 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplace Scoring with Arrangement: A Contextual Set-to-Arrangement Framework for Learning-to-Rank
Paper and Code
Aug 05, 2023
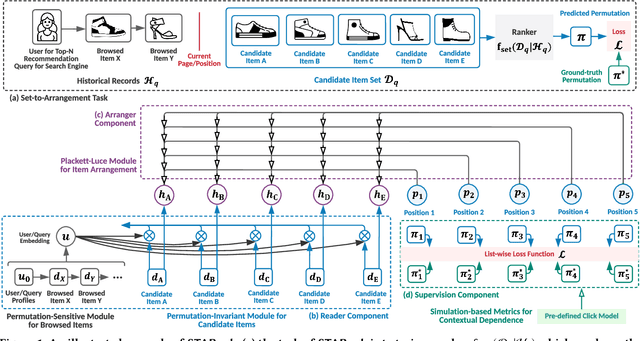


Learning-to-rank is a core technique in the top-N recommendation task, where an ideal ranker would be a mapping from an item set to an arrangement (a.k.a. permutation). Most existing solutions fall in the paradigm of probabilistic ranking principle (PRP), i.e., first score each item in the candidate set and then perform a sort operation to generate the top ranking list. However, these approaches neglect the contextual dependence among candidate items during individual scoring, and the sort operation is non-differentiable. To bypass the above issues, we propose Set-To-Arrangement Ranking (STARank), a new framework directly generates the permutations of the candidate items without the need for individually scoring and sort operations; and is end-to-end differentiable. As a result, STARank can operate when only the ground-truth permutations are accessible without requiring access to the ground-truth relevance scores for items. For this purpose, STARank first reads the candidate items in the context of the user browsing history, whose representations are fed into a Plackett-Luce module to arrange the given items into a list. To effectively utilize the given ground-truth permutations for supervising STARank, we leverage the internal consistency property of Plackett-Luce models to derive a computationally efficient list-wise loss. Experimental comparisons against 9 the state-of-the-art methods on 2 learning-to-rank benchmark datasets and 3 top-N real-world recommendation datasets demonstrate the superiority of STARank in terms of conventional ranking metrics. Notice that these ranking metrics do not consider the effects of the contextual dependence among the items in the list, we design a new family of simulation-based ranking metrics, where existing metrics can be regarded as special cases. STARank can consistently achieve better performance in terms of PBM and UBM simulation-based metrics.