 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Apr 28, 2025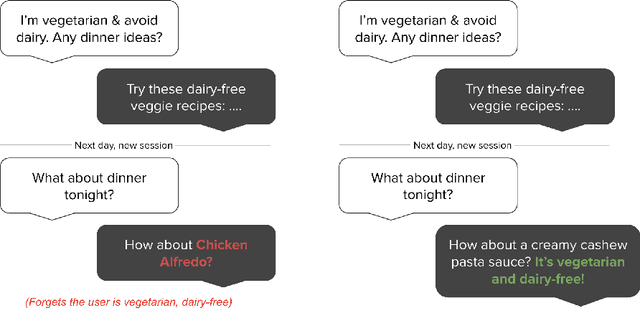
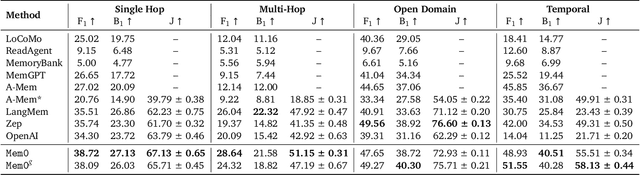
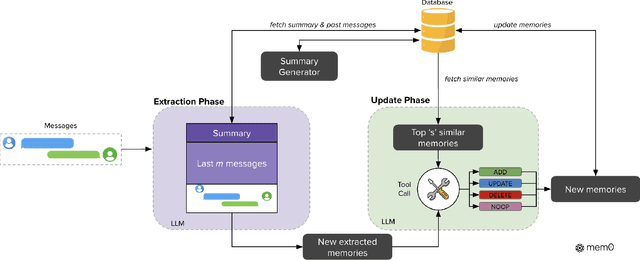
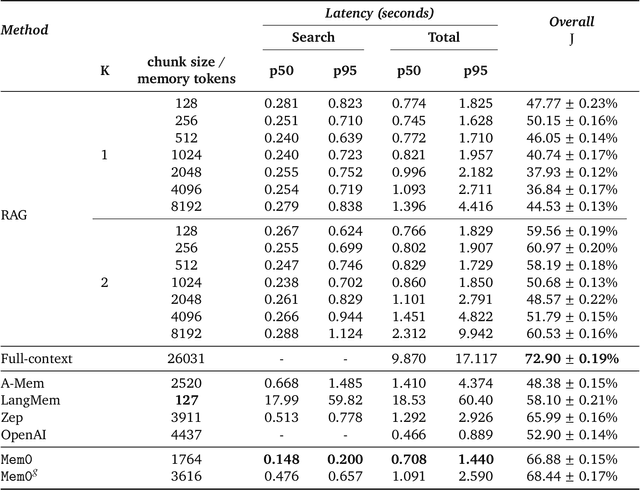
Large Language Models (LLMs) have demonstrated remarkable prowess in generating contextually coherent responses, yet their fixed context windows pose fundamental challenges for maintaining consistency over prolonged multi-session dialogues. We introduce Mem0, a scalable memory-centric architecture that addresses this issue by dynamically extracting, consolidating, and retrieving salient information from ongoing conversations. Building on this foundation, we further propose an enhanced variant that leverages graph-based memory representations to capture complex relational structures among conversational elements. Through comprehensive evaluations on LOCOMO benchmark, we systematically compare our approaches against six baseline categories: (i) established memory-augmented systems, (ii) retrieval-augmented generation (RAG) with varying chunk sizes and k-values, (iii) a full-context approach that processes the entire conversation history, (iv) an open-source memory solution, (v) a proprietary model system, and (vi) a dedicated memory management platform. Empirical results show that our methods consistently outperform all existing memory systems across four question categories: single-hop, temporal, multi-hop, and open-domain. Notably, Mem0 achieves 26% relative improvements in the LLM-as-a-Judge metric over OpenAI, while Mem0 with graph memory achieves around 2% higher overall score than the base configuration. Beyond accuracy gains, we also markedly reduce computational overhead compared to full-context method. In particular, Mem0 attains a 91% lower p95 latency and saves more than 90% token cost, offering a compelling balance between advanced reasoning capabilities and practical deployment constraints. Our findings highlight critical role of structured, persistent memory mechanisms for long-term conversational coherence, paving the way for more reliable and efficient LLM-driven AI agents.
