR) in the M2MeT challenge. We adopted the serialized output training (SOT) based multi-speakers ASR system with large-scale simulation data. Firstly, we investigated a set of front-end methods, including multi-channel weighted predicted error (WPE), beamforming, speech separation, speech enhancement and so on, to process training, validation and test sets. But we only selected WPE and beamforming as our frontend methods according to their experimental results. Secondly, we made great efforts in the data augmentation for multi-speaker ASR, mainly including adding noise and reverberation, overlapped speech simulation, multi-channel speech simulation, speed perturbation, front-end processing, and so on, which brought us a great performance improvement. Finally, in order to make full use of the performance complementary of different model architecture, we trained the standard conformer based joint CTC/Attention (Conformer) and U2++ ASR model with a bidirectional attention decoder, a modification of Conformer, to fuse their results. Comparing with the official baseline system, our system got a 12.22% absolute Character Error Rate (CER) reduction on the validation set and 12.11% on the test set.