 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSherry: Hardware-Efficient 1.25-Bit Ternary Quantization via Fine-grained Sparsification
Jan 12, 2026The deployment of Large Language Models (LLMs) on resource-constrained edge devices is increasingly hindered by prohibitive memory and computational requirements. While ternary quantization offers a compelling solution by reducing weights to {-1, 0, +1}, current implementations suffer from a fundamental misalignment with commodity hardware. Most existing methods must choose between 2-bit aligned packing, which incurs significant bit wastage, or 1.67-bit irregular packing, which degrades inference speed. To resolve this tension, we propose Sherry, a hardware-efficient ternary quantization framework. Sherry introduces a 3:4 fine-grained sparsity that achieves a regularized 1.25-bit width by packing blocks of four weights into five bits, restoring power-of-two alignment. Furthermore, we identify weight trapping issue in sparse ternary training, which leads to representational collapse. To address this, Sherry introduces Arenas, an annealing residual synapse mechanism that maintains representational diversity during training. Empirical evaluations on LLaMA-3.2 across five benchmarks demonstrate that Sherry matches state-of-the-art ternary performance while significantly reducing model size. Notably, on an Intel i7-14700HX CPU, our 1B model achieves zero accuracy loss compared to SOTA baselines while providing 25% bit savings and 10% speed up. The code is available at https://github.com/Tencent/AngelSlim .
Optimal Transcoding Resolution Prediction for Efficient Per-Title Bitrate Ladder Estimation
Jan 09, 2024Adaptive video streaming requires efficient bitrate ladder construction to meet heterogeneous network conditions and end-user demands. Per-title optimized encoding typically traverses numerous encoding parameters to search the Pareto-optimal operating points for each video. Recently, researchers have attempted to predict the content-optimized bitrate ladder for pre-encoding overhead reduction. However, existing methods commonly estimate the encoding parameters on the Pareto front and still require subsequent pre-encodings. In this paper, we propose to directly predict the optimal transcoding resolution at each preset bitrate for efficient bitrate ladder construction. We adopt a Temporal Attentive Gated Recurrent Network to capture spatial-temporal features and predict transcoding resolutions as a multi-task classification problem. We demonstrate that content-optimized bitrate ladders can thus be efficiently determined without any pre-encoding. Our method well approximates the ground-truth bitrate-resolution pairs with a slight Bj{\o}ntegaard Delta rate loss of 1.21% and significantly outperforms the state-of-the-art fixed ladder.
Self-Asymmetric Invertible Network for Compression-Aware Image Rescaling
Mar 11, 2023



High-resolution (HR) images are usually downscaled to low-resolution (LR) ones for better display and afterward upscaled back to the original size to recover details. Recent work in image rescaling formulates downscaling and upscaling as a unified task and learns a bijective mapping between HR and LR via invertible networks. However, in real-world applications (e.g., social media), most images are compressed for transmission. Lossy compression will lead to irreversible information loss on LR images, hence damaging the inverse upscaling procedure and degrading the reconstruction accuracy. In this paper, we propose the Self-Asymmetric Invertible Network (SAIN) for compression-aware image rescaling. To tackle the distribution shift, we first develop an end-to-end asymmetric framework with two separate bijective mappings for high-quality and compressed LR images, respectively. Then, based on empirical analysis of this framework, we model the distribution of the lost information (including downscaling and compression) using isotropic Gaussian mixtures and propose the Enhanced Invertible Block to derive high-quality/compressed LR images in one forward pass. Besides, we design a set of losses to regularize the learned LR images and enhance the invertibility. Extensive experiments demonstrate the consistent improvements of SAIN across various image rescaling datasets in terms of both quantitative and qualitative evaluation under standard image compression formats (i.e., JPEG and WebP).