MLLMs Know Where to Look: Training-free Perception of Small Visual Details with Multimodal LLMs
Feb 24, 2025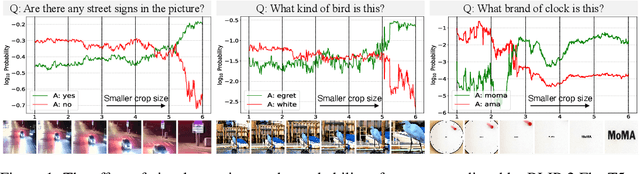
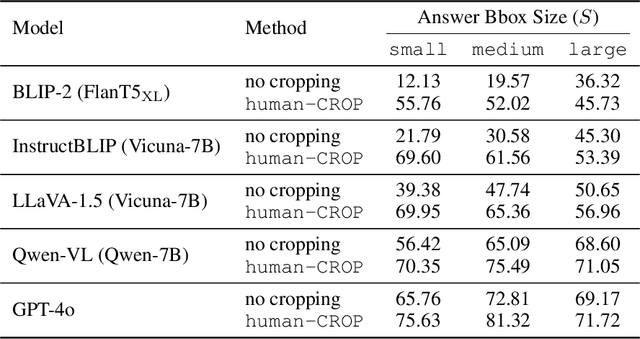
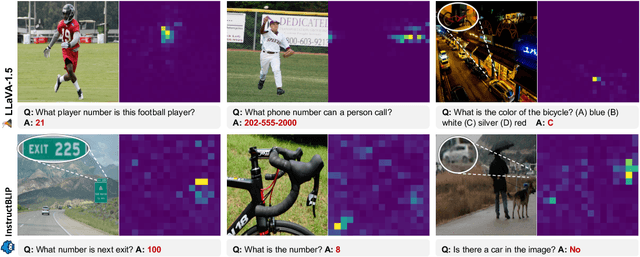
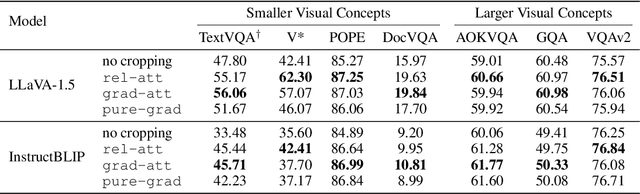
Multimodal Large Language Models (MLLMs) have experienced rapid progress in visual recognition tasks in recent years. Given their potential integration into many critical applications, it is important to understand the limitations of their visual perception. In this work, we study whether MLLMs can perceive small visual details as effectively as large ones when answering questions about images. We observe that their performance is very sensitive to the size of the visual subject of the question, and further show that this effect is in fact causal by conducting an intervention study. Next, we study the attention patterns of MLLMs when answering visual questions, and intriguingly find that they consistently know where to look, even when they provide the wrong answer. Based on these findings, we then propose training-free visual intervention methods that leverage the internal knowledge of any MLLM itself, in the form of attention and gradient maps, to enhance its perception of small visual details. We evaluate our proposed methods on two widely-used MLLMs and seven visual question answering benchmarks and show that they can significantly improve MLLMs' accuracy without requiring any training. Our results elucidate the risk of applying MLLMs to visual recognition tasks concerning small details and indicate that visual intervention using the model's internal state is a promising direction to mitigate this risk.
