 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Speech Emotion Recognition via Feature Distribution Adaptation Network
Nov 02, 2024



In this paper, we propose a novel deep inductive transfer learning framework, named feature distribution adaptation network, to tackle the challenging multi-modal speech emotion recognition problem. Our method aims to use deep transfer learning strategies to align visual and audio feature distributions to obtain consistent representation of emotion, thereby improving the performance of speech emotion recognition. In our model, the pre-trained ResNet-34 is utilized for feature extraction for facial expression images and acoustic Mel spectrograms, respectively. Then, the cross-attention mechanism is introduced to model the intrinsic similarity relationships of multi-modal features. Finally, the multi-modal feature distribution adaptation is performed efficiently with feed-forward network, which is extended using the local maximum mean discrepancy loss. Experiments are carried out on two benchmark datasets, and the results demonstrate that our model can achieve excellent performance compared with existing ones.
Feature distribution Adaptation Network for Speech Emotion Recognition
Oct 29, 2024In this paper, we propose a novel deep inductive transfer learning framework, named feature distribution adaptation network, to tackle the challenging multi-modal speech emotion recognition problem. Our method aims to use deep transfer learning strategies to align visual and audio feature distributions to obtain consistent representation of emotion, thereby improving the performance of speech emotion recognition. In our model, the pre-trained ResNet-34 is utilized for feature extraction for facial expression images and acoustic Mel spectrograms, respectively. Then, the cross-attention mechanism is introduced to model the intrinsic similarity relationships of multi-modal features. Finally, the multi-modal feature distribution adaptation is performed efficiently with feed-forward network, which is extended using the local maximum mean discrepancy loss. Experiments are carried out on two benchmark datasets, and the results demonstrate that our model can achieve excellent performance compared with existing ones.Our code is available at https://github.com/shaokai1209/FDAN.
Enhancing Emotion Recognition in Incomplete Data: A Novel Cross-Modal Alignment, Reconstruction, and Refinement Framework
Jul 12, 2024


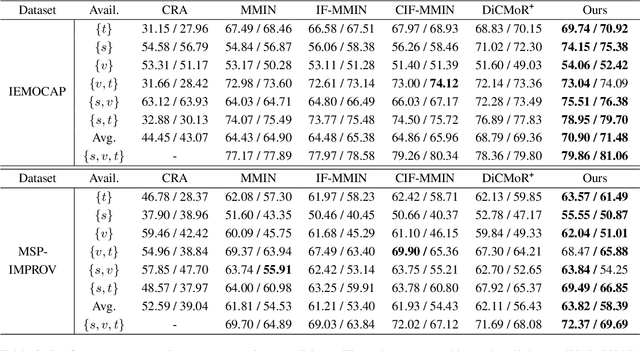
Multimodal emotion recognition systems rely heavily on the full availability of modalities, suffering significant performance declines when modal data is incomplete. To tackle this issue, we present the Cross-Modal Alignment, Reconstruction, and Refinement (CM-ARR) framework, an innovative approach that sequentially engages in cross-modal alignment, reconstruction, and refinement phases to handle missing modalities and enhance emotion recognition. This framework utilizes unsupervised distribution-based contrastive learning to align heterogeneous modal distributions, reducing discrepancies and modeling semantic uncertainty effectively. The reconstruction phase applies normalizing flow models to transform these aligned distributions and recover missing modalities. The refinement phase employs supervised point-based contrastive learning to disrupt semantic correlations and accentuate emotional traits, thereby enriching the affective content of the reconstructed representations. Extensive experiments on the IEMOCAP and MSP-IMPROV datasets confirm the superior performance of CM-ARR under conditions of both missing and complete modalities. Notably, averaged across six scenarios of missing modalities, CM-ARR achieves absolute improvements of 2.11% in WAR and 2.12% in UAR on the IEMOCAP dataset, and 1.71% and 1.96% in WAR and UAR, respectively, on the MSP-IMPROV dataset.