MPASNET: Motion Prior-Aware Siamese Network for Unsupervised Deep Crowd Segmentation in Video Scenes
Jan 21, 2021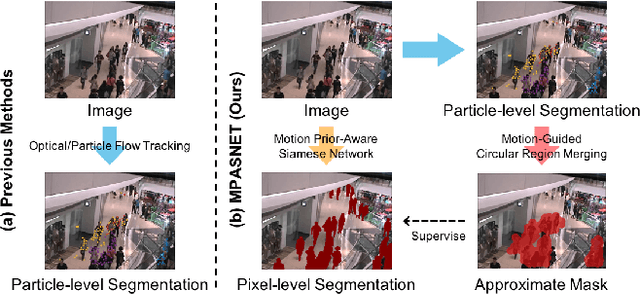
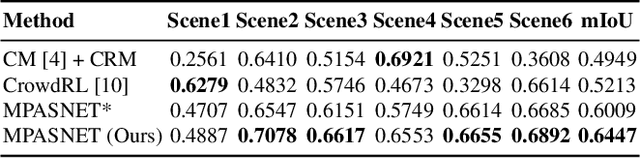
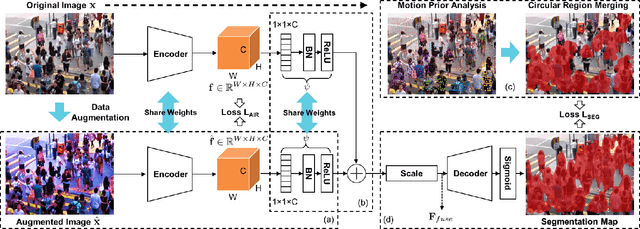
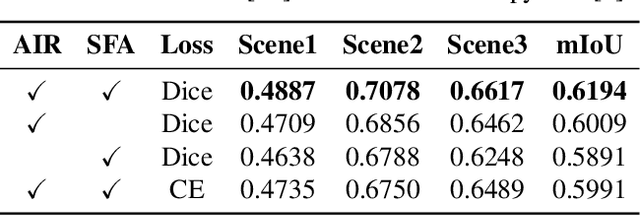
Crowd segmentation is a fundamental task serving as the basis of crowded scene analysis, and it is highly desirable to obtain refined pixel-level segmentation maps. However, it remains a challenging problem, as existing approaches either require dense pixel-level annotations to train deep learning models or merely produce rough segmentation maps from optical or particle flows with physical models. In this paper, we propose the Motion Prior-Aware Siamese Network (MPASNET) for unsupervised crowd semantic segmentation. This model not only eliminates the need for annotation but also yields high-quality segmentation maps. Specially, we first analyze the coherent motion patterns across the frames and then apply a circular region merging strategy on the collective particles to generate pseudo-labels. Moreover, we equip MPASNET with siamese branches for augmentation-invariant regularization and siamese feature aggregation. Experiments over benchmark datasets indicate that our model outperforms the state-of-the-arts by more than 12% in terms of mIoU.
Coarse-to-Fine Pseudo-Labeling Guided Meta-Learning for Inexactly-Supervised Few-Shot Classification
Jul 11, 2020
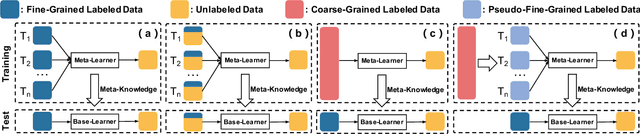
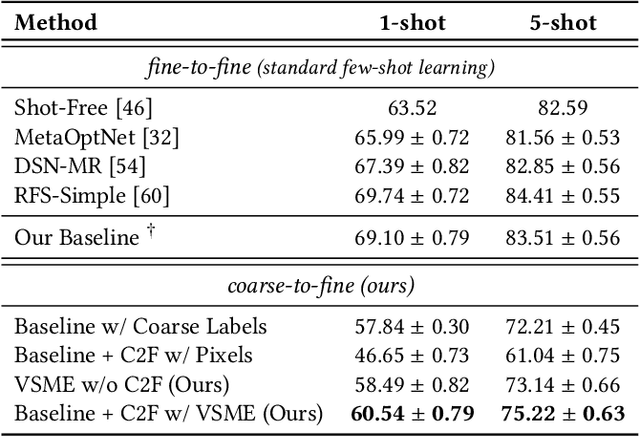
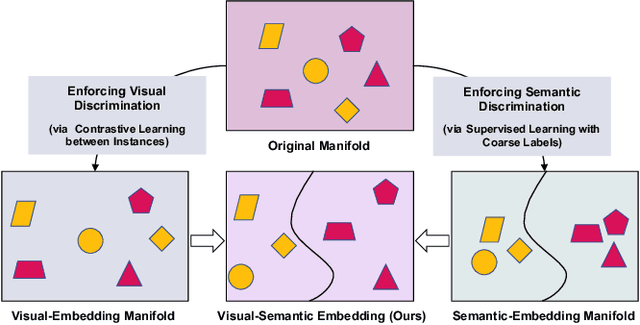
Meta-learning has recently emerged as a promising technique to address the challenge of few-shot learning. However, most existing meta-learning algorithms require fine-grained supervision, thereby involving prohibitive annotation cost. In this paper, we present a new problem named inexactly-supervised meta-learning to alleviate such limitation, focusing on tackling few-shot classification tasks with only coarse-grained supervision. Accordingly, we propose a Coarse-to-Fine (C2F) pseudo-labeling process to construct pseudo-tasks from coarsely-labeled data by grouping each coarse-class into pseudo-fine-classes via similarity matching. Moreover, we develop a Bi-level Discriminative Embedding (BDE) to obtain a good image similarity measure in both visual and semantic aspects with inexact supervision. Experiments across representative benchmarks indicate that our approach shows profound advantages over baseline models.