Visual Cropping Improves Zero-Shot Question Answering of Multimodal Large Language Models
Oct 24, 2023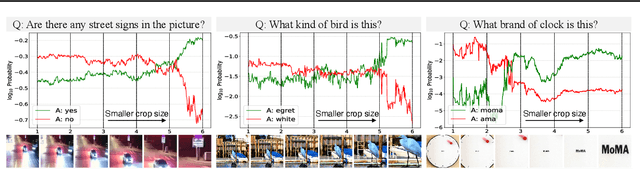

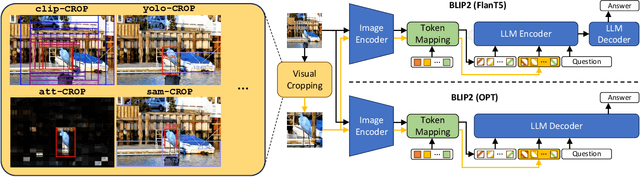
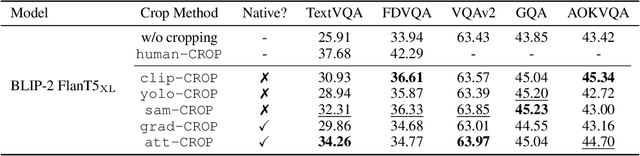
Multimodal Large Language Models (LLMs) have recently achieved promising zero-shot accuracy on visual question answering (VQA) -- a fundamental task affecting various downstream applications and domains. Given the great potential for the broad use of these models, it is important to investigate their limitations in dealing with different image and question properties. In this work, we investigate whether multimodal LLMs can perceive small details as well as large details in images. In particular, we show that their zero-shot accuracy in answering visual questions is very sensitive to the size of the visual subject of the question, declining up to $46\%$ with size. Furthermore, we show that this effect is causal by observing that human visual cropping can significantly mitigate their sensitivity to size. Inspired by the usefulness of human cropping, we then propose three automatic visual cropping methods as inference time mechanisms to improve the zero-shot performance of multimodal LLMs. We study their effectiveness on four popular VQA datasets, and a subset of the VQAv2 dataset tailored towards fine visual details. Our findings suggest that multimodal LLMs should be used with caution in detail-sensitive VQA applications, and that visual cropping is a promising direction to improve their zero-shot performance. Our code and data are publicly available.
FIRE: Food Image to REcipe generation
Aug 28, 2023
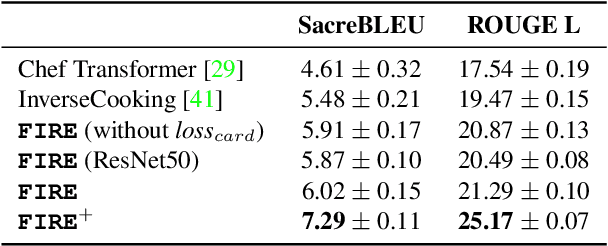
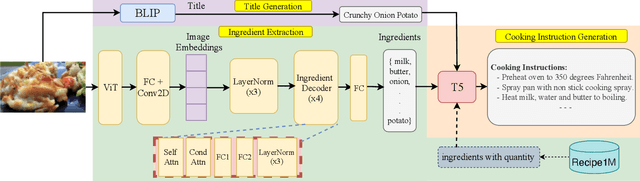
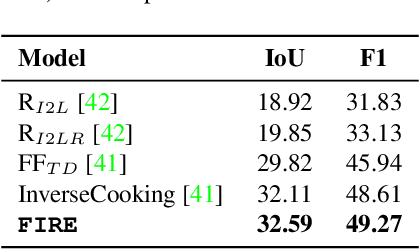
Food computing has emerged as a prominent multidisciplinary field of research in recent years. An ambitious goal of food computing is to develop end-to-end intelligent systems capable of autonomously producing recipe information for a food image. Current image-to-recipe methods are retrieval-based and their success depends heavily on the dataset size and diversity, as well as the quality of learned embeddings. Meanwhile, the emergence of powerful attention-based vision and language models presents a promising avenue for accurate and generalizable recipe generation, which has yet to be extensively explored. This paper proposes FIRE, a novel multimodal methodology tailored to recipe generation in the food computing domain, which generates the food title, ingredients, and cooking instructions based on input food images. FIRE leverages the BLIP model to generate titles, utilizes a Vision Transformer with a decoder for ingredient extraction, and employs the T5 model to generate recipes incorporating titles and ingredients as inputs. We showcase two practical applications that can benefit from integrating FIRE with large language model prompting: recipe customization to fit recipes to user preferences and recipe-to-code transformation to enable automated cooking processes. Our experimental findings validate the efficacy of our proposed approach, underscoring its potential for future advancements and widespread adoption in food computing.
Privacy Aware Question-Answering System for Online Mental Health Risk Assessment
Jun 09, 2023
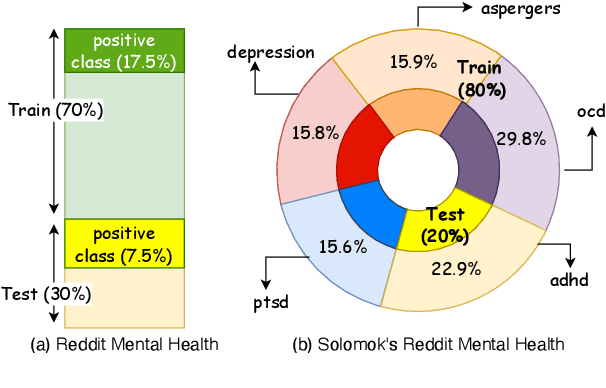
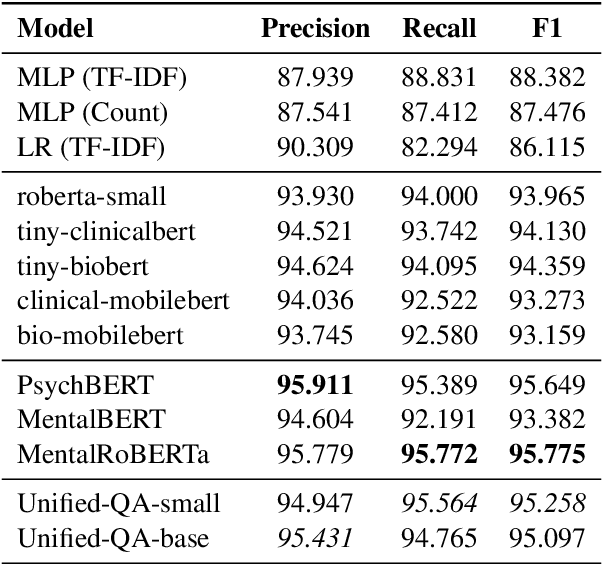
Social media platforms have enabled individuals suffering from mental illnesses to share their lived experiences and find the online support necessary to cope. However, many users fail to receive genuine clinical support, thus exacerbating their symptoms. Screening users based on what they post online can aid providers in administering targeted healthcare and minimize false positives. Pre-trained Language Models (LMs) can assess users' social media data and classify them in terms of their mental health risk. We propose a Question-Answering (QA) approach to assess mental health risk using the Unified-QA model on two large mental health datasets. To protect user data, we extend Unified-QA by anonymizing the model training process using differential privacy. Our results demonstrate the effectiveness of modeling risk assessment as a QA task, specifically for mental health use cases. Furthermore, the model's performance decreases by less than 1% with the inclusion of differential privacy. The proposed system's performance is indicative of a promising research direction that will lead to the development of privacy-aware diagnostic systems.
Using Visual Cropping to Enhance Fine-Detail Question Answering of BLIP-Family Models
May 31, 2023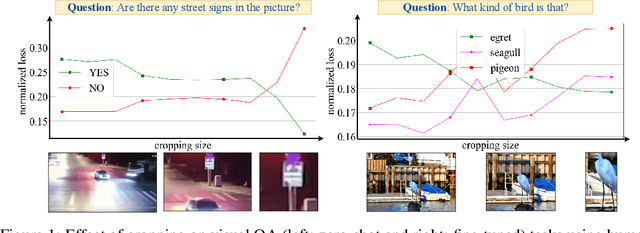
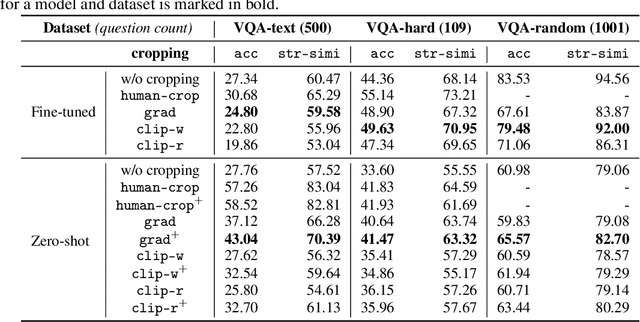
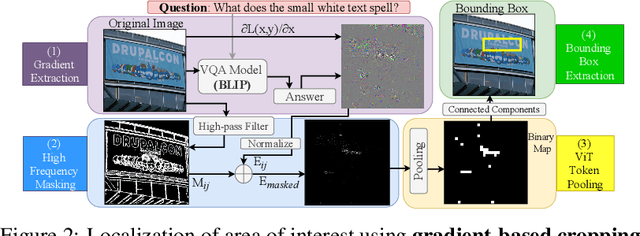
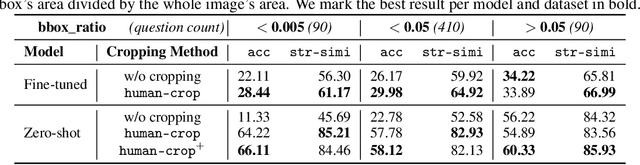
Visual Question Answering is a challenging task, as it requires seamless interaction between perceptual, linguistic, and background knowledge systems. While the recent progress of visual and natural language models like BLIP has led to improved performance on this task, we lack understanding of the ability of such models to perform on different kinds of questions and reasoning types. As our initial analysis of BLIP-family models revealed difficulty with answering fine-detail questions, we investigate the following question: Can visual cropping be employed to improve the performance of state-of-the-art visual question answering models on fine-detail questions? Given the recent success of the BLIP-family models, we study a zero-shot and a fine-tuned BLIP model. We define three controlled subsets of the popular VQA-v2 benchmark to measure whether cropping can help model performance. Besides human cropping, we devise two automatic cropping strategies based on multi-modal embedding by CLIP and BLIP visual QA model gradients. Our experiments demonstrate that the performance of BLIP model variants can be significantly improved through human cropping, and automatic cropping methods can produce comparable benefits. A deeper dive into our findings indicates that the performance enhancement is more pronounced in zero-shot models than in fine-tuned models and more salient with smaller bounding boxes than larger ones. We perform case studies to connect quantitative differences with qualitative observations across question types and datasets. Finally, we see that the cropping enhancement is robust, as we gain an improvement of 4.59% (absolute) in the general VQA-random task by simply inputting a concatenation of the original and gradient-based cropped images. We make our code available to facilitate further innovation on visual cropping methods for question answering.
Knowledge-enhanced Agents for Interactive Text Games
May 08, 2023
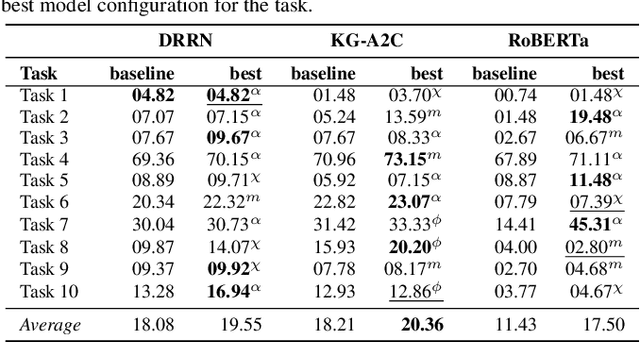
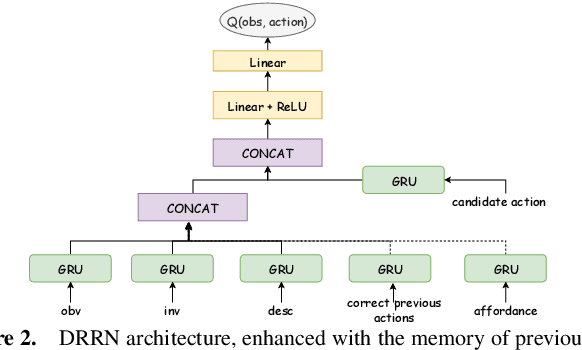
Communication via natural language is a crucial aspect of intelligence, and it requires computational models to learn and reason about world concepts, with varying levels of supervision. While there has been significant progress made on fully-supervised non-interactive tasks, such as question-answering and procedural text understanding, much of the community has turned to various sequential interactive tasks, as in semi-Markov text-based games, which have revealed limitations of existing approaches in terms of coherence, contextual awareness, and their ability to learn effectively from the environment. In this paper, we propose a framework for enabling improved functional grounding of agents in text-based games. Specifically, we consider two forms of domain knowledge that we inject into learning-based agents: memory of previous correct actions and affordances of relevant objects in the environment. Our framework supports three representative model classes: `pure' reinforcement learning (RL) agents, RL agents enhanced with knowledge graphs, and agents equipped with language models. Furthermore, we devise multiple injection strategies for the above domain knowledge types and agent architectures, including injection via knowledge graphs and augmentation of the existing input encoding strategies. We perform all experiments on the ScienceWorld text-based game environment, to illustrate the performance of various model configurations in challenging science-related instruction-following tasks. Our findings provide crucial insights on the development of effective natural language processing systems for interactive contexts.
DIGITOUR: Automatic Digital Tours for Real-Estate Properties
Jan 17, 2023



A virtual or digital tour is a form of virtual reality technology which allows a user to experience a specific location remotely. Currently, these virtual tours are created by following a 2-step strategy. First, a photographer clicks a 360 degree equirectangular image; then, a team of annotators manually links these images for the "walkthrough" user experience. The major challenge in the mass adoption of virtual tours is the time and cost involved in manual annotation/linking of images. Therefore, this paper presents an end-to-end pipeline to automate the generation of 3D virtual tours using equirectangular images for real-estate properties. We propose a novel HSV-based coloring scheme for paper tags that need to be placed at different locations before clicking the equirectangular images using 360 degree cameras. These tags have two characteristics: i) they are numbered to help the photographer for placement of tags in sequence and; ii) bi-colored, which allows better learning of tag detection (using YOLOv5 architecture) in an image and digit recognition (using custom MobileNet architecture) tasks. Finally, we link/connect all the equirectangular images based on detected tags. We show the efficiency of the proposed pipeline on a real-world equirectangular image dataset collected from the Housing.com database.
RE-Tagger: A light-weight Real-Estate Image Classifier
Jul 12, 2022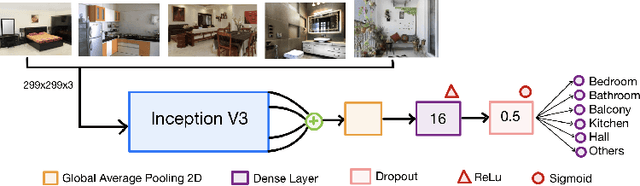

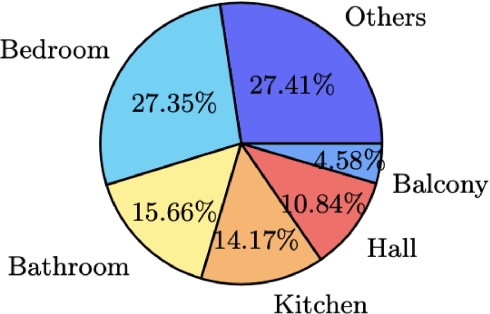

Real-estate image tagging is one of the essential use-cases to save efforts involved in manual annotation and enhance the user experience. This paper proposes an end-to-end pipeline (referred to as RE-Tagger) for the real-estate image classification problem. We present a two-stage transfer learning approach using custom InceptionV3 architecture to classify images into different categories (i.e., bedroom, bathroom, kitchen, balcony, hall, and others). Finally, we released the application as REST API hosted as a web application running on 2 cores machine with 2 GB RAM. The demo video is available